Introduction
Recurrent Neural networks (RNN) are a class of artificial neural networks that
are helpful in modelling sequence data. The output from the previous step is fed
as input to the current step and this helps to learn about the dependencies in a
sequential data. They produce predictive results on sequential data that other
algorithms can’t.
Long Short Term Memory (LSTM) and Gated Recurrent Unit (GRU) are two advanced
implementations of RNNs which helps to overcome the problem of vanishing
gradients during back propagation in RNNs.
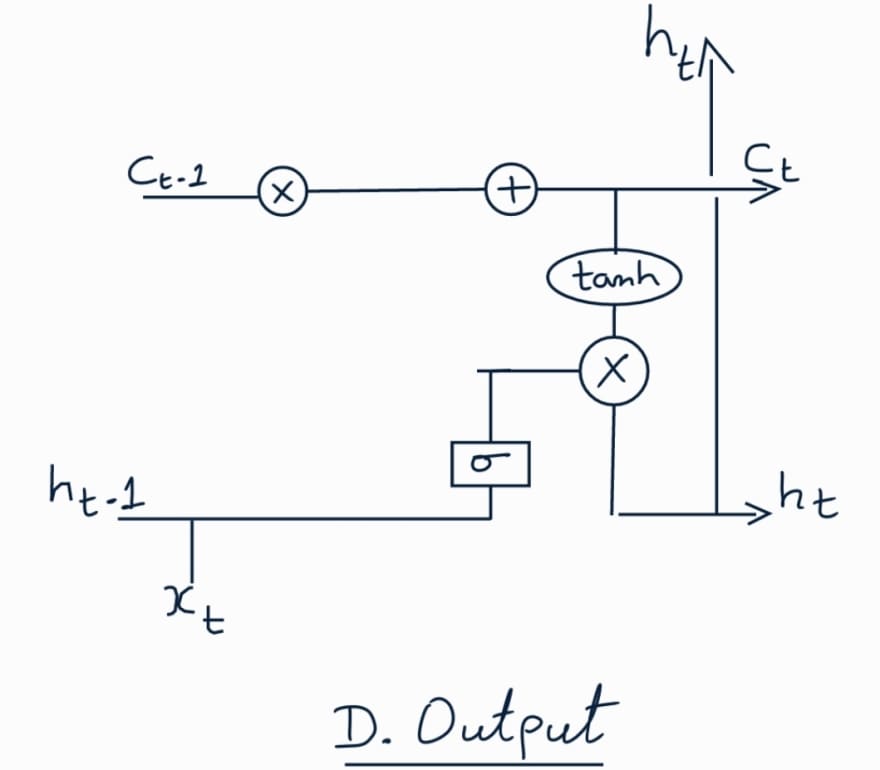
Long Short Term Memory (LSTM)
In LSTM there are four layers instead of just one layer present in a standard
RNN. These layers and the corresponding operations help LSTM to keep or forget
information.
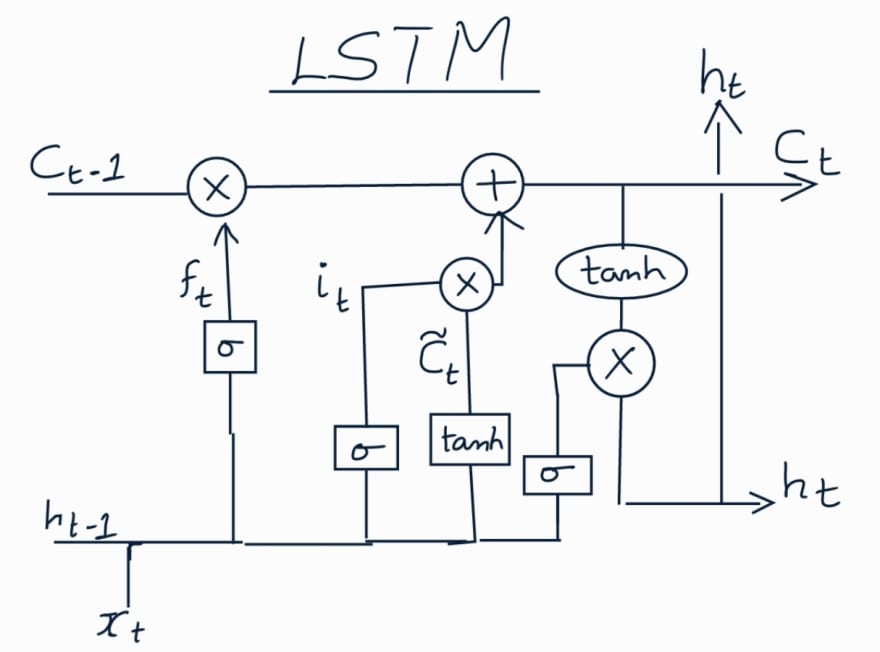
The core concept is the memory cell state (Ct) that runs through the whole
process and helps to keep the required information throughout the processing of
the sequence. The four main processing steps performed in an LSTM cell are as
follows:
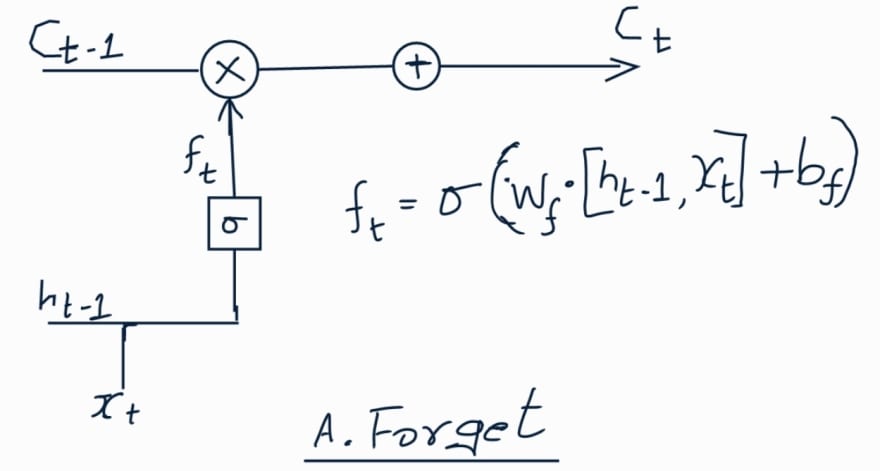
Forget Gate:
In this step as the name suggests the layer decides which information should
