Recently, while having a work conversation, I heard a thesis from a colleague that “In Kotlin coroutines you have to use Kotlin’s Mutex to synchronize modification of an object from different threads,” which seems to be a common misconception, and here I want to explain why it’s not always right. With the numbers.
So, basically, I see that it’s common to think: “if you use coroutines and inside those coroutines you have a shared object which you modify from multiple coroutines, then to synchronize the access to it you have to use Kotlin’s Mutex”
The docs imply that, and also they say that you should never have blocking code in your coroutines. But this “blocking code” is a very confusing term. It’s supposed to mean that this code wastes CPU on doing nothing (i.e. on waiting) for a time long enough to run something else during this time.
So a lock is definitely a blocking code, right? Sometimes. But it doesn’t automatically mean you should avoid using it. Because the key point is “long enough.” Which means that the waiting time is longer than switching the context to another operation like copying blocks of stack/memory, which in turn also assumes polluting the CPU caches, possibly switching to another core, etc.
All of those are comparably slow operations (from 1ns to access data in the current CPU L1 cache, to hundreds and thousands of nanoseconds to copy the memory to another place). Note, though, that it’s still a hundred times faster than an IO operation.
So the rule of thumb is to use coroutines for IO operations, and standard primitives for non-IO operations. Unless you have some very specific case. And a shared object access is nothing like that, because system locks are very fast and memory efficient.
And, btw, even to switch a coroutine context you would probably rely on a lock or two somewhere inside the coroutines library, so a JVM lock is unavoidable most likely.
Okay, enough theory and assumptions. Let’s benchmark it and see if it makes sense.
I have a very simple idea of a code that:
- fully utilizes CPU while while executing many short and independent tasks
- no IO
- have an object to synchronize the state between threads
The “task” is calculating a SHA3 hash of the input which is the current task index and the thread index. Each one goes in its own thread. It’s a fully deterministic operation and does the exact same amount of work regardless of the order of execution. And as a synchronization step I compare it to the last known value and choose the lowest value.
The code for the task:
fun cpuTask(i: Int, rail: Int): String {
val sha3 = SHA3.Digest256()
return Hex.toHexString(sha3.digest("CPU/$rail/$i".toByteArray()))
}
Called from:
class State {
var current: String? = null
fun update(next: String) {
if (current == null || current!! > next {
current = next
}
}
}
val state = State()
val lock = ReentrantLock()
runBlocking {
//
// run 25K threads (coroutines)
for (rail in 1..25_000) {
launch(Dispatchers.Default) {
var prev: String? = null
//
// Execute a CPU bound task 1K times in each thread
// resulting in ~10 updates to the shared state
for (i in 1..1000) {
//
// Run a task
val next = cpuTask(i, rail)
//
// Check if it's better for the current thread.
// Only in this example, to avoid too many locks.
// Version with "Always" suffix doesn't have this check
if (prev == null || prev > next) {
prev = next
//
// Update the shared state
// Here it's a JVM Lock, but there is a version with Mutex
lock.withLock {
state.update(next)
}
}
}
}
}
}
There are two ways to have the synchronization though. One is to always compare with the shared value (the benchmarks with the “Always” suffix). Another one is having a two-step process, first compare with the best value for the current thread, and only the best is compared to the “shared best.” This way dramatically decreases the amount of locks, and having both ways allows us to compare the effect of lock.
I implemented the same logic in different ways to compare the performance:
- Coroutines + Java Lock
- Coroutines + Coroutines Mutex
- Plain Java Threads + Java Lock
- Reactor with No Lock
- Plain Java Threads with No Lock
The last one is a base number to compare the others, because it’s supposed to be the most optimal code.
I ran this code on the same machine with nothing running on it except the code, using Ubuntu 22.04 / Intel i7 8 cores / OpenJDK Java 21. I ran 25,000 tasks (in parallel limited to the CPU count) each doing 1,000 calculations. I ran each 12 times in random order, so the benchmark should not be significantly affected by some preexisting state of the memory, JVM warm-up, or similar.
The first part is the basic benchmarks:

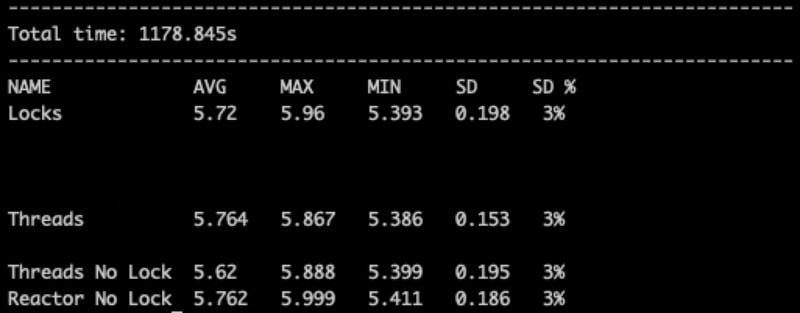
Here we see the “Threads No Locks,” which is our main basis, with 5620 ms.
And the other standard JVM and Reactor-based implementations that are not very different from each other. They are +100ms to execute, which is lower than the Standard Deviation, so we can’t really say they are much slower, but they are clearly in the same bucket. It’s safe to say that on average all of them have the same performance.
The code above doesn't do much locking because it selects the best per tread before locking. Now what if we always lock the state and compare inside?

