For more content like this subscribe to the ShiftMag newsletter.
The task at hand was to migrate from the AWS relational PostgreSQL database to our on-prem self-hosted solution. We assembled a mission-based team comprising a Developer, DevOps, and two DBAs.
The main driver of this migration was the steadily increasing monthly bill we got from AWS. If you don’t read all the fine print when navigating through AWS UI, you could be unpleasantly surprised by the amount of dollars you end up spending.
But, we chose AWS for a valid reason. We had a POC (Proof Of Concept) and wanted to quickly gather customer feedback.
We chose PostgreSQL at that time and opted for an “enhanced” Aurora version. Although we had an on-premise (in-house) solution, it was never battle-tested.
From there, our journey began…
Choose your technologies carefully
Our cluster was AWS Aurora PostgreSQL RDS with one writer and 4 standby servers. The servers were db.r5.8xlarge instances with 32 vCPU and 256 GB RAM with Aurora storage.
The storage solution provides almost instant (approx. 20 ms) replication, with 4 out of 6 commit quorum.
All servers use the same underlying storage, so commits from writers are propagated instantly to standbys, and asynchronous replication updates only the data in memory (shared buffers).
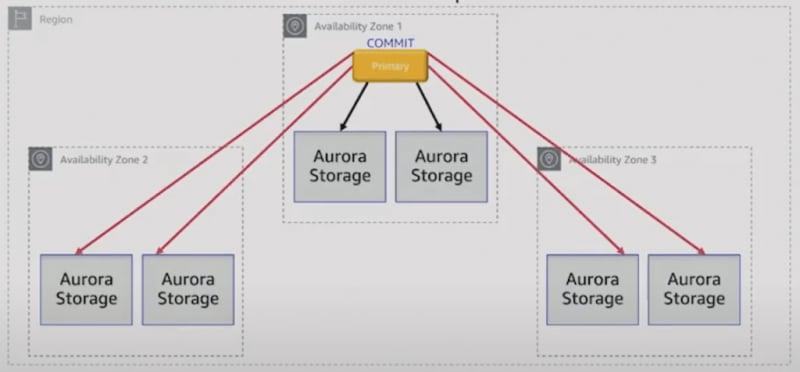
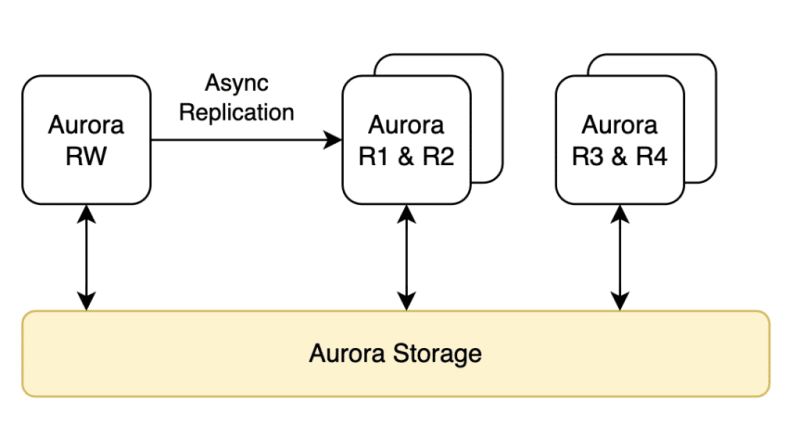
Reference from AWS PostgreSQL In-Depth Training.
So we had help from the beginning…
Replication was instant, so we hooked up the whole UI on our standby servers and got an immediate real-time response. Our solution was built on the assumption that changes from the writer server will be, nearly instantly, available to our standbys.
The writer server was offloaded by efficiently using the standbys. We used Enhanced monitoring, set up Cloud Watch dashboards, analyzed and tracked every query on Performance Insight, and created alarms for every anomaly spotted in the setup.
The level of observability and monitoring let us diagnose issues very quickly and correctly. Little did we know that that behavior differed widely from Vanilla Postgres. But we would find out soon enough.
Think about your data early
Our database DDL was structured to support the product launch and was never meant to be a long-term solution.
Data was added but never deleted. Tables were not partitioned, and indexes have metastasized with various workloads. This resulted in tables with terabytes and indexes with hundreds of gigabytes of size.
We had to restructure. Keep the traffic data together and distinguish it from read-only and configuration data.
Archiving was a very long and IO-intensive feature to develop, and it clashed with the migration efforts. During the product lifecycle, we had stale and test data we wanted to get rid of. We started data cleanup and removed gigabytes of data.
