
Introduction
This article describes a real situation that happened when I worked for a previous company some time ago. The main goal here is to explain both the problem as well as the solution. I thought I could share it so that it can also help someone that may run into the same problem eventually in the future.
Without further delay, let’s then begin. I was developing an innovative insurance software and one of the use cases that needed to be developed was the user having the possibility of knowing which entities (of any type) were being used or referenced by another given entity, what kind of relationship the entities had between them, among other features.
Our software was built using a microservices architecture with an increasing number of services, so this was not an easy task, since we’ve followed the Database Per Service pattern which on one hand was good because it allowed us to decouple our services and use the more appropriate technology for each database (SQL vs NoSQL) but on the other hand it created the problem of joining information persisted in separated databases. In short, we needed to create a scalable, generic, and abstract way of querying the information, regardless of the entity type.
The big question that my team and I had at the time was
How are we going to implement this?
The Problem
Our domain model was composed of several insurance business concepts, but to simplify let’s make an analogy of the problem using simple concepts such as "Person" and "Movie".
Let’s assume a Movie is composed by its title and its release date and a Person is composed by its name and birth date. Regarding relationships, a Movie can be directed by one or more Persons and one Person can act in one or more Movies. Figure 1 demonstrates the domain model.
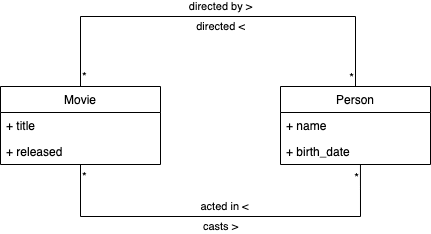
Let’s imagine we have a service for each entity, people-api and movies-api, that are exposed through an API Gateway. The people-api service is responsible for providing CRUD functionalities for the "Person" entity, through a REST API and the movies-api service is responsible for providing CRUD functionalities for the "Movie" entity, through a REST API as well. The following diagram from Figure 2 describes the current architecture.
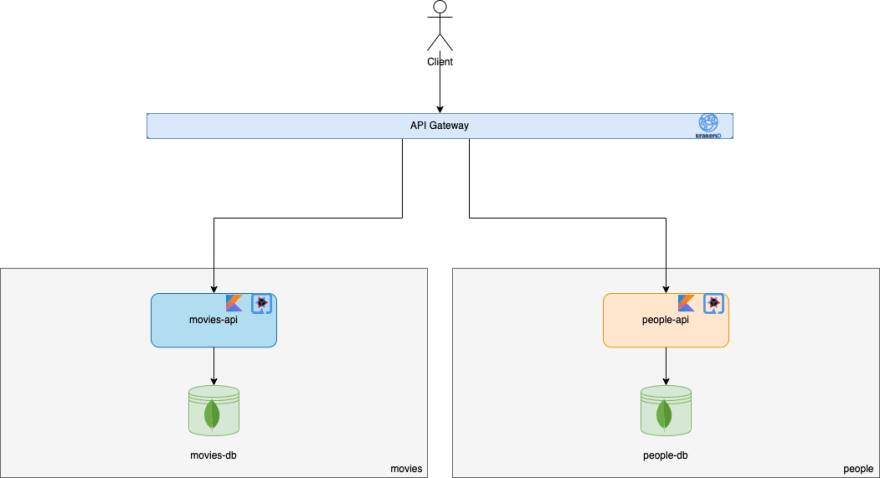
Let’s now consider that we want to know which movies were directed by a given person and what were the actors (an actor is a person, in this context) and their roles in those movies. This is quite a complex query, given the fact that our entities are persisted in different databases.
A possible solution would be having synchronous inter-service communication through the API Gateway and aggregating responses, but that would be somewhat difficult to code and would increase the coupling of our services, decrease cohesion, and also each service would have to know other API contracts, compromising the whole point of having a microservices architecture. In this particular case, it would work, yes, but what if we’re dealing with hundreds or even thousands of microservices? And what if we have hundreds of business concepts with millions of different relationships between them and have to implement every possible query combination? You’re getting the point.
Keeping the previous questions in mind, we can then complicate things a bit more.
Let’s suppose we added a new "Catalogue" entity to our domain model. A Catalogue could be a collection of movies, for instance, and it could have a name and a category. Our new domain model would end up like what Figure 3 shows.