be kept or discarded from the cell state. It takes as input concatenation of
the previous hidden state (ht-1) and the current input (xt), passes thru a
sigmoid function to get output between 0 and 1. Closer to 0 mean forget and
closer to 1 mean keep.
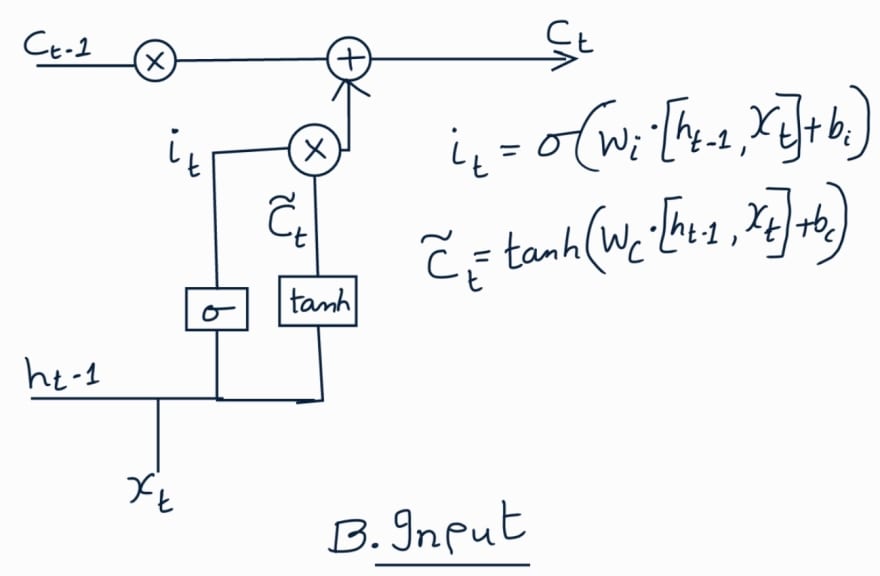
Input Gate:
In this step, we decide on what needs to be updated into cell state. There
are two layers used to achieve this. First the previous hidden state and
current input is passed through a sigmoid function to decide on which values
are important. Second the previous hidden state and current input are passed
thru tanh function to squish the values between -1 and 1. Then we multiply
tanh output with sigmoid output to decide on which information to keep.
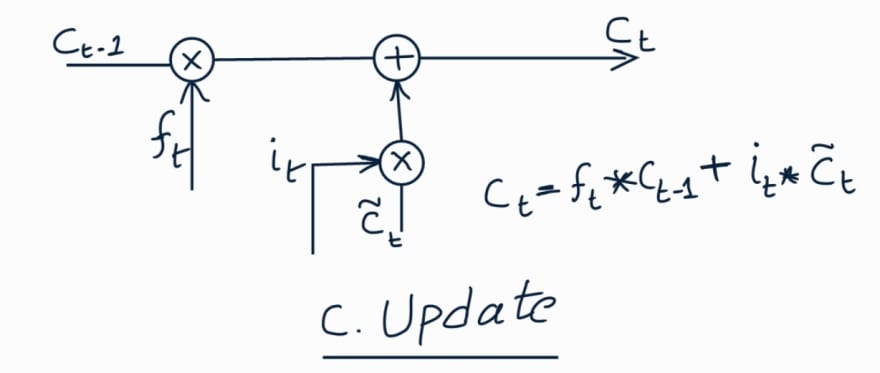
Update Cell State:
In this step, we will calculate the new cell state. First we multiply the
previous cell state with the output from forget gate. Then we add the output
from the input gate to get the new cell state.
Output Gate:
In this step, we calculate the next hidden state. It is also used as output
for predictions. First we pass the previous hidden state and current input
to a sigmoid function. Then we pass the new cell state to a tanh function.
