Modern Apache NiFi Load Balancing
In today's Apache NiFi, there is a new and improved means of load balancing data between nodes in your cluster. With the introduction of NiFi 1.8.0, connection load balancing has been added between every processor in any connection. You now have an easy to set option for automatically load balancing between your nodes. The legacy days of using Remote Process
Groups to distribute load between Apache NiFi nodes is over. For maximum flexibility,
performance and ease, please make sure you upgrade your existing flows to
use the built-in Connection Load Balancing.
If you are running newer Apache NiFI or Cloudera Flow Management (CFM), you have had a
better way of distributing processing between processors and servers. This is for
Apache NiFi 1.8.0 and higher including the newest version 1.9.2.
Note: Remote Process Groups are no longer necessary for load balancing!
Use actual load balanced connections instead!
Remote Process Groups should only be used for distributing to other clusters.
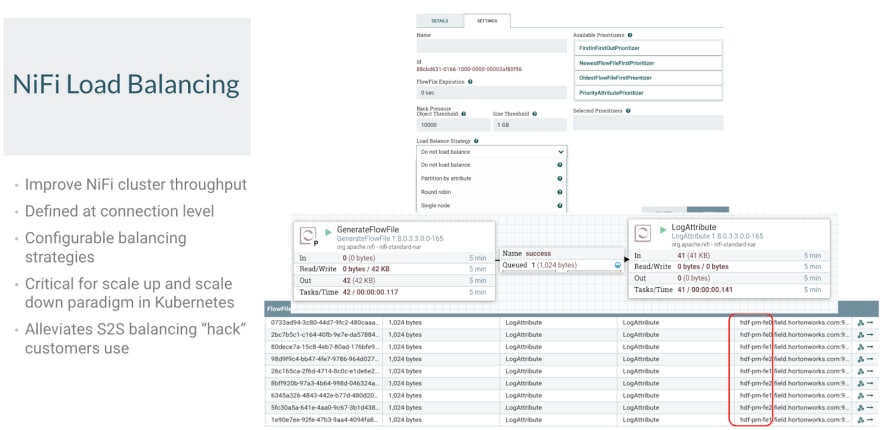
Apache NiFi Load Balancing
Since 2018, it's been an awesome feature:
https://blogs.apache.org/nifi/entry/load-balancing-across-the-cluster
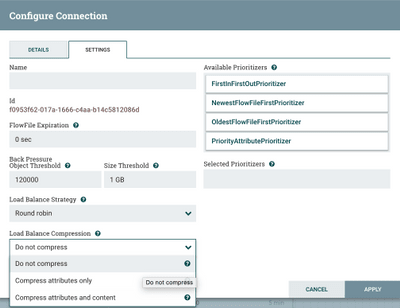
We have a few options for Load Balancing Options, these strategies include
"Round Robin" that during failure conditions data will be rebalanced to
another node. This can rebalance thousands of flow files per second or
more depending on flow file size. This is done to give a node a chance to
reconnect and continue processing.
