We will walk through the encoder-decoder architecture for sequence to sequence model using convolutional layers and attention mechanism. This blog has three main sections explaining Encoder, Attention mechanism and decoder functions.
Encoder:

Encoder Initialization :
Parameters accepted for instantiating the encoder object are input_dim (Input dimension), emb_dim(embedding dimension), hid_dim(Hidden Layer dimension), n_layers(Number of Convolution Layers) , kernel_size(kernal size used for convoluting) , dropout(drop out in decimals), device(Device type to be used) and max_length(maximum length of input sequence)
First, we will check for the kerner size being an odd number. We can divide the kernel size by 2 and make sure that the remainder is equal to 1. For Encoder, the kernel size must be an odd number, whereas for the decoder it could be an odd or even number.
Set the device to the input device passed to the encoder. Set scale value to square root of 0.5 and move it to device. This will be used in convolution layers to prevent overflow.
Instantiate token embedding function using nn.Embedding with input_dim as input and emb_dim as output dimension. Instantiate position embedding function using nn.Embedding with max_length as input and emb_dim as output dimension. Both the token and position embedding will have the same size emb_dim as they will be added together.
Instantiate the embedding to hidden as nn.Linear layer with emb_dim as input size and hid_dim as output size. Instantiate the hidden to embedding as nn.Linear layer with hid_dim as input size and emb_dim as output size.
Instantiate convolution block with the nn.Conv1d layers to match the input parameter n_layers. Instantiate dropout with nn.Dropout layer with input parameter passed to the function.
Encoder Forward :
Parameter accepted is the source(src) tensor.
We will get batch_size from the src tensor using shape function. Index “0” will give the batch size as the first parameter is set in the iterator definition. Source length(src_len) is also from src tensor using shape function. Index “1” will give source length.
Using source length(src_len) , create position tensor that assign numbers 0 to src_len for all the words. Repeat this batch_size times to get the final position tensor(pos). Create embedding for source(src) and position(pos) tensors. Combine the two embeddings by element wise summing. Apply dropout to the result(embedded) as we are building the embedding from scratch.
Pass the embedding through the linear layer to convert from embedding dim to hidden dim. This will result in a tensor of shape [batch size, src len, hid dim]. Switch the 1st and 2nd position tensor values to get the final tensor of size [batchsize, hid dim, src len]. This will be used as input to convolution blocks.
Encoder Convolution block:

For each convolution block, apply dropout to convolution input. Apply GLU activation function to the result. Add the result, convolution input and scale the final result with the scaling factor defined in init function. Assign result to convolution input for next iteration.
After all the convolution layers, switch src len, hid dim dimension values and apply linear transformation to convert the hid dim resulting tensor to embedding dim tensor. The resulting tensor (conved) will have dimension of [batch size, src len, emb dim]
Element Wise sum output (conved) and input (embedded) to be used for attention.
Attention Mechanism :
The attention layer is applied at the end of each convolution block in the decoder.
The attention mechanism accepts the following inputs:
1) encoder’s conved and combined outputs.
2) decoder’s input embedding and GLU activations from the existing conv block.
The decoder’s glu activations are transformed into an embedding of size equal to that of the decoder input embedding. The glu activation embedding and decoder input embedding are then combined and scaled down to prevent explosion of values within the decoder network.
This combined decoder embedding is then multiplied with the encoder’s conved output to form the energy values of the attention mechanism. These energy values are then passed into the softmax function to give the attention weights that specify how important certain source token is with respect to a given decoder prediction.
Attention weights are multiplied with the combined encoder output to give rise to attention encodings that are then transformed into embeddings of size equal to that of the glu activations vector from the current conv block. The combination of these attention encoding vector and glu activations vector is the final output of the attention operation that is applied at the end of each conv block within the decoder.
Decoder