Again conflicting with the migration process.
AWS charges everything
We didn’t start with a huge cluster, but with time and feature development, user adoption, and traffic increase, we had proportional demands on our underlying DB hardware.
Fast forward to being approx. 4-5 years on the market, in production, we had huge I/O usages of our standbys. UI was sucking in two standbys, and their usage was through the roof in peak traffic hours, while the other standbys were battling the remaining read queries.
We also hooked up some analytic reports on one of the servers to provide better statistics for our users.
The monthly bill was rising steadily. Although we neglected costs apart from instance uptime, every I/O request had its price and so did our setup.
On-premise setup
Although our cluster was not tested with the same traffic AWS was handling at the moment, our setup was powerful.
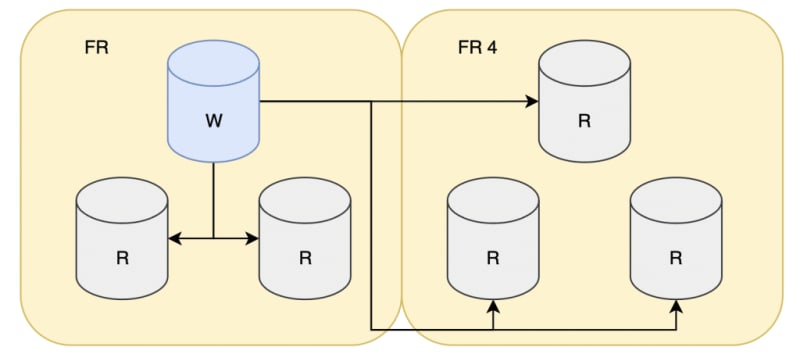
We had complete data center redundancy, meaning if a whole DC crashes, we could failover to the other one. Each DC had servers spread across three availability zones, so redundancy on the network level was also covered. Cluster orchestration with Patroni allowed for smooth failovers/switchovers and performing upgrades without downtime or maintenance window scheduling.
Hardware-wise, we had Intel’s Platinum CPUs, a few generations better than we had provisioned on AWS. Storage was NVMe SSDs, so IO bottlenecks we had on AWS should be history.
Use your standbys with caution
PostgreSQL allows you to use standby servers in a variety of ways:
- High availability where the standbys’ primary purpose is not to fall back from the writer and to replay WAL logs availability
- Offloading big queries, AKA poor men’s data warehousing
- Horizontal scaling, performing select queries to off-load the writer database
Every setup comes with its pros and cons, leading to streaming replication conflicts. We needed to choose whether we preferred replication changes or serving the current queries running on the standby(s).
While the abilities of configuration are broad, they are not bulletproof. The development mindset had to change, since we were now dealing with streaming replication instead of the one provided by Aurora (which was almost completely synchronous without latency increase).
Applications using standbys need to cope with *eventual consistency. * UI architecture for displaying real-time data from standbys in the new setup became an oxymoron from a logical perspective.
Limitations of logical replication
Logical replication was used to transfer data from the current cluster to AWS. We had previous experience migrating data but on a completely different DDL layout (remember the portion of the text “Think about your data early“).
The replication process has two phases. Initial data sync , where all the data currently in the table/schema is migrated, and the “catch-up” phase where the cluster syncs the subsequent changes from WAL logs.
Since logical replication does not copy DDL changes to the target server, all changes were frozen for other developers working on the product.
Our efforts were primarily aimed at reducing the cost , but we’ve managed to give ourselves some extra work in order to bring more value and earnings to the product.
The migration started by introducing replication slots on the source (AWS cluster) and subscribers on the target (on-premise). The first strategy, empirically, was to define one replication slot per database schema, as we did in our previous migration(s). Smaller schemas, up to 50 GB in size, were synced extremely fast and we experienced no issues.
Incidents from database degradations
By the time we got to our main schema counting several TB of size, the first incident happened. During the initial sync phase, WAL logs with subsequent changes are kept on the primary server. Given the way PostgreSQL provides transaction isolation, initial sync is thought of as a long-running transaction on the primary instance.
The snapshot xmin value is held and with it the event horizon. When this value is locked all queries “see” the DB state from the moment the transaction with xmin value started. In layman’s terms, every query has to start the execution from the snapshot of the DB that it was in at the moment of the ongoing transaction and go through changes (tuple versions) applied in the meantime.
