Simple Change Data Capture (CDC) with SQL Selects via Apache NiFi (FLaNK)

Sometimes you need real CDC and you have access to transaction change logs and you use a tool like QLIK REPLICATE or GoldenGate to pump out records to Kafka and then Flink SQL or NiFi can read them and process them.
Other times you need something easier for just some basic changes and inserts to some tables you are interested in receiving new data as events. Apache NiFi can do this easily for you with QueryDatabaseTableRecord, you don't need to know anything but the database connection information, table name and what field may change. NiFi will query, watch state and give you new records. Nothing is hardcoded, parameterize those values and you have a generic Any RDBMS to Any Other Store data pipeline. We are reading as records which means each FlowFile in NiFi can have thousands of records that we know all the fields, types and schema related information for. This can be ones that NiFi infers the schema or ones we use from a Schema Registry like Cloudera's amazing Open Source Schema Registry.
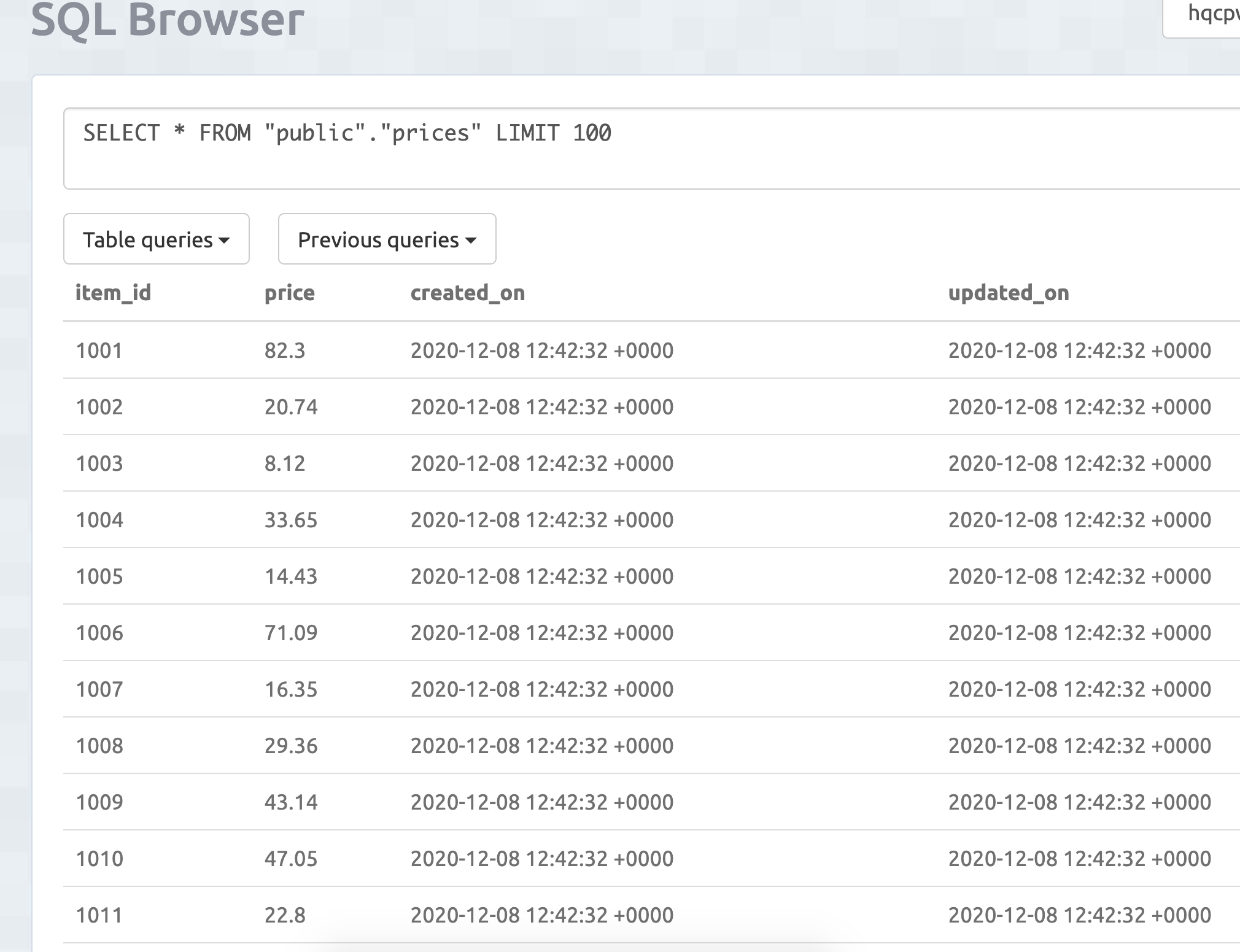
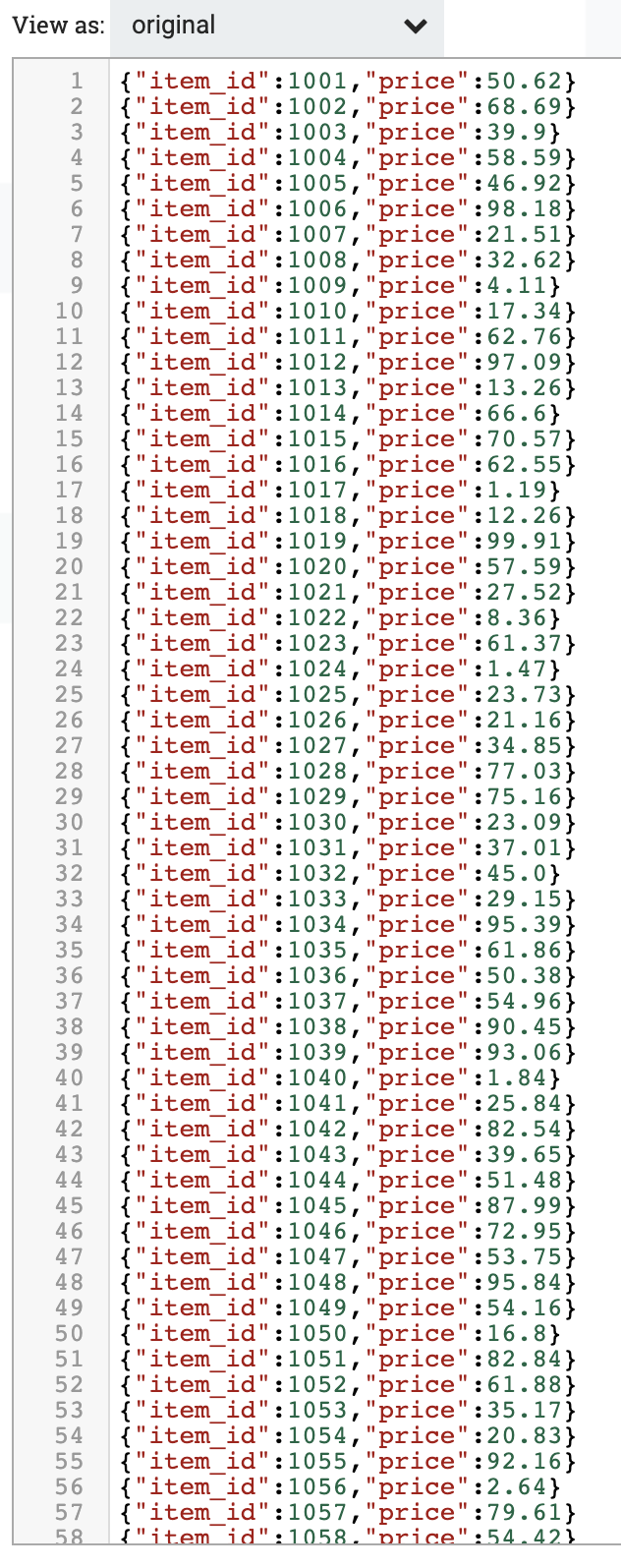
Let's see what data is in our Postgresql table?
*How to *
- QueryDatabaseTableRecord (we will output Json records, but could have done Parquet, XML, CSV or AVRO)
- UpdateAttribute - optional - set a table and schema name, can do with parameters as well.
- MergeRecord - optional - let's batch these up.
- PutORC - let's send these records to HDFS (which could be on bare metal disks, GCS, S3, Azure or ADLS). This will build us an external hive table.
