
As we have discussed MongoDB basics (link).
Now, let's explore the MongoDB Pipeline concept 🔎
Why MongoDB Pipeline? 🤔
The input of the pipeline can be one or several collections. The pipeline then performs a transformation on the data until our expected result is achieved.
With the help of a pipeline, we can break down a complex query into simple stages, in each of which we can execute the different operations on the data. This also helps us in checking whether our query is functioning properly at each stage by examining both its input and output as the output of each stage will be the input of the next stage.
Below is an illustrated example of a pipeline:

Aggregation
Aggregate operations process data records and return the computed result. Aggregate operations can perform many operations on the grouped data to return a single result.
The Syntax for aggregate: db.CollectionName.aggregate(operation)
Now, if you want to display count, then you will use the following aggregate() method:

Here, We have grouped the documents by type field and on each occurrence of a type field, the value of sum will be increased.
Equivalent SQL Query for this will be:
select type, count(*) from ProductCatalog group by type

Pipeline
MongoDB supports the pipeline concept in the aggregation framework in which we execute an operation on some input and use the output as input for the next command and so on.
There is a set of stages and they are taken as the set of documents as input and produces a resulting set of document. This can be used as an input for the next stage and so on.
Following are the stages in the aggregation framework:
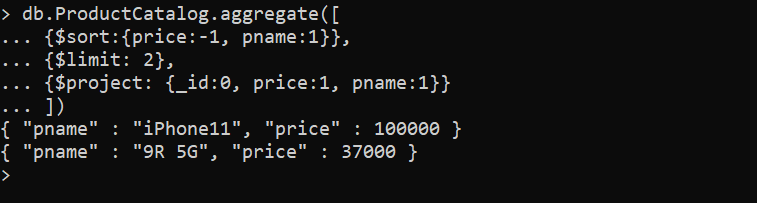
$project: Used to select the specific field from the collection.
$match: It's a filtering operation. Equivalent to where clause in RDBMS.
$group: This groups the document.
$sort: Sorts the document.
$limit: Used to limit the documents in the output

Thank you!! Feel free to comment on any type of feedback or error you have 😄✌

Top comments (0)