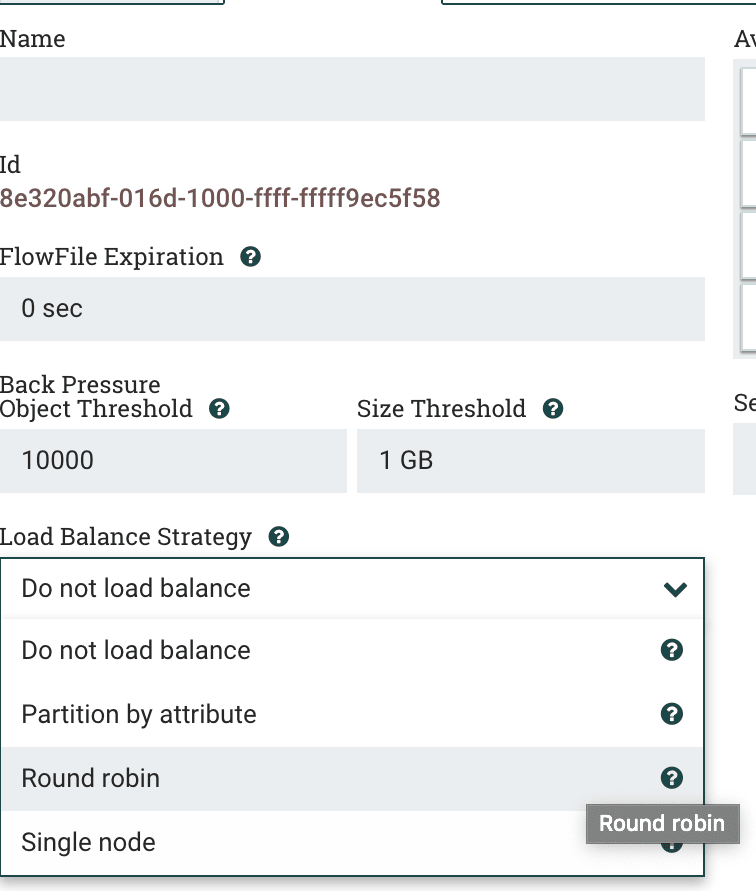
Data Distribution Strategies
Other option is to “Partition by Attribute” and “Single Node” which will
queue up data until that single node or partitioned node returns. You
cannot pick which Node in the cluster does that processing for portability
purposes. We need to be dynamic and elastic, so it just needs to be one
node. This allows for “like data” can be sent to the same node in cluster
which may be necessary for certain use cases. Using a custom
Attribute Name for this routing can be powerful as well as for Merges
in table loading use cases. We can also choose to not load balance at all.
Elastic Scaling for Apache NiFi
An important new feature that was added to NiFi is to allow nodes to be
decommissioned and disconnected from the cluster and all of their data
offloaded. This is important for Kubernetes and dynamic scaling for
elasticity. Elastic Scaling is important for workloads that differ during
the day or year like once an hour loads or weekly jobs. Scale up to
meet SLAs and deadlines, but scale down when possible to save cloud
spend! Now NiFi not only solves data problems but saves you cash
money!
Apache NiFi Node Affinity
Remote Process Groups do not support node affinity. Node affinity is
supported in our Partition by Attribute strategy and has many uses.
Remote Process Groups
To replace the former big use case, we used Remote Process Groups.
We have a better solution, for a first connection like ListSFTP runs on
one node and the connections can then be "Round Robin".
Important Use Case
This load balancing feature of Apache NiFi shows the power of distributing a large dataset
or unstructured data capture at the edge or other datacenter, split and transfer, then use
attribute affinity to a node to reconstitute the data in a particular order.
So what happens is sometimes you have a large bulk data export from a system like a
relational database dump in one multiple terabyte file. We need one NiFi node to load
this file and then split it up into chunks, transfer it and send it to nodes to process. Sometimes
ordering of records will require we use an attribute to keep related chunks (say the same Table) together on one node.
We also see this with a large zip file containing many files of many types. Often there will
be hundreds of files of the multiple types and we may want to route to the same
node based on filename root. That way one NiFi node will be processing all the same file types or
table. This is now trivial to implement and easy for any NiFi user to examine and see what is
going on in this ETL process.
References
- https://pierrevillard.com/2018/10/29/nifi-1-8-revolutionizing-the-list-fetch-pattern-and-more/
- https://community.cloudera.com/t5/Community-Articles/Using-Apache-NiFi-for-Speech-Processing-Speech-to-Text-with/ta-p/249242
- https://community.cloudera.com/t5/Community-Articles/NiFi-Understanding-how-to-use-Process-Groups-and-Remote/ta-p/245486
- https://cwiki.apache.org/confluence/display/NIFI/Load-Balanced+Connections
- https://cwiki.apache.org/confluence/display/NIFI/Clustering+Redesign
- https://blogs.apache.org/nifi/entry/load-balancing-across-the-cluster

Top comments (0)