
JavaScript has many abilities and one of the most unique and useful is its ability to manipulate the DOM.
What is the DOM?
Document Object Model(DOM) is an interface that allows a programming language to manipulate the content, structure, and style of a website. It can simply be understood as a tree of nodes created by the browser. Each of these nodes has its own properties and methods which can be manipulated using JavaScript. Almost anytime a website performs an action, such as rotating between a slideshow of images, or toggling a navigation menu, that is the result of JavaScript accessing and manipulating the DOM.
The Document Object:
At the most basic level, a website consist of a HTML Document. The browser creates a representation of that document, the (DOM) as it loads and parses the HTML.
Below is a visual representation of what the DOM tree looks like:
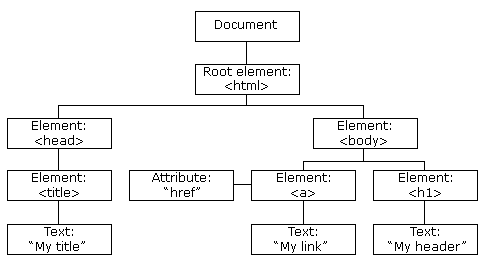
Here we have the document object.This is the core foundation of the DOM, which is a built-in object that has many properties and methods which can be used to access and modify the DOM. To perform any form of DOM manipulation, you first have to access the document object.
Accessing the DOM:
In order to be able to manipulate an element in the DOM, you first have to select that particular element. Luckily for us, there are 5 major ways in which one can select elements in a DOM.
getElementById
The most common way to access an HTML element is to use the id of the element. This method document.getElementById() as its name implies, returns an element from the DOM for the specified Id.
getElementsByClassName
This method document.getElementsByClassName() returns a collection of all the elements in the document which matches the specified Class name.
getElementsByTagName
This method document.getElementByTagName() is nearly identical to getElementsByClassName().. but its main difference is that it accepts a tag name/type(example: (p)paragraph) and returns all the elements of the specified Tag type.
querySelector
Just like the previous methods, document.querySelector() will return whatever we place between the parentheses. Its main difference is that, it's not limited to just one type. We can use querySelector to either retrieve an id, a class or even a HTML tag. One thing to note is that this method will return the first element that matches the specified CSS Selector.
Lastly,querySelectorAll
This method works similar to above. Whereas querySelector() can only return a single element, document.querySelectorAll() returns a node list collection of all the elements which matches the specified CSS Selector.
Creating/Deleting Elements:
document.createElement()
this method creates an Element Node with the specified name.
document.createElement('button')After the element is created, use the
element.appendChild()
method to insert/get the element onto the page.
document.body.appendChild(btn)element.remove()
this method removes the specified element from the page.
Summary:
Knowing how to access and work within the DOM with JavaScript is super important. These are just a few of the basic overview. I hope you find this article useful. Thank you guys for reading and Happy Coding!😀

Top comments (0)