
On July 9-12, the team TBD took part in the ICFP Contest. It was 50% Serokell: Vlad, Ilona, and Jonn joined forces with Julie, Sergey, and Pavel. In the end, we managed to get 35th place out of 160.
In this article, we will talk about ICFPC, this year’s problem, and our solution for it.
What is ICFPC?
ICFPC is an annual programming contest with a long history. Each year, individuals and teams of unlimited size compete to solve a single problem in 72 hours, with no constraints on the technologies they can use. In addition to the full leaderboard, the contest has Lightning Division – a separate leaderboard for the submissions made in the first 24 hours.
The nature of the problem can’t be predicted in advance. Each year the contest has a new group of organizers (usually it’s the computer science department of this or that university; sometimes it’s organized by firms). The organizers try to play off the past contest themes but also to add something completely new.
In 2014, the problem was to write an AI that plays the game of Pacman, both for Pacman and for ghosts. The twist was that Pacman had to run on the fantasy LISP machine specified in the problem description. And the AI for ghosts ran on the fantasy 8-bit microprocessors. It was not enough to write the AI, we had to implement two compilers as well.
In 2020, the problem statement didn’t have any words in any of the human languages. It was presented as a sequence of messages from space, where aliens show their notation for arithmetic, then for boolean algebra, then for combinatorial calculus, then describe the communication protocol, and finally give a program that, in human terms, is a thin client for the galactic network. The participants deciphered the messages, implemented an emulator to run this “browser”, and discovered, well, spoilers.
Task specification
This year’s task was inspired by an important real-world application. It’s a 2D geometry problem where we are given a stick figure and a polygonal hole, and our goal is to arrange the figure to fit into the hole. All coordinates are integers, and sticks are allowed to stretch a little. In addition, the closer the figure fits the hole’s boundaries, the fewer “dislikes” it gets. Dislikes contribute to the overall team standings.
For more details, see the full problem spec.
At the beginning of the contest, we were given 59 problem instances, ranging from trivial to somewhat intricate.


Three updates to the problem, scheduled for 24, 36, and 48 hours after the start, introduced the system of bonuses. Each problem has one or more spots inside the hole. If the stick figure touches such a spot, this unlocks a bonus in another specified problem instance. The bonuses allow you to bend the rules, for example, make one stick infinitely stretchable or break one stick into two. Some bonus spots are impossible to reach without using another bonus in the first place. So bonus chains potentially can be long or even circular.
At first, these possible bonus chains were neatly organized.
But as updates kept adding more bonus types and more problem instances, they got maybe a little bit too messy.

In addition to the bonus system, the updates included more problem instances, bringing the total number to 132. The new problem instances ranged from somewhat intricate to hellish.

Our solution
We chose Rust and TypeScript stack before the contest, and some of the team practiced a bit beforehand.
We chose this stack because Rust’s automatic safety allows for writing performant code with minimum runtime overhead. Typing JavaScript is crucial to catch errors caused by sleep deprivation and high-velocity coding, and we’ve been using web browsers as the “UI framework” for a while, given their flexibility and high standardisation.
Regarding our solution: it had several components, discussed in detail later. Please note that while some pieces of work didn’t end up in the final submission, it doesn’t mean that we aren’t absolutely grateful for these contributions.
Visualiser
The visualiser was intended from the very beginning as a full-fledged interactive tool. The main purpose of interactivity was to get a sense of the task. What is it like? What are the main obstacles? How can it be approached? We expected to get some ideas for solvers from interacting with it.
The second goal was the Lightning Submission 24 hours into the contest. We hoped that even if we had no decent automated solver by that time, we would have solved at least some problems manually – as we eventually did. This gave us 70th place in the Lightning Division.
We used the Web as our UI toolkit. The visualizer had client-server architecture. Non-trivial logic was implemented in the Rust server. Canvas rendering and user controls were done in vanilla TypeScript. For communication, we used typed JSON messages, with type definitions manually kept in sync between Rust and TypeScript.
The visualiser ended up with a bunch of features.
