
In this article, I’ll present the algorithm which helps to answer the main question of all project planning efforts:
When will it be done?
A more formal representation of this problem sounds like: “Having some tasks which might depend on each other and some folks which can do those tasks when a milestone can be reached?”
 Weekly sprint planning meeting in essence
Weekly sprint planning meeting in essence
A Little Backstory
Since summer 2019 I work as a tech lead. Currently, I’m responsible for 3 different projects with a team of 7 developers, 2 managers, 2 designers, and several departments to cooperate with.
For task tracking, we’re using our internal tool Yandex Tracker which is mostly like Jira. But it has no tools that’ll help to find the answer for an eternal question: “When?”. That’s why from time to time we manually sync tasks with Omniplan. Turned out that it’s the tool that solves almost all project planning problems and moreover it has an auto-planning feature so all situations when one assignee has workload over 100% are resolved automatically.
Still, it has some drawbacks:
Slow and unreliable project sync between team mates based on a local copy syncing
MacOS only
Quite hard to sync it with our issue tracker
Pricey: $200 and $400 for Pro edition
So I’ve decided to try to make my own Omniplan version with blackjack and hookers that would be:
Web-based
Simple syncing with our tracker
With real-time collaboration
The most exciting part was to make a scheduling engine. I didn’t understand why only Omniplan has such an essential feature. Now I do.
So this article is about scheduling.
Developing a scheduling engine
First I’ve done some research. I’ve googled for solving scheduling tasks in general and found a lot of about Gantt, PERT, but haven’t found any practical algorithms.
Then I looked for open-source libraries and found only one: Bryntum Chronograph. It seems like something I was looking for all the time. They even have benchmarks. But, well, talking honestly I didn’t understand any of its code and almost complete lack of documentation didn’t help either. I thought maybe, what if I could write it from scratch with less code.
So, as usual, I’ve tried to draw the problem.
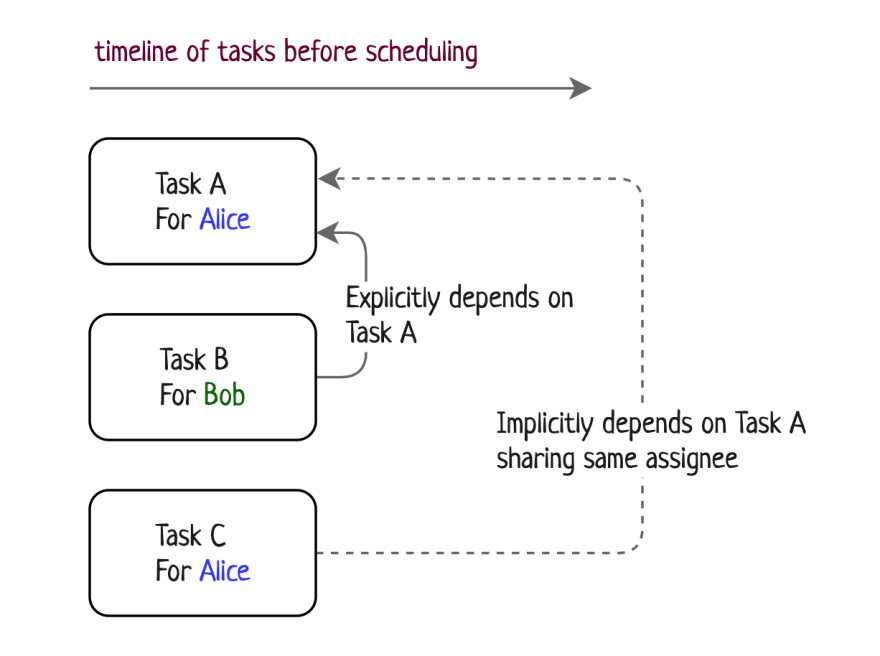 Timeline of tasks before scheduling
Timeline of tasks before scheduling
While drawing it I’ve probably got the most important insight: tasks can be represented as a directed graph and edges are not only the explicit dependencies but also implicit dependencies by the same assignee.