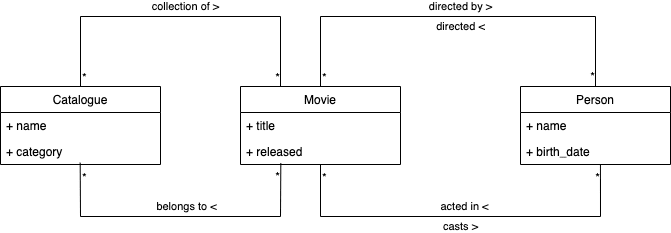
In order to reflect our domain model, we would need to create a new microservice responsible for dealing with our new entity. This new microservice would be named catalogue-api.
Our architecture would then become something just like Figure 4 demonstrates.
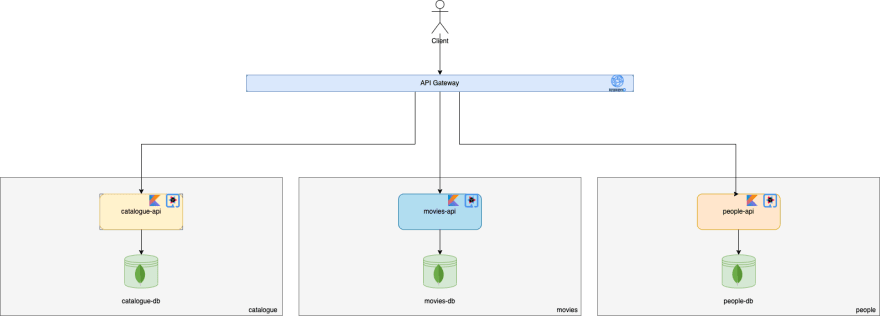
In this case, there is now the possibility of the user wanting to know which catalogues reference a given person/actor. But, wait a minute! The catalogues don’t directly reference a person. Instead, they reference movies and are those movies that reference people. How can we achieve our goal now?
The Solution
After a few long meetings and discussions, we decided to investigate some possible solutions to our problem by doing some proofs of concept and eventually came up with a solution that was scalable and would not compromise what we had before.
We started to think about our business domain model as if it was a graph where the nodes were the entities and the edges were their relationships. Following this thinking, the next graph in Figure 5 is an example of how our entities could be modeled.

Keeping this line of thought, we came up with the idea of having a new service with a Neo4j database that would persist all our entities and their relationships. Then, this service would be able to make all those complex queries in a much friendlier and easier way by taking advantage of the cypher query language to traverse the knowledge graph with any desired relationship length.
But there was one more problem we didn’t figure out how to solve yet:
How can we aggregate all the data persisted in all our databases and persist it into a single one and still keep ongoing consistency?
Change Data Capture using Outbox Pattern
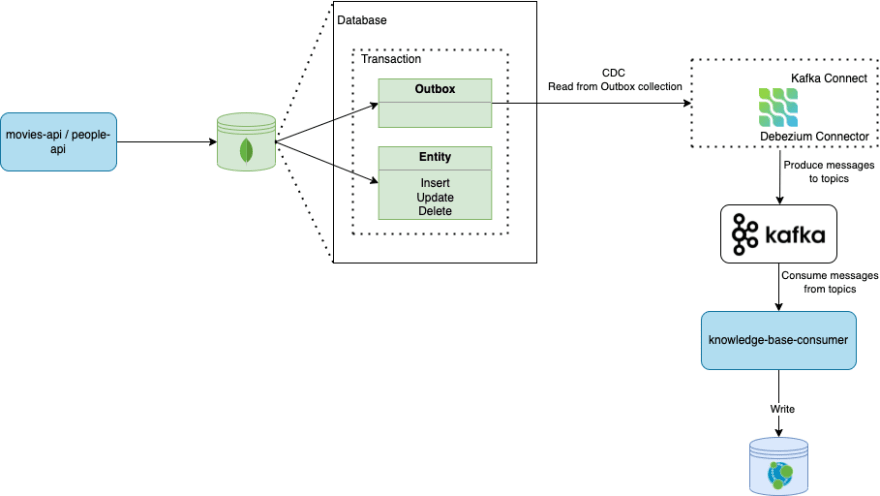
The solution to this problem was implementing a mechanism of asynchronous data replication using the CDC (Change Data Capture) technique with the Outbox pattern. We’ve implemented this by adding a new statement to all write transactions which was responsible for generating an outbox event that would eventually be captured by a Kafka Source Connector and put into a topic that was being consumed by whoever was interested in knowing that the state had changed, specifically our knowledge base.
According to our initial architecture, shown in Figure 2, we can then add Kafka and this new service to our system. This service will be named knowledge-base and will have two applications: knowledge-base-consumer to consume the outbox events and knowledge-base-api which will provide a REST API to query the entities and their relationships.
