
Incidents that disrupt services are unavoidable. But every breakdown is an opportunity to learn & improve. Our latest blog is a deep dive into best practices to follow across the lifecycle of an incident, helping teams build a sustainable and reliable product - the SRE way
As the saying goes, “Every problem we face is a blessing in disguise”. On similar lines, every incident in system infrastructure, helps product development & engineering teams understand better about the capabilities of system architecture. This can further help organizations in building a sustainable and reliable product.
In this blog, we are quantifying all complexities of handling an incident in a well-structured format with an intent to help you handle every incident effectively.
- What is an incident?
- What is the lifecycle of an incident?
-
What are some of the best practices in incident management?
- Recursive Delegation of Roles and Responsibilities
- Centralised and Designed War Room for Incident Response Taskforce
- Maintaining a Live (Real-time) Incident State Document
- Live Handoff across Incident Management Team
- Incident Management Strategy and Best Practices
- Postmortems and Root Cause Analysis (RCA)
- Conclusion
What is an incident?
ITIL 2011 defines Incident as,
“an unplanned interruption to an IT service or reduction in the quality of an IT service or a failure of a Configuration Item that has not yet impacted an IT service [but has potential to do so]”
Clearly, in order to maintain acceptable service levels, it is important to resolve incidents and restore normal services as quickly as possible.
What is the lifecycle of an incident?
ITIL defines a standard lifecycle of an incident. While the actual activities that occur during each phase have changed over time, it is still a good starting point for a detailed description of incidents.
Incident Identification, Logging, and Categorisation
Incidents are identified through reports from monitoring systems, or by manual identification. Once an incident is identified it is logged. An incident log can be used to validate that all incidents have been addressed and to identify trends. At this point, the incident is categorized by adding additional information like severity, functional area, and ownership. These three activities were once the responsibility of a first-level monitoring technician, nowadays they are normally automated.
Incident Notification, Assignment, or Escalation
This stage is about notifying the right people to address an incident. In many modern environments identifying the correct responders can be a complex process. Similarly, many organizations have elaborate escalation processes to get specialists or SMEs when the initial responders need help. Modern incident management systems can reduce turnaround times by using rules to automate this.
Incident Investigation and Diagnosis
Once notified, incident responders, gather information about the incident using observability tools. In addition to the current state of the system, RCAs of similar incidents in the past can be valuable sources of data. This information is used to build a hypothesis about the probable cause of the incident and to decide on a fix.
Incident Resolution
The responder team applies the fix proposed in the previous step and, typically, observes the system for a little while to confirm that the incident has been resolved. Normally, it can take several iterations of trial and error before an incident is resolved. Each trial provides more information to evolve the hypothesis and formulate better fixes.
Note: The OODA Loop
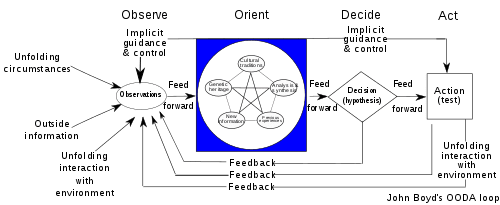
The description of the phases of an incident gives the impression of a structured, systematic engineering process that is calmly applied by experts. However, reality is rarely so neat and clean. Incidents, particularly major ones, are more akin to a battle than an engineering process. Everyone is under pressure, failure has catastrophic consequences and there is always insufficient information to understand what is really happening.
It is appropriate, therefore, that the best way to respond to such situations was determined by the military: the OODA loop. Originally conceived to guide fighter pilots’ decision-making during dogfights, it has since been adopted by many industries as a framework for handling crisis situations.
The OODA loop requires the responder to:
- Observe: gather available information about the situation
- Orient: relate that information to existing knowledge, experience, and skills
- Decide: make a hypothesis about the situation, that is, decide the probable cause
- Act: Apply the corrective measure suggested by the hypothesis
- Loop: Feedback results of the action to step one and repeat until resolution.
Incident Closure
The incident is marked closed when confirmation is received that normal services have resumed. The definition of confirmation varies but it is often wise to use multiple independent confirmations, for example:
- Monitoring systems
- Development or Operations team
- End users
An important part of incident closure is deciding and logging follow-up actions. This usually requires a postmortem that does an RCA and a process review of the incident. The process review will generate follow-up steps to improve the incident management process. The RCA will determine if
- a permanent fix is needed
- if any other preventative maintenance is needed to avoid similar or related incidents
- if any clean up or any artifacts created by the incident or troubleshooting is needed
Incident lifecycle now gives a clear picture of various activities an incident management team is practically following while encountering an incident. Now let’s look into the best practices a team should have in order to make incident management a less stressful activity.
What are some of the best practices in incident management?
ITIL incident lifecycle provides a way to handle an incident, but the best practice comes only with extensive practical experience towards managing an incident. This section is about keeping an incident management team productive with a structured format. These are some of the practices that would greatly encourage a team towards efficiency and avoid burnouts.
1. Recursive Delegation of Roles and Responsibilities
The first step is to delegate the work involved among all team members. Handling incidents needs a lot of awareness about who has to do which work. Adequate information about each individual's roles and responsibilities would help them in taking key decisions independently. Now the basic roles in handling an incident are,
- Incident Commander - is the lead member who delegates work to taskforce
- Operational Work Team - Team members in this group are responsible to execute all operational procedures that has to be done to resolve an incident as early as possible
- Communication Team - They help in communicating the status of an incident to other team members and stakeholders. Their main duty is to maintain and update an incident document with accurate information
- Planning Team - Executes planning of handoffs, monitoring capabilities of system infrastructure before and after an incident. Also, they deal with long-term issues like filing bugs and reverting the system to normal once an incident is resolved
How does Incident Command System Work?