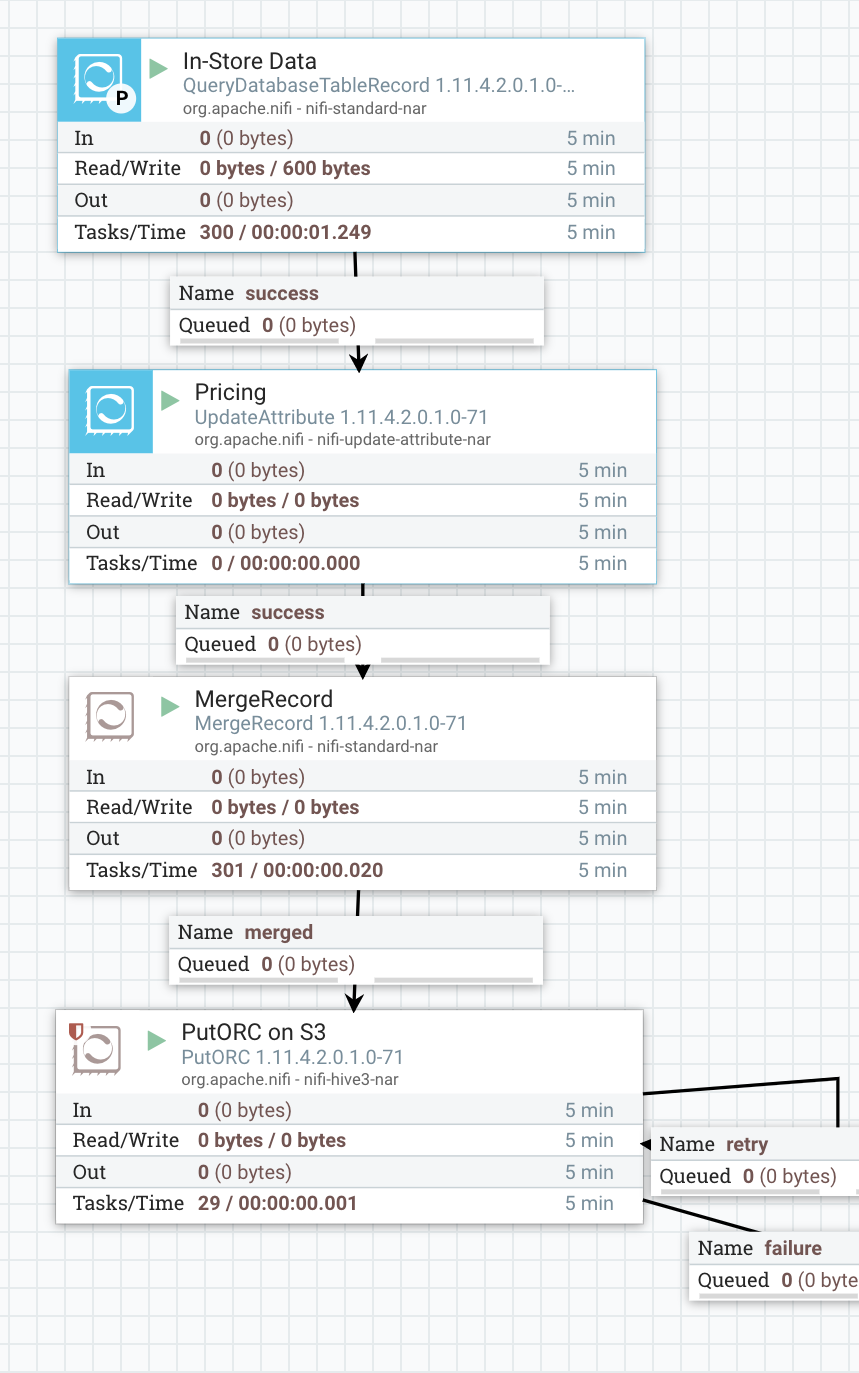
PutORC
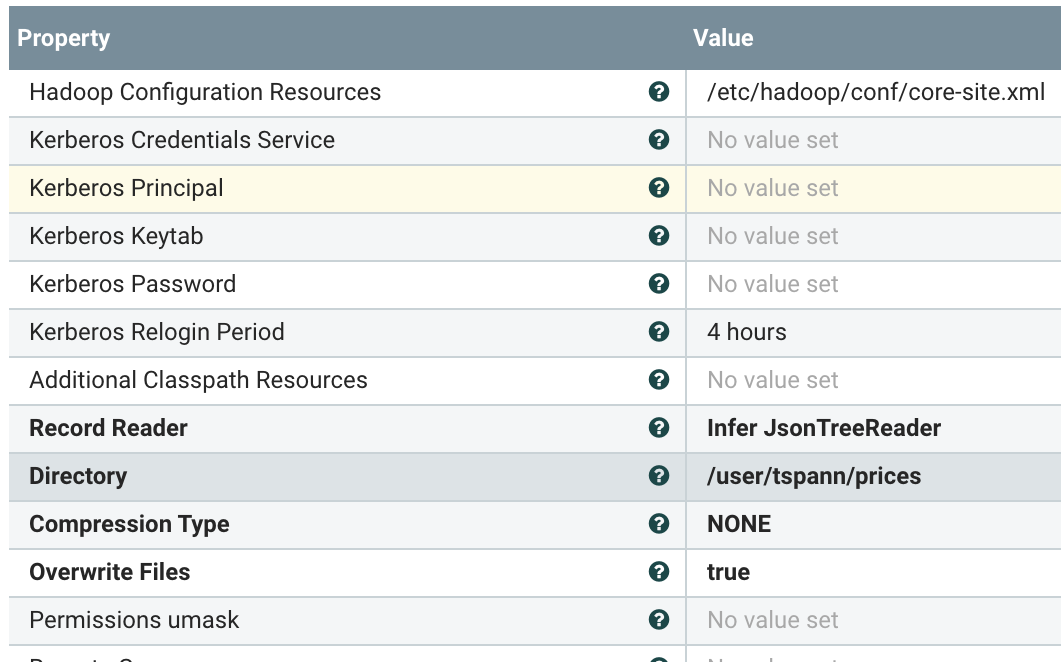
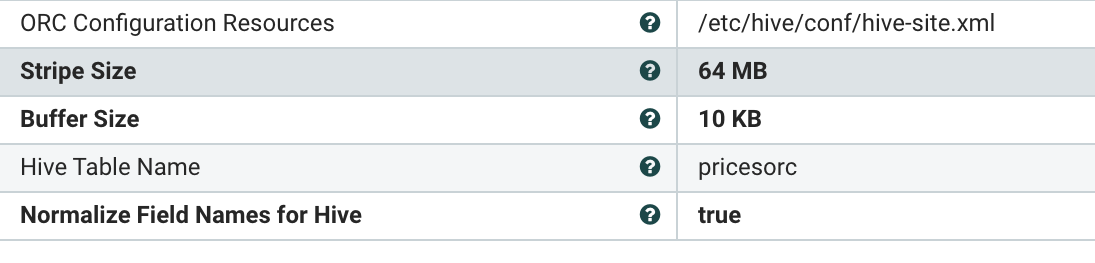
As you can see we are looking at the "prices" table and checking maximum values to increment on the updated_on date and the item_id sequential key. We then output JSON records.
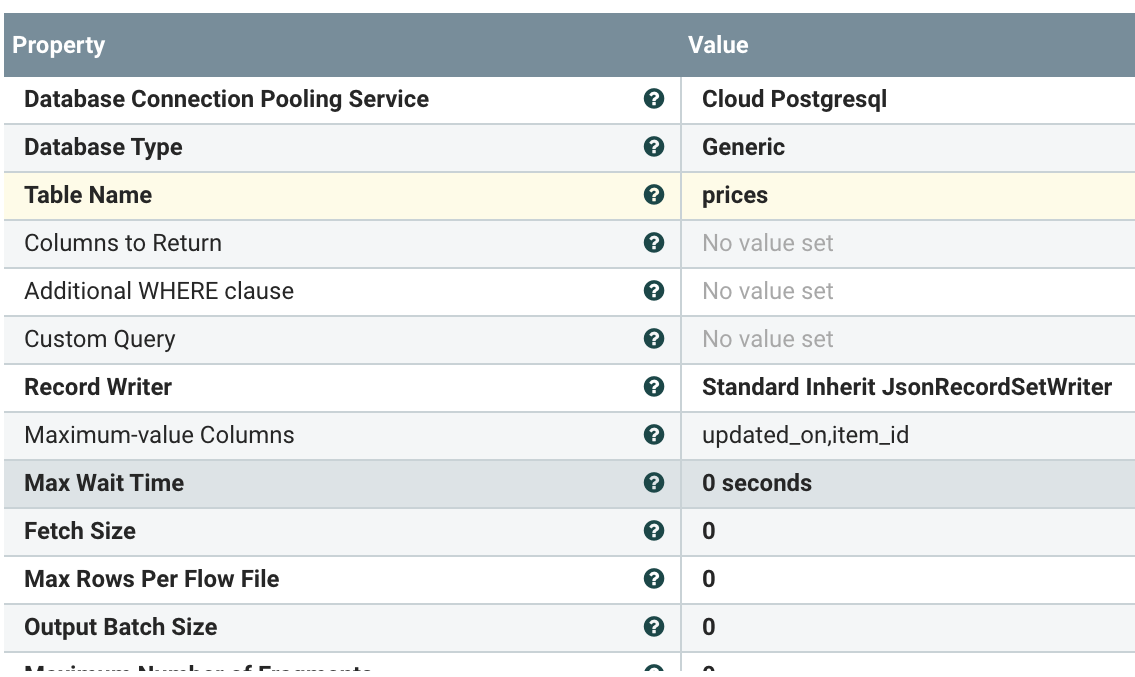
We could then:
Add-Ons Examples
- PutKudu
- PutHDFS (send as JSON, CSV, Parquet) and build an Impala or Hive table on top as external
- PutHive3Streaming (Hive 3 ACID Tables)
- PutS3
- PutAzureDataLakeStorage
- PutHBaseRecord
- PublishKafkaRecord_2_ * - send a copy to Kafka for Flink SQL, Spark Streaming, Spring, etc...