Then we multiply the tanh output with sigmoid output to derive the new
hidden state.
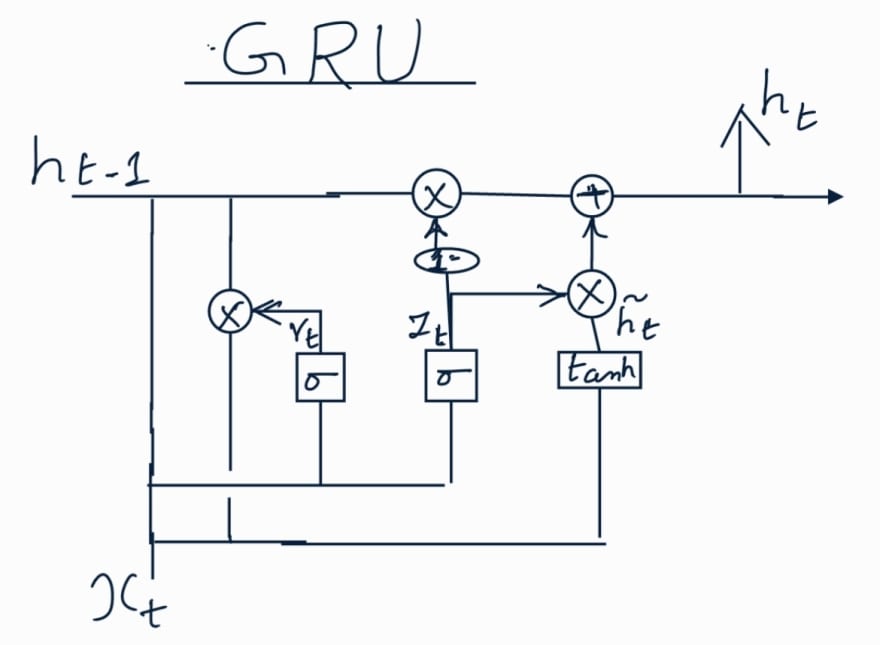
Gated Recurrent Unit (GRU)
GRU is simplified version of LSTM. They don’t have cell state but uses hidden
state to transfer information. They have only two gates instead of 3. Forget and
input gates are combined into a single update gate. Output gate is called Reset
gate as it resets the hidden state.
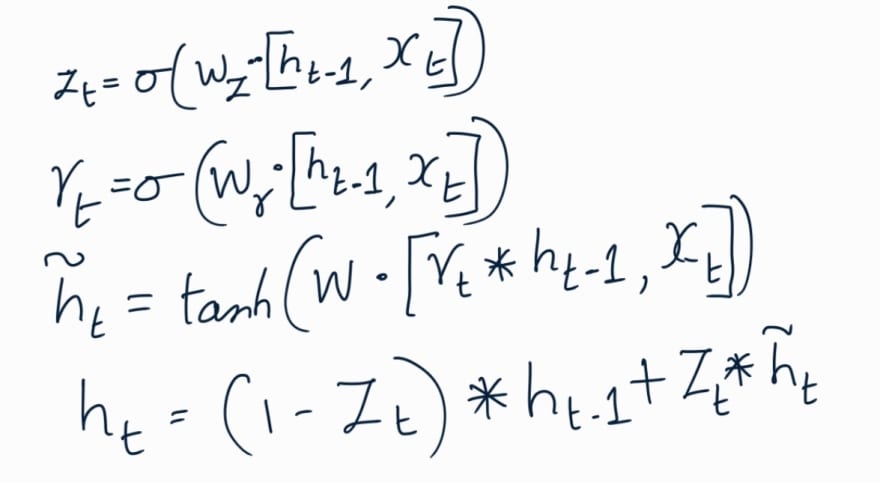
Attention Mechanism
In Seq2Seq RNN models, between the encoder and decoder networks, we introduce an
attention mechanism to help the decoder network to focus on specific areas of
the encoded inputs in each of its time step. Following diagram illustrates this
concept for the first time step.
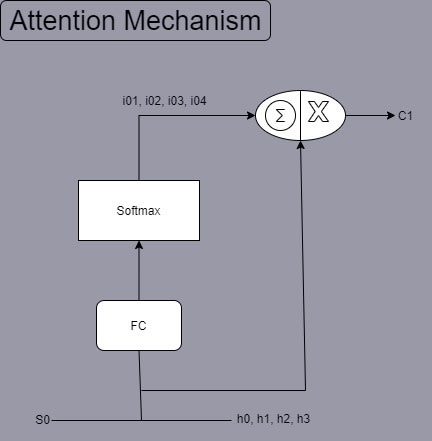
Attention mechanism will learn the attention weights i01, i02, i03 and i04
utilizing a fully connected (FC) layer and a soft max function. It takes input
as the initial state vector S0 of the decoder network and the outputs h0, h1, h2,
h3 from encoder network. The context vector C1 is calculated by doing a sum of
dot product between the hidden states h0, h1, h2 and h3 with the attention
weights i01, i02, i03 and i04 respectively.

Top comments (0)