Decoder Initialization :
The Decoder block takes in output_dim(Output Dimensions), emb_dim(Embedding dimensions), hid_dim(Hidden dimensions), n_layers(Number of layers in the decoder Convolution block), kernel_size(Size of the 1D kernel for Convolution), dropout(Dropout Probability), trg_pad_idx(Token index of the Padding token), device(GPU/CPU), max_length(Maximum length of the sequence, used for positional encoder).
We start with setting the kernel size for the convolution operations which are basically filters that slides across the tokens within the sequence to encode the information.After this we set the trg_pad_idx to the pad token value which can be found using vocab.stoi which is a reverse map of words to token. Also we need to set the scale value to the square root of 0.5. This is used to ensure that the variance throughout the network does not change dramatically
Similar to the encoder we now instantiate the token embedding function using nn.Embedding with output_dim as input and emb_dim as output dimension. Similarity we create positional embedding using nn.Embedding with max_lenght(sentence length) as input and emb_dim as output dimension. Similar to the encoder both the token and position embedding will have the same size emb_dim as then will be added together. After this we create the linear layer for converting embedding to hidden representations using nn.Linear layer with emb_dim as input size and hid_dim as output size. We will also need another linear layer for converting hidden representations to embeddings using nn.Linear layer with hid_dim as input size and emb_dim as output size.
Now we will define the Decoder Convolution block. We will create the convolution block with the nn.Conv1d layers and then create multiple layers(equal to n_layers) using the ModuleList. One thing to note, in the decoder block the padding will be a little different than the encoder block as we will only be padding in the beginning(i.e initial positions) , not equally on both sides. In the encoder we padded equally on each side to ensure the length of the sentence stays the same throughout , In decoder we only pad at the beginning of the sentence. As we are processing all of the targets simultaneously in parallel, and not sequentially, we need a method of only allowing the filters translating token i to only look at tokens before word i. If they were allowed to look at token i+1 (the token they should be outputting), the model will simply learn to output the next word in the sequence by directly copying it, without actually learning how to translate.At last we also need to add the dropout layer with nn.Dropout.
Decoder Forward
Now we will define the forward pass for the decoder block. For this we will be using trg(target), encoder_conved(conved output from the encoder) and encoder_combined(Combined output from the encoder) as the parameters.
First we get the batch_size from the trg_tensor using shape function. Index “0” will give the batch size. Similarly we will get target length(trg_len) from trg tensor using shape function. Index “1” will give length.We use target length(trg_len) to create position tensor that assign numbers 0 to trg_len for all the words and then repeat this batch_size times to get the final position tensor.Similarly we get the hid_dim size from the conv_input using shape function later in the code.For that index “1” will give the hidden dimension. After that we create embedding for target(trg) and position(pos) tensors. Now we combine the two embeddings by doing element wise summation and then applying dropout to the result(embedded). Then we pass these embedding through the linear layer to convert from embedding dim to hidden dim. This will result in a tensor of shape [batch size, trg len, hid dim].
After this we Switch the first and second position tensor values to get the final tensor of size [batchsize, hid dim, trg len]. This will be used as input to decoder convolution blocks.
Decoder Convolution block :
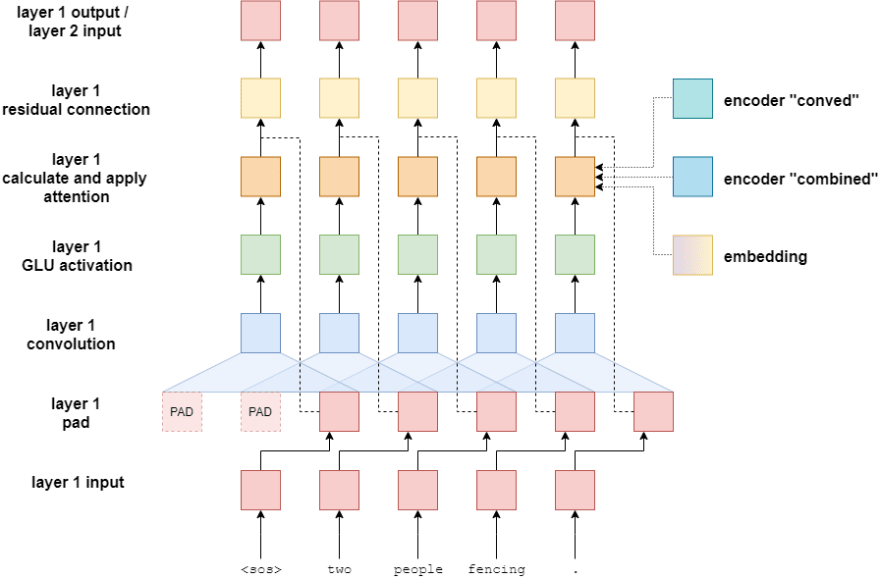
Decoder Convolution block is similar to the Encoder convolution block with some minor changes. Similar to encoder, for each convolution block, apply dropout to conv_input. But in decoder when for padding we will concatenate a zero tensor with the conv_input rather than padding it equally on both sides so that the model can’t cheat and just copy the next word in the sequence.
After this we pass the padded conv_input through the conv block(which is similar to the conv layer in the encoder). The output of this will then be fed to GLU activation function .This is now pass through the attention block along with the embedding, outputs from the encoder i.e encode_conved and encode_combined.We then add the result to convolution input(residual connection) and scale the final result with the scaling factor defined in init function. This becomes the convolution input for the next loop iteration.
Similar to encoder after all the convolution layers, we switch trg_len and hid_dim dimension values and apply linear transformation to convert the hid dim resulting tensor to embedding dim tensor. The resulting tensor (conved) will have dimension of [batch size, trg len, emb dim]. The final output will be fed to a linear layer after applying dropout to the final linear layer(hid2emb) output.
Thanks to Brent Trevett notebook for explaining the intuition behind using convolutional layer for sequence to sequence modelling.

Top comments (0)