The following algorithm should lead to such tasks arrangement:
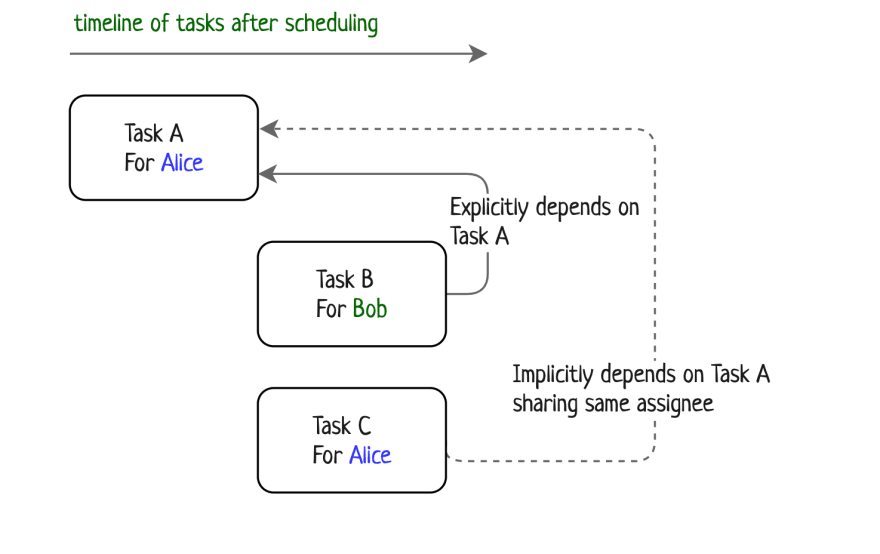 Timeline of tasks after scheduling
Timeline of tasks after scheduling
Let’s consider what a task is:
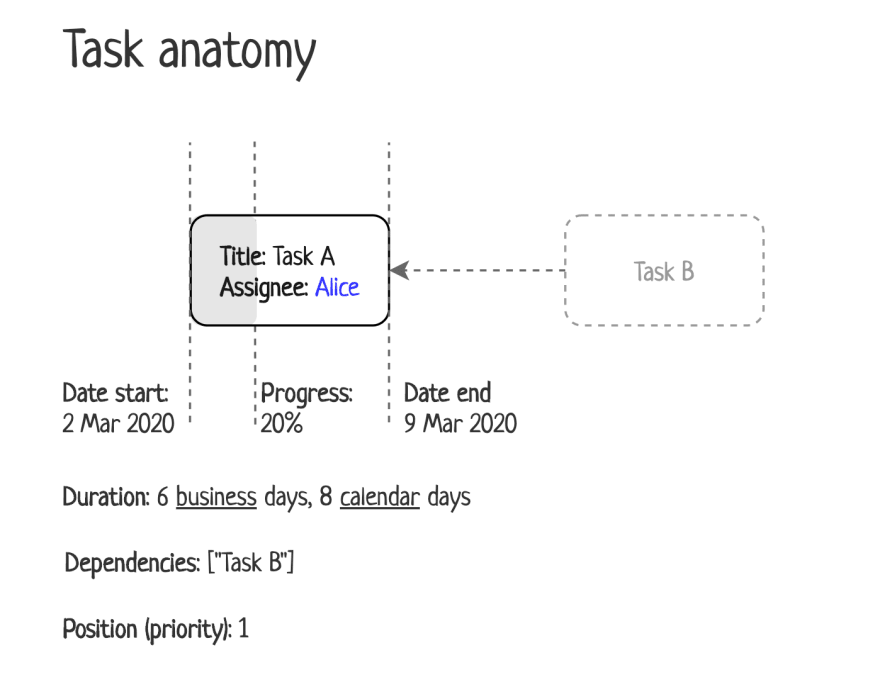 Task anatomy
Task anatomy
There are some not so obvious properties of a task:
Duration. The task is being done only during business days and the number of business days is an estimation of a task. So in this example the task starts on 2 March, has an estimation of 6 days, so it will end on 9 March (not 7 March), because 7 and 8 March are holidays.
Position. In this model, we assume that tasks with lower positions (same as a higher priority) should be done earlier than a task with higher positions (or lower priority).
Progress. It is a portion of a task that can be represented in percents but in fact, it is a number of days that were spent on a task. For example, if a task is estimated up to 4 days and, then progress is 75%, that 1 day left to task completion.
So TypeScript type is as follows (ID is just an alias for string):
The algorithm
In essence, the algorithm should change start and end dates of the tasks in the following way:
Tasks should start today if it is possible
It should be impossible to start a task today if it has other tasks as prerequisites that are unfinished. In that case, a task should start right after the last prerequisite’s end date.
Pretty simple, huh? 🙈
The main steps of the algorithm are:
- **Build a graph from tasks. **Make edges taking into account explicit dependencies and implicit dependencies by the same assignee.
2. Make a *reverse graph* to be able to detect sinks (node without outgoing edges), sources (node without ingoing edges) and disconnected nodes (nodes without edges at all). *A reverse graph *is the same as an original directed graph but with inverted edges.
To visit all nodes we need depth-first search traversal, so I‘ve made a universal DFS helper function as well:
3. Visit every node (task) and update a start and end dates. Visiting should be performed starting from the task with higher priority
If a task is a source (it is not a prerequisite for any other task and task’s assignee has no other task to do before this task) or a task is disconnected node (it has no dependencies and it is not prerequisite for any other tasks) then we start task today.
Otherwise, a task has prerequisites and its start date should be set to the latest end date of its prerequisites tasks.
Also, it is important to correctly update an end date while setting a start date of a task. We should take into account actual business days and the progress of a task.
What can be improved
Circular dependency detection. If cycles are present throw an error because that means that some task A has as prerequisite task B and task B has as prerequisite task A, which is a classic problem of circular dependency and the problem should be resolved manually. Tasks A and B do not necessarily have an explicit dependency on each other, there are might some other tasks between them. It is a well-known algorithm I think I’ll add it soon. For my current use case, it is not that important.
Probably the most important feature which leads to a more complex solution is introducing a desirable start date of a task. I didn’t research it yet, but if someday it will grow to a standalone web-service I think it should be done. Now, this feature can be mitigated by setting proper priorities of tasks.
For the enterprise-grade solution, it is important to take into account vacations and public holidays. I think updateStartDate function can be quite easily updated to support this functionality.
For my case having a day as a time quant was okay, but I believe for some people hour-based planning might be important. I think implementing an hour-based quant can also introduce some complications to code.
Conclusion
The code from the article you can find here. You can grab and use it as an NPM package.
I’m wondering if a presented solution has some flaws. If you spotted some please contact me here or on issues section in Github.

Top comments (0)