Building an example project
The following diagram describes the final architecture and that’s exactly what I’ve implemented in this small example project to support this article. KrakenD was used as the API Gateway and all the services were written in Kotlin using the Quarkus framework. people-api and movies-api have each a MongoDB database whereas knowledge-base has a Neo4j database.
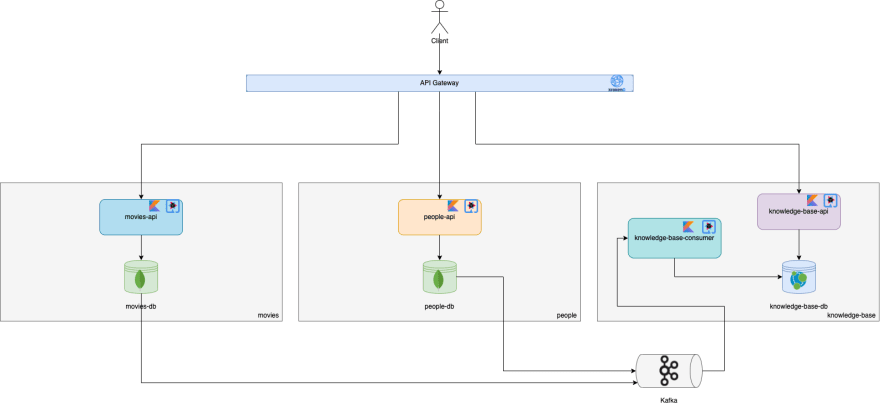
Whenever movies-api or people-api want to perform a write operation on their database, they also emit an outbox event with the correspondent change that will then be put into the correspondent topic that is being consumed by the knowledge-base-consumer. This approach guarantees that all writes to the source database will eventually be replicated to the target database (eventual consistency).
If Kafka is down, the changes are still persisted in the transaction log of the source database, so there’s no harm because once Kafka gets back up, the connector will read the transaction log and populate the topics with the most recent events that were lost. On the other hand, if the consumer is down, the events will still arrive at Kafka, so once the consumer gets back up, it will consume those events, making the overall solution resilient and fault-tolerant.
The following Figure 7 has a small diagram to explain the outbox pattern in this context.
Testing the project
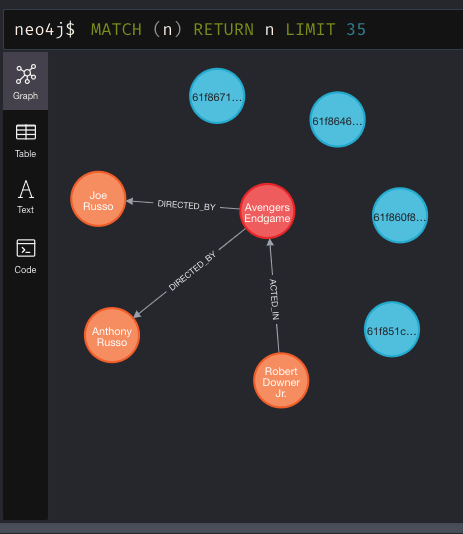
After performing some CRUD operations on people-api and movies-api, we can then take a look at an example of what gets persisted in the knowledge-base-api's Neo4j database, demonstrated in Figure 8.
Final thoughts
This use case was somewhat complex to implement, but we managed to create a solution that suited our needs and was able to scale horizontally and even handle fast response times when querying the graph with millions of nodes and relationships, according to our tests to validate the performance of the solution. The challenge was very interesting and was indeed an enriching experience in terms of imagination, creativity, and knowledge. However, although the approach showed good results, it was just a spike and it never really went to production, but we were really proud of what we accomplished.
Feel free to check out all the source code and documentation of the project in this repository.
If you have any questions, don’t hesitate to reach out to me.
References
Make sure to also check these awesome articles that became an inspiration to the solution and the writing of this article as well.
- Reliable Microservices Data Exchange With the Outbox Pattern
- Microservices Pattern: Transactional outbox
- Kafka Connect: How to create a real time data pipeline using Change Data Capture (CDC)
- Event-Driven Architecture and the Outbox Pattern
- Resilient Eventing in Microservices, using the Outbox Pattern.
- Sending Reliable Event Notifications with Transactional Outbox Pattern
- Outbox Pattern for reliable data exchange between Microservices
Originally posted on Medium
Credits: Cover image by Charles Deluvio on Unsplash

Top comments (0)