The incident command system was originally formulated in the year 1968 by a fire disaster response team to delegate roles and responsibilities for every team member across a team. Later it was incorporated into managing incidents across software and cloud infrastructure systems.
The framework of incident response revolves around 3'C's or the goals of effective incident management. They are,
- Coordination in incident response efforts
- Communication across an incident team, stakeholders and customers
- Controlling all efforts of incident response and management
This is about delegation of roles among an incident management team.
2. Centralized and Well-Defined War Room for Incident Response Taskforce
This stage is about setting up a designated war room, a centralized space where team members can coordinate with each other in resolving an incident at a faster pace. Here, the team can use Slack/Telephone/Video conferencing for maintaining and recording a communication log between team members about incident related traffic and alerts.
3. Maintaining a Live (Real-time) Incident State Document
This stage is about the role of an incident commander to maintain a concurrent live incident document where all details of an incident are recorded diligently. This live document can be hosted on wiki and must be accessible to every other team member, enabling them to contribute data about an incident. This practice ensures transparency among team members and stakeholders.
4. Live Handoff across Incident Management Team
This happens when the incident responders need to change in an ongoing incident. This could be because their shift has ended or even because they are exhausted. When the team changes whatever work they were each doing must be seamlessly handed over to the new team. This includes the overall status, the progress of investigation or corrective action, and more. A real-time incident state document is invaluable for this.
5. Incident Management Strategy and Best Practices
Finally, this stage is about putting into practice all of the best incident management strategies that helped in resolving an incident. This greatly ensures in reducing meantime to recovery and avoid any stressful situations to an incident management team. Some of them are,
- Prioritization of work
- Preparation across a team
- Allow Autonomy to each Role
- Introspection
- Make arrangements for alternatives
- Practice and Change roles
6. Postmortems and RCAs
After every non-trivial incident, it is important to run a postmortem. There are some important outcomes of a good postmortem:
- Corrective or Preventive Actions: A permanent fix of the cause of the incident. Many incidents are resolved with temporary fixes without an assurance that the problem would not re-occur. To illustrate the difference between corrective and preventive action let us take the example of a bug triggered by high load. The corrective action would be to fix the bug. A preventive action would be to increase capacity to prevent the same load levels from being reached again. Normally both actions have to be taken.
- Lessons Learned: A technical learning that can be applied to an unrelated part of the system. A problem in the inventory module caused by an incorrectly configured load balancer, for example, could easily happen in the reporting system.
- Process Improvements: Process changes that could improve how all incidents are handled. For example, “All configuration changes must be logged in the incident log so that they are not forgotten”
The outcomes are achieved by reviewing the incident and identifying its root cause.
Postmortem Best Practices
- Blameless postmortems
When postmortems are focussed on assigning responsibility (i.e, blame) then most participants will be primarily concerned with not being blamed. Conversely, a focus on what went wrong will allow the participants to be more objective and less worried about protecting themselves. It also recognizes that humans make mistakes and that it is more effective to address circumstances that contribute to errors than to seek humans who don’t make mistakes.
- Track and Reward Outcomes
There is no value in postmortems if they do not generate results. Track and reward postmortem outcomes:
- closed action items
- improved reliability
- process changes
- postmortem ownership
Postmortems without outcomes or action items are usually a sign that they’re ineffective.
- Encourage Transparency
The lessons from a postmortem are wasted if they are not applied to all systems and teams organization-wide. Sharing and transparency help ensure that lessons learned to percolate throughout the organization. Some steps to encourage transparency:
- Notifications of new postmortems should be organization-wide
- Conduct cross-team reviews of postmortems
- Regular incident and postmortem reports
- Address Postmortem Culture Failures
Signs of a failing postmortem culture must be immediately addressed. Culture is not a set of principles in a document but behavior that is rewarded or penalized. Some failings are:
- Assigning “responsibility” (that is, blame) during postmortems.
- Insufficient time for postmortems.
- Repeating incidents
- Unresolved postmortem action items
Additional reading: Towards More Effective Incident Postmortems
Conclusion
Incidents are common events that should be handled in a standard pattern. ITIL defines a good template to follow. A few good practices can really help improve the effectiveness of an incident management process:
- Team should maintain a clear and well-structured “line of command”
- Team should delegate roles and responsibilities of every team member to resolve incidents as quickly as possible
- Record every action on debugging and mitigation while resolving incidents
- Always declare active incidents as early as possible across an SRE/DevOps team and delegate corresponding roles across team members to collaborate effectively
- Set up an appropriate framework for defining incident response process and procedures to scale up team’s performance
- Team should have the best practice in incident response handy to avoid any deviations from it
- Postmortems and RCAs help organizations learn from incidents and prevent them from reoccurring.
We hope this blog gives you a better and deeper understanding of the best practices to follow during the lifecycle of an incident, enabling you handle critical incidents in your organization without much hassle and burnouts.
Squadcast is an incident management tool that’s purpose-built for SRE. Your team can get rid of unwanted alerts, receive relevant notifications, work in collaboration using the virtual incident war rooms, and use automated tools like runbooks to eliminate toil.


Top comments (0)