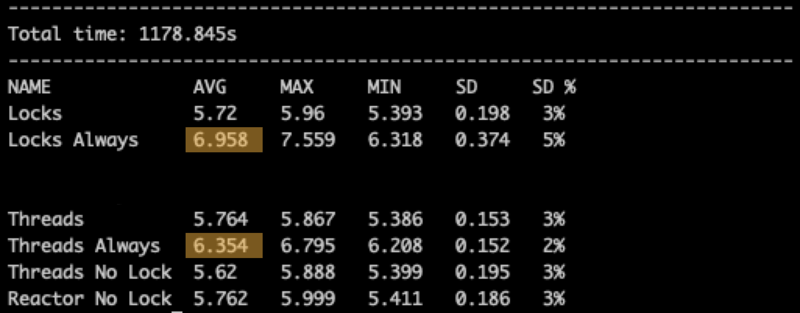
Examples with the “Always” prefix demonstrate the effect of the unnecessary locks (i.e., when each value is compared to the global value). Compared to that, we see that the optimal code as in the previous screen is 25%+ faster.
And now the Coroutines Mutex instead of JVM Lock:

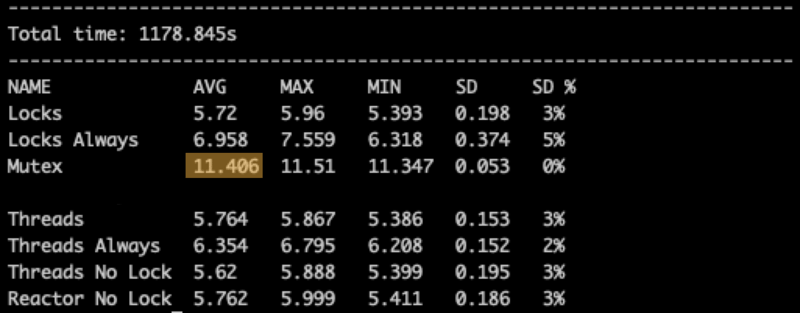
Now we see that the Coroutines Mutex doubles the time of the execution. It’s not just a minor performance issue.
Note, it’s an “optimal” implementation that doesn’t use Mutex too often. Like the very first example with Lock.
What if we always synchronize with the Mutex? Will it be the same 25% loss of performance like with the others?

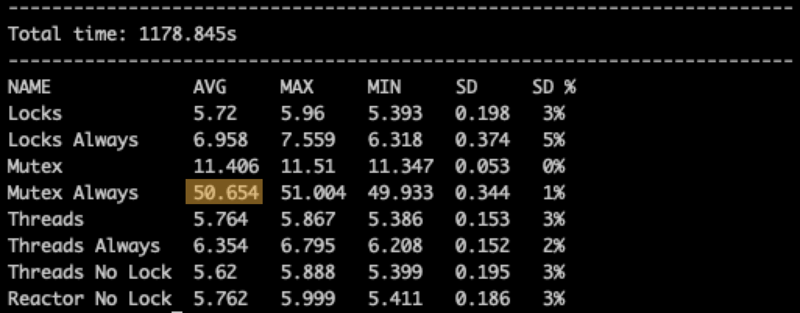
Oh, no!!! It actually makes it 5 times slower than the previous! Or almost 10 times slower than the JVM Lock.
This is the cost of using a coroutine primitive for a non-IO operation.
The final table looks like this:

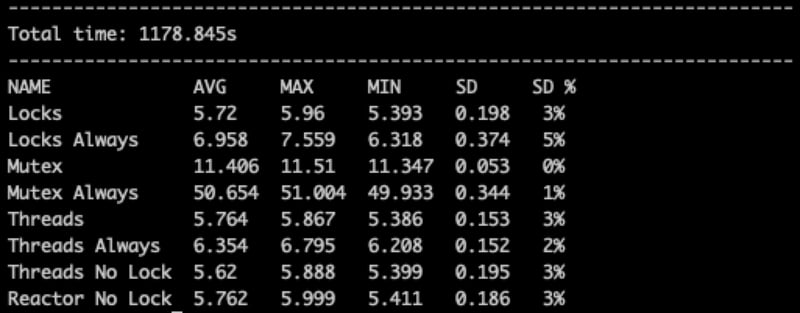
In summary:
- Use coroutines and related, including Mutex, only for IO-bound tasks;
- Use Mutex if you lock over other coroutines (i.e., you call a suspend function inside the lock), but if you do everything right you would not have non-IO coroutines anyway
- Use standard JVM primitives, including Lock, for CPU/Memory-bound tasks with no coroutines inside the lock
- And of course avoid having long tasks under a lock, regardless of the type of lock

Top comments (0)