Kubernetes: Evicted pods and Pods Quality of Service

We have a Kubernetes cluster running on AWS Elastic Kubernetes Service.
In this cluster, we have an application which is usually working fine but sometimes our monitoring system notifies about unhealthy pods:

Check pods:
$ kk -n eks-prod-1-web-projectname-admin-backend-ns get pod
NAME READY STATUS RESTARTS AGE
bttrm-web-projectname-admin-backend-64648597fc-9j29n 1/1 Running 0 43m
bttrm-web-projectname-admin-backend-64648597fc-kptjj 1/1 Running 0 43m
bttrm-web-projectname-admin-backend-7f4b5bdb4c-wlbjf 0/1 Evicted 0 12d
bttrm-web-projectname-admin-backend-8478d778f9–5mrnc 0/1 Evicted 0 15d
Here we can see that two pods are in the Evicted status — let’s go to see what is going on.
Kubernetes requests and limits
So, in Kubernetes, we can limit resources used by our applications in two ways — with requests and limits:
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 100m
memory: 100Mi
Here:
-
requests: is used by the Kubernetes Scheduler to chose a WokerNode to place a pod on depending on the values of the request - a node has to have free resources enough to run this pod on it -
limits: such a "hard-limit" - maximum value for a resource that can be used by a pod
Kubernetes pods QoS classes
Documentation — Configure Quality of Service for Pods.
Pods in Kubernetes can be in one of three Quality of Service (QoS) classes:
- Guaranteed: pods, which have and requests, and limits, and they all are the same for all containers in a pod
- Burstable: non-guaranteed pods that have at least or CPU or memory requests set for at least one container
- Best effort: pods without requests and limits at all
You can check your pod’s QoS class with describe pod -o yaml:
$ kubectl get pod appname-54545944b4-h8gmv -o yaml
…
resources:
requests:
cpu: 100m
…
qosClass: Burstable
…
Here we have requests for CPU only, thus such a pod will be under the Burstable QoS class.
Now, let’s go to see how QoS classes impact on the lives of pods.
Node tolerations
When a Kubernetes WorkerNode in a cluster starts lacks available resources — memory, disc, CPU, etc — a cluster’s scheduler at first stops adding new pods on such a node.
Also, Kubernetes adds special annotations to such a node describing its status, for example — node.kubernetes.io/memory-pressure.
See the full list here — Taint based Evictions.
In such a case, kubelet on such a node will start killing running containers and their pods will be in the Failed status.
For example, if a node’s hard disk exhausted — then kubelet will start deleting unused pods and their containers, and then - will delete all unused images.
If this will be not enough — then it will start killing (actually — Evict ) users pods in the following order:
- Best Effort — pods without requests and limits ant all
- Burstable — pods, using more resources the is set in their request
- Burstable — pods, used fewer resources the is set in their request
Guaranteed pods, in general, must not be affected at all, but in case if a node have nothing more to remove and it still needs for resources — kubelet will start removing such pods as well, even if they are under the Guaranteed QoS class.
To find a real reason why a pod was evicted you can check its events.
Going back to our pods now:
$ kk -n eks-prod-1-web-projectname-admin-backend-ns get pod
NAME READY STATUS RESTARTS AGE
…
bttrm-web-projectname-admin-backend-7f4b5bdb4c-wlbjf 0/1 Evicted 0 14d
bttrm-web-projectname-admin-backend-8478d778f9–5mrnc 0/1 Evicted 0 17d
And their events:
$ kk -n eks-prod-1-web-projectname-admin-backend-ns get pod bttrm-web-projectname-admin-backend-7f4b5bdb4c-wlbjf -o yaml
…
status:
message: ‘The node was low on resource: memory. Container bttrm-web-projectname-admin-backend was using 1014836Ki, which exceeds its request of 300Mi. ‘
phase: Failed
reason: Evicted
Here Kubernetes tell us that “ Container was using 1014836Ki, which exceeds its request of 300Mi ”.
Here Ki == kibibyte (1024 bytes, 8192 bits), а Mi — mebibyte, т.е. 1024 kibibytes, или 1048576 bytes.
Let’s convert 1014836Ki to megabytes:
$ echo 1014836/1024 | bc
991
Almost gigabyte of the node’s RAM.
And let’s check again resources specified in the Deployment of this pod:
$ kk -n eks-prod-1-web-projectname-admin-backend-ns get deploy bttrm-web-projectname-admin-backend -o yaml
…
resources:
limits:
memory: 3Gi
requests:
cpu: 100
memory: 300Mi
…
So, as here we have no CPU limits, also limits and requests for CPU and memory are not equal — then it has QoS Burstable class. Also, this node had no other pods running so Kubernetes killed that one.
Grafana’s graphs can show us the whole picture — check the pod’s statuses history (see the Kubernetes: a cluster’s monitoring with the Prometheus Operator post):
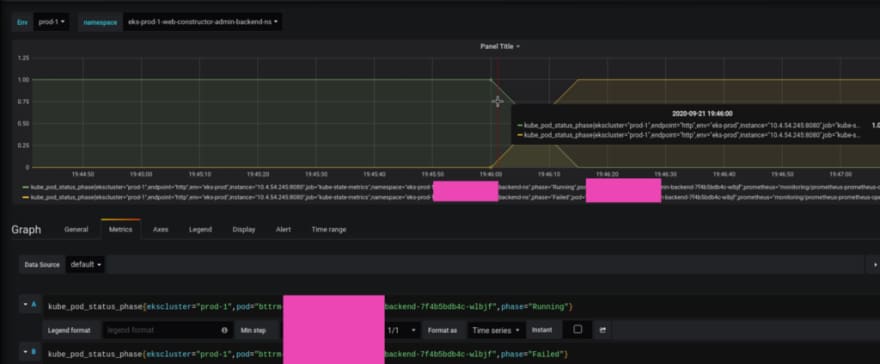
So the pod was working on the 10.4.44.215 WorkerNode in the Running state, but then at 19:40, it was killed.
Let’s check the WorkerNode 10.4.44.215 in this time:

The node has memory exhausted (AWS EC2 t3.medium, 4GB RAM) and kubelet started removing pods.
And let’s see on the pod’s resources used:

Actually, we can see that the pod got some incoming traffic and started consuming a lot of memory.
The memory on the node ended and kubelet killed that pod.
The following question is to developers — or this is expected, and I need to move the application to nodes with more memory available, or they have some memory leaks in the application — and developers will have to fix it.
Useful links
- Resource Quotas
- Configure Quality of Service for Pods
- Assign Memory Resources to Containers and Pods
- Understanding resource limits in kubernetes: memory
Originally published at RTFM: Linux, DevOps, and system administration.

Top comments (0)