- PutBigQueryStreaming (Google)
- PutCassandraRecord
- PutDatabaseRecord - let's send to another JDBC Datastore
- PutDruidRecord - Druid is a cool datastore, check it out on CDP Public Cloud
- PutElasticSearchRecord
- PutMongoRecord
- PutSolrRecord
- PutRecord (to many RecordSinkServices like Databases, Kafka, Prometheus, Scripted and Site-to-Site)
- PutParquet (store to HDFS as Parquet files)
You can do any number or all of these or multiple copies of each to other clouds or clusters. You can also enrichment, transformation, alerts, queries or routing.
These records can be also manipulated ETL/ELT style with Record processing in stream with options such as:
- QueryRecord (use Calcite ANSI SQL to query and transform records and can also change output type)
- JoltTransformRecord (use JOLT against any record not just JSON)
- LookupRecord (to match against Lookup services like caches, Kudu, REST services, ML models, HBase and more)
- PartitionRecord (to break up into like groups)
- SplitRecord (to break up record groups into records)
- UpdateRecord (update values in fields, often paired with LookupRecord)
- ValidateRecord (check against a schema and check for extra fields)
- GeoEnrichIPRecord
- ConvertRecord (change between types like JSON to CSV)
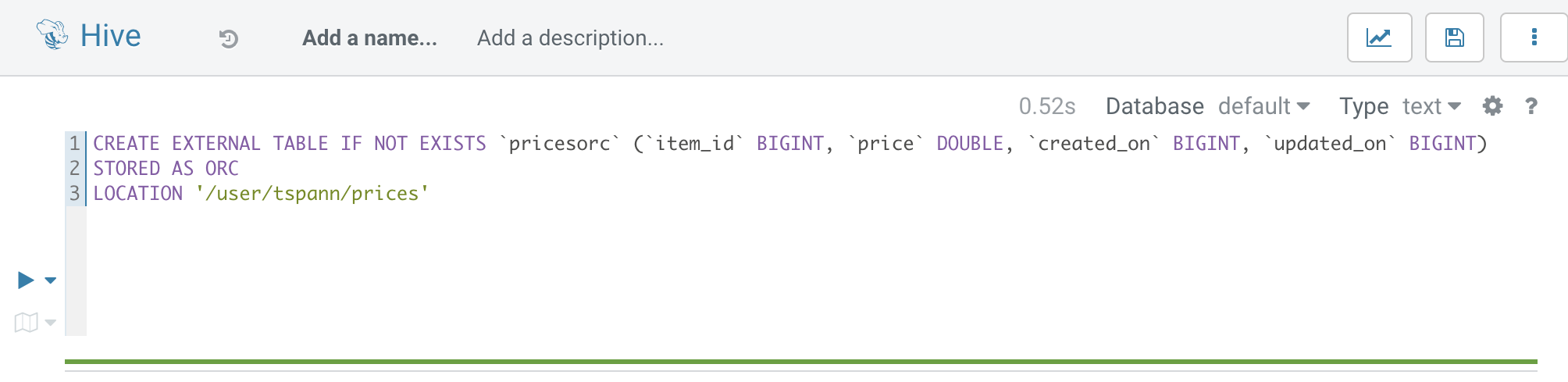
When you use PutORC, it will give you the details on building your external table. You can do a PutHiveQL to auto-build this table, but most companies want this done by a DBA.