- A set of constraint highlightings: the sticks crossing the boundary were dashed, too short and too long edges were color-coded, the Goldilocks zones for edge lengths were shown as circles, etc.
- Instruments to select several vertices and then move or rotate them.
- The option to show solutions statistics, load a solution from a file, or submit it right from the UI.
Shakers
Twenty hours into the contest, we didn’t have any good ideas for a fully automated solver. On the other hand, producing the solutions manually in the UI was too cumbersome.
The UI was already organized around selecting multiple vertices and applying a transformation to them. So we thought: “what if we make transformations more complex?” And the generic shaker was born. By the end of the contest, we had implemented ten different shakers.
What a shaker does is: it takes a subset of vertices and, well, shakes it into a new position. Obviously, shakers that work on a subset of vertices won’t yield correct figures, but they are nonetheless helpful to produce human-made solutions quickly. Some of our best final solutions were obtained this way.
Daiquiri and mojito shakers
The idea for these shakers came from manual solving in visualiser. After a couple of moves, there was a long string of tweaking all the vertices to meet the constraints. The purpose was to automate the search of a good solution nearby, to shake the vertices a little into a better position.
The first version, called “daiquiri”, does not optimise for dislikes or bonuses, it does not even consider boundaries – it only cares for edge length constraints. The algorithm gets selected vertices, then goes through their random permutation. For each vertex, it iterates through adjacent edges, and if the edge is too long or too short, moves the edge one step horizontally or vertically towards a better length.
The upgraded version of the same shaker, called “mojito”, takes boundaries into account – if the vertex was in the hole, it should stay in the hole. It does not check if the edge is in the hole, so it still produces invalid solutions sometimes.
Mojito was a helpful tool for manual solving. For example, problem 78 was solved by a combination of manual changes and mojito.
First, the crab is mostly out of the hole:

It was manually turned upside down and crammed into the hole. A lot of red and purple sticks do not satisfy the constraints:
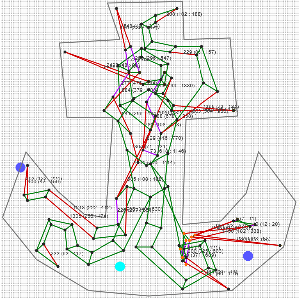
After mojito, all edges satisfy the length condition, although some got out of the hole.
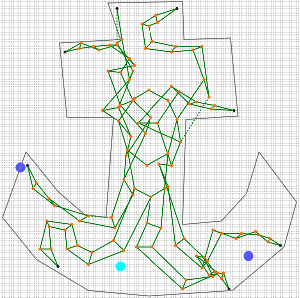
Now some parts can be moved and mojito-ed to obtain a better score.
Greedy and threshold shakers
Turning an invalid pose into a valid one is not trivial. It’s much easier to start with a valid pose and see how far we can improve it without breaking validity. And that was the idea behind greedy shaker. Besides preserving validity, it is guaranteed not to increase dislikes.
The algorithm is simple: first, we move each vertex to its best scoring valid position, and keep doing it until the score can no longer be improved. Then, we randomly move some vertices to new valid positions, even if it doesn’t change the score. This second step shakes up “internal” vertices, hopefully creating more space for “corner” vertices to move. Rinse and repeat.
The next validity preserving shaker implemented the threshold acceptance algorithm (a simpler version of simulated annealing) – i.e.: randomly move vertices to new valid positions, even if doing so increases dislikes, based on a threshold function.
Because we hadn’t implemented any higher-level pose transformations, the threshold shaker, being limited to moving vertices one by one, didn’t seem very useful at the time. Thus, almost no time was spent tuning the threshold function, which may have resulted in some wasted iterations.
Yet it was still capable of finding improved solutions.
Solvers
With more than one hundred problem instances, it didn’t look like we could get by with manually creating solutions in the visualizer. We made several attempts at fully automated solvers.
A solver code-named “rail”
The purpose of this algorithm is to produce any solutions that satisfy all the constraints. It does not attempt to explicitly minimize dislikes. Instead, it produces a stream of random solutions and picks the best one.
A single run of the algorithm looks like this. We place vertices one by one. We never move a vertex after it’s placed. And we only place a vertex if all its edges to already placed vertices satisfy geometric constraints. When all vertices are placed, we evaluate the result and see if it’s an improvement over anything found so far. When the next vertex can’t be placed at all, we are in a dead end, and the process restarts from the beginning.
There are two choices that govern this process.
First, when placing a vertex, which location among the ones satisfying the constraints do we choose? We just pick a random one for simplicity.
Second, in what order do we place the vertices? Here, we take the heuristic commonly used in backtracking algorithms and constraint solving. At each step, we pick a vertex that has the smallest set of allowed locations. Informally, if the vertex has two allowed locations, we’ll guess correctly with a probability of 50%, and if the vertex has 100 possible locations, the chances are 1%, so it’s better to take a 50% chance. In practice, this means that the most demanding constraints are explored and satisfied first. For example, if we already placed two vertices of a rigid triangle, we will place the third one immediately. This, in turn, allows quickly propagating other constraints and determining if the solution is viable.
Sergey’s multishaker solver
Even though “rail” got us out of the bottom of the score sheet and put us into the middle of the field, many solutions had room for improvement.
The process of manually applying different shakers in the visualizer to escape local minima served as an inspiration.
Sergey figured that we should work with what we have and composed several shakers into an automatic solver, dubbed multishaker. The idea behind multishaker was to use mojito to try and transform the initial figure into a valid pose to which greedy and threshold shakers could then be applied.
As the first step, all out-of-bounds vertices and edges were moved inside the hole, followed by mojito shaking the pose. This was done repeatedly until a valid pose was obtained. In most cases the process converged quickly, though sometimes it didn’t converge at all.
It also tended to work better the fewer vertices had to be moved into the hole. This is because we moved them one by one without regard to edge constraints. Consider problem 126.

In this extreme case, the initial pose was being destroyed completely and the task of satisfying edge constraints was left entirely to mojito, even though the initial pose was already valid with respect to edge lengths! The quick and dirty fix was to shift the entire initial pose first so that its center of mass would coincide with the hole’s center of mass.
Once a valid pose had been obtained, multishaker would alternate between greedy and threshold shaker in an infinite loop. Whenever an improved solution was found it was submitted automatically.
This bumped us from ~60th place to 36th.
An attempt to make use of bonuses
If we ignore bonuses, all problem instances are independent, and of all solutions for each problem instance, we are only interested in one that minimizes the number of dislikes.
Things get more complicated if we take bonuses into consideration. Now, there are three dimensions to evaluate a solution on: number of dislikes (the fewer, the better), which bonus spots does it grab (the more, the better), and which bonuses does it rely upon to be valid (the fewer, the better). All solutions below the Pareto frontier can be discarded as inferior, but it still leaves us with more than one candidate for each problem instance.
That is, if we manage to come up with the candidates in the first place. We made changes to the rail solver to take into account which bonus spots the solution grabs and also to make use of the SUPERFLEX bonus which allowed one edge to stretch without limit. This was the easiest bonus to support in the solver.
Running this modified solver on all problems, we amassed a collection of candidates.
As a final ingredient, we needed a global optimizer that will choose candidate solutions for all problem instances together. This would allow sacrificing dislikes in one problem instance in order to grab a bonus that will save more dislikes in another problem instance.
Unfortunately, we failed to do this before the contest deadline. So all this bonus work was in vain. And it temporarily tanked our standings because we were submitting non-optimal solutions. Luckily, we had a fallback plan.
Ilona’s submission decider
Closer to the end of the contest, we realized that we needed a failsafe in case our attempts to globally optimize for bonuses went nowhere: a ‘big red button’ that would resubmit our historical best for each problem. Submitting poses that use bonuses naturally led to non-optimal scores until the bonus cycle was complete, especially with our imperfect solvers. So it was crucial to have a fallback plan.
The infrastructure part of the team completed this entry point with hours to spare.
In the end, it:
- Skipped poses that used any bonuses. The reasoning behind this was that bonuses formed chains. If the pose that unlocked the bonus used in this high-scoring solution would be overwritten because some other score was higher (lower), we didn’t want to get stuck with an invalidated pose.
- Did not bother resubmitting for problems where the high score was already achieved to avoid clogging up the submission pipeline.
The last few minutes were tense, as the decider and the solvers running on the last few select problems were fighting for submission cooldown, but we managed to pull everything through – including the clutch last-minute manual submission for #90 that brought us from 36 to 35!
What we could have done better
Solution DB
In order to pick the best solution for each problem instance in the end, problems of this kind naturally call for a solution database that can be populated by different solvers running on different machines.
This year, we decided to cut corners and piggyback on the contest infrastructure. The contest website provides the submission history, so we thought we could use it as a poor man’s substitute for the solution database. This approach kind of worked, but all in all we consider it a failed experiment.
The system enforced a 5-minute delay between submissions for the same problem instance. Let’s say we run a solver, and it finds a solution in 10 seconds and submits it. Then it keeps running and in another 10 seconds finds an improvement. It has to wait 290 seconds before it can submit this improvement. We can’t stop it before that because otherwise the improvement will be lost.
Another inconvenience is that the contest system provided an API for submitting solutions but not for accessing the submission history. In order to access the history programmatically, we had to scrape HTML pages intended for humans.
And to ensure availability and to avoid unnecessarily burdening the contest server, we ended up creating a local solution cache anyway.
It would have been better if we had set up a proper DB from the beginning.
Programming language
The choice of the right language caused heated debates after the end of the contest.
- Should we reconcile with the steep learning curve, sad compilation times, and
usize as i32 as usizeceremony for the sake of performance, reliability, and handy type hints – and stick with Rust? - Should we trade performance and static typing for coding productivity and better libraries – and switch to Python?
- Should we chase performance and productivity both and get into a double trouble of prototyping in Python and rewriting in C++, and gluing them into one monstrosity, as we did in some previous contests?
- Should we opt for a shiny fancy language that will attract more participants?
- Should we descend into the chaos of polyglot development – and let everyone choose their own language?
- Should we kill all the dispute by choosing some esoteric language no one has heard of – say, Zig? (No, Pharo. Or Gleam? Are we getting into a new heated debate?)
We genuinely don’t know what we will use next year (though, of course, it will be Rust).
GUI toolkit
We chose Web UI because it’s cross-platform, has great debugging tools, and can be as low- or high- level as needed.
However, the client-server separation and the HTTP model mean that even a tiny UI feature takes annoyingly many steps to implement:
- Define request and response types (both in Rust and in TypeScript).
- Update elements on the static HTML pages.
- Update the TypeScript code, possibly in multiple places.
- Add a route in the Rust web server.
- Add actual feature implementation in Rust.
Can we keep the benefits while somehow mitigating the drawbacks? We don’t know yet.
Our awesome team members
Here’s everyone that participated in the contest in the team TBD this year. We would like to thank all of them for the time well spent and their input! Vlad, Jonn, Julie, Sergey and Ilona also contributed to help this article happen.
- Vlad. Advocating for Rust, unproductively obsessing over everything, computational geometry, “rail” solver, an attempt to use bonuses.
- Ilona. UI features, contest Web UI scraping, and the fallback submitter.
- Pavel. Algorithms, spring shaker, and work on a spring-like solution.
- Jonn. Contributing to the visualiser, solver operations, community management and outreach.
- Sergey. Greedy and threshold shakers, the multishaker solver.
- Julie. Visualiser. Some of the shakers. Keeping our rules implementation up to date with changing requirements (bonuses).
And that’s it
In the end, we got 35th place.
If you want to browse our source code, here’s the repository.
By the way, some of the more active people on the contest Discord made a Discord server called Intermediate Competitive but Friendly Programming Club, where multi-team practice will be organized. You are welcome to join.
See you next year! 👋

Top comments (0)