This results in prolonged query cost, inaccurate database statistics, and the most problematic one bloating of the database since the vacuum is postponed. Approximately 5-6 hours in the replication we experienced complete degradation. IOPS got exhausted and we hit AWS limits, for our database instance level. We had to stop the replication, lose all the data currently migrated, and start over.
On the second attempt, armed with the experience we had from the first execution, we first divided our replication slots inside the schemas. Tables small in size were merged into a single replication slot, and every other table got its dedicated replication slot. Additional monitoring and alarms were set up to check the bloat and queries that were first impacted in the previous execution. Bigger tables were stripped from their indexes, and we decided to add them after the complete sync was done. The only index kept was the primary key one , since logical replication needs at least one unique constraint upon applying subsequent changes from WAL logs.
The migration was still a struggle.
The whole team was checking dozens of metrics and also browsing through our UI solution examining delays upon usage. We had to stop the migration and start over more than once , but this time it affected only a single, problematic table. Once we got to the biggest table inside our database, we needed to remove the primary key as well and recreate it once the initial sync was replicated.
We managed to copy all of the data to our on-premise cluster and were in the sync phase. Features such as data removal were halted until we fully migrated and we were now maintaining two separate clusters.

Load tests with business-specific scenarios
Data was replicated, clusters were up and running, DDL was synced, applications were working without issues, and the overhead of logically replicating changes didn’t affect the AWS cluster. Now what?
We needed to put our HW to the test, and we needed a fallback if we ran into problems.
This is the moment where we regretted not putting that extra time into having a load test. Not any kind of load test – the one that specifically mimics our production behavior, a user on our solution, and the ability to multiply it by a custom number.
Luckily, the majority of our load was SELECTs. We used our load balancers to include standby servers from the on-prem solution together with production ones. This allowed us to easily fall back, and kick out of the balancer, in case of degradation.
The major downside of our approach was that every latency introduced in the system was immediately affecting the client. We have repeatable tests that monitor the solution and, in 99% of the cases, spot the degradation before the user does, but there is still that 1%. Apart from “testing in production” , another major downside is that there were too many unknowns inside the equation to have exact conclusions. There is always a probability something else is affecting the results when you are part of a live system.
During these tests, we saw that our backups were disturbing our workloads and that we would need to introduce a separate server for full and incremental backups , something we didn’t even think about while we were on AWS.
Amzon’s Performance Insight is worth every penny. Only when we stopped using it and lost the ability to check the lifecycle of every executed query and pinpoint the exact wait event causing the delay did we realize how powerful it was.
We had to implement our solution, and we did, but again, we learned that we took some things for granted when using AWS.
The patient recovered in no time
The final maintenance was scheduled for the complete migration of all services to the new on-prem solution. Here our preparation was on point. We’ve completely automated the process , we just needed to execute a few CLI commands to gracefully migrate the whole solution. Given the usage of our product, the only window we had, with minimal traffic and client impact, was from 0:00-3:00 UTC. Since we are in CET this meant a long night for us.
We were struggling not to fall asleep before the maintenance started and would probably struggle to sleep afterward. The migration went surgically precise, and our patient recovered in no time. The window was scheduled for a full three hours, and we managed to redeploy, clean up error logs, and validate in a little more than an hour.
Although falling asleep was hard because of the adrenaline spikes, the sense of accomplishment helped us rest our tired eyes.
Life after migration
Looking back at the journey of the migration, a pragmatic observer could spot the good and the bad of each setup we had. Product maturity, access to powerful on-prem hardware, gathered know-how inside the company and cost reduction made the decision of the migration a no-brainer.
However, there is a lot of work now on our hands that we just “threw money at” when using the cloud. Maybe the best thing to understand as an organization and as a developer is to recognize when you are ready to make this step.
Identify a step in your product lifecycle where such moves have to be taken. With increased usage of your solution, you should think about scalability and cost-efficiency not only on service level or feature bottlenecks but the ecosystem as a whole.
Definitely choose your technologies wisely in the beginning. When you introduce new tech (platform change, database, framework, or even a library), build up expertise, check the knowledge inside the company, understand and take responsibility for bugs in the tech now being your bugs.
Don’t forget to think about scale. Premature optimization is the root of all evil, they say, but nevertheless, your design has to have a vision.
These decisions are not easy, but neither is our job. We are fortunate to grow as individuals, learning by doing and owning our decisions, making us better developers but also human beings.
The post Database migration: Developers’ open-heart surgery appeared first on ShiftMag.

Top comments (0)