CREATE EXTERNAL TABLE IF NOT EXISTS pricesorc (item_id BIGINT, price DOUBLE, created_on BIGINT, updated_on BIGINT)
STORED AS ORC
LOCATION '/user/tspann/prices'

Part 2
REST to Database
Let's reverse this now. Sometimes you want to take data, say from a REST service and store it to a JDBC datastore.
- InvokeHTTP (read from a REST endpoint)
- PutDatabaseRecord (put JSON to our JDBC store).
That's it to store data to a database. We could add some of the ETL/ELT enrichments mentioned above
or others that manipulate content.

REST Output
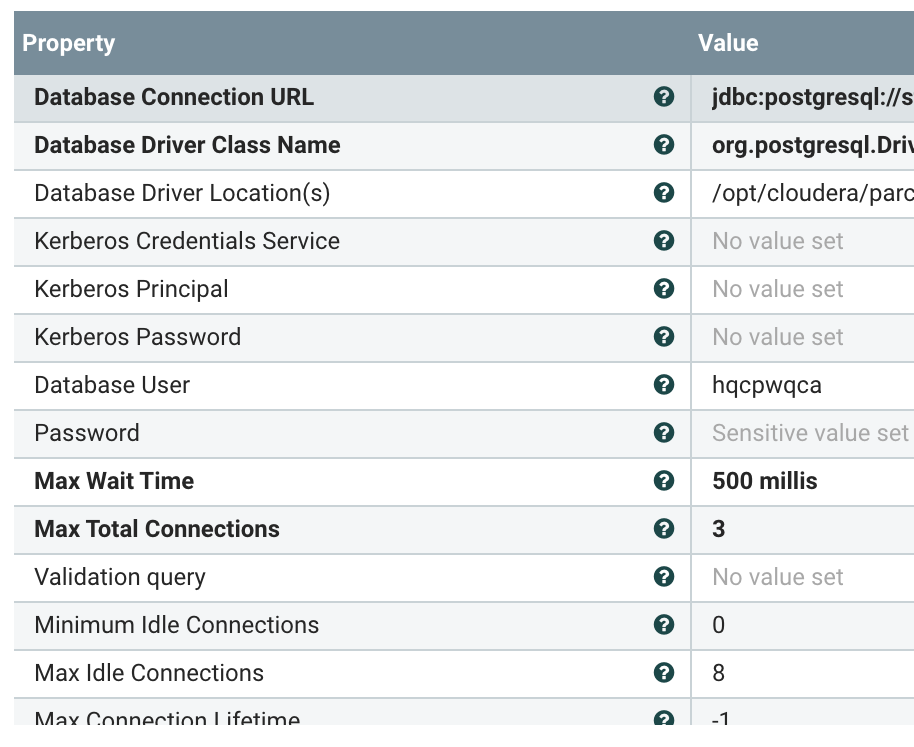
Database Connection Pool
Get the REST Data
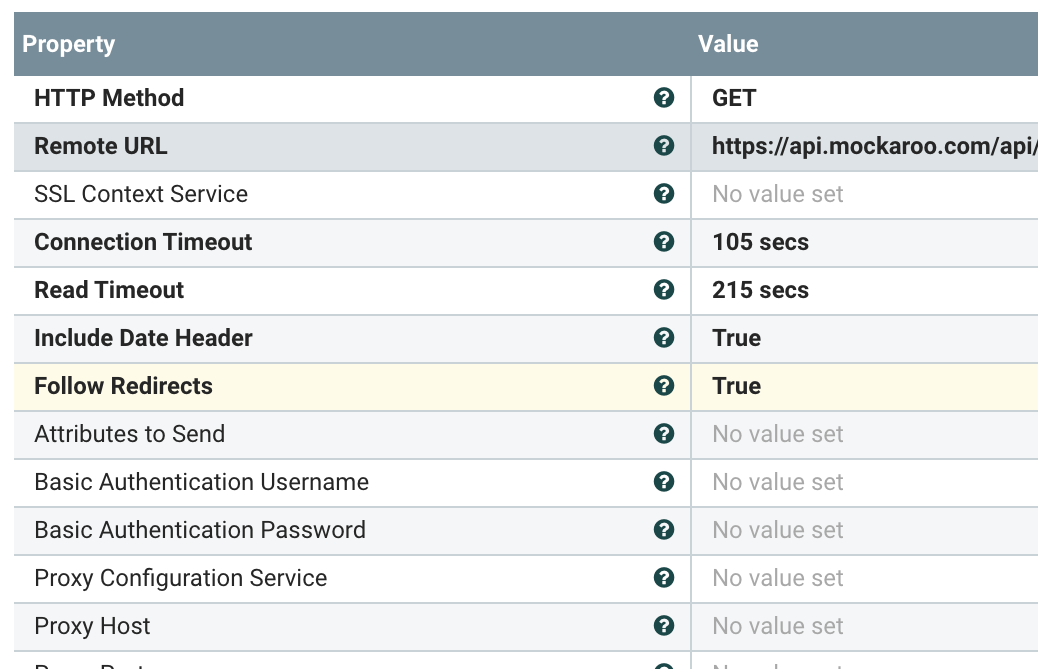
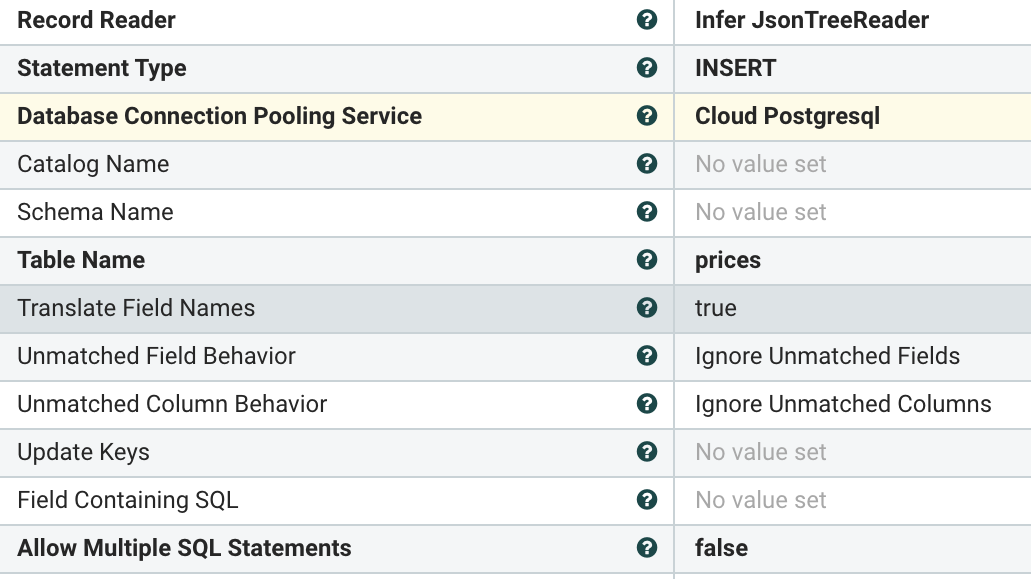
PutDatabaseRecord
From ApacheCon 2020, John Kuchmek does a great talk on Incrementally Streaming RDBMS Data.
Incrementally Streaming Slides
Resources
- https://www.datainmotion.dev/2019/10/migrating-apache-flume-flows-to-apache_15.html
- https://github.com/tspannhw/EverythingApacheNiFi/blob/main/README.md
- https://www.youtube.com/watch?v=XsL63ZQYmLE
- https://community.cloudera.com/t5/Community-Articles/Change-Data-Capture-CDC-with-Apache-NiFi-Part-1-of-3/ta-p/246623
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-cdc-mysql-nar/1.5.0/org.apache.nifi.cdc.mysql.processors.CaptureChangeMySQL/
- https://dzone.com/articles/change-data-capture-using-apache-nifi
- https://www.linkedin.com/pulse/building-near-real-time-big-data-lake-part-2-boris-tyukin/
- https://www.qlik.com/us/data-management/nifi
- https://www.cloudera.com/tutorials/cdp-importing-rdbms-data-into-hive.html
- https://www.cdata.com/kb/tech/oracledb-jdbc-apache-nifi.rst
- https://nathanlabadie.com/apache-nifi-ms-sql-and-kerberos-authentication/
- https://dzone.com/articles/lets-build-a-simple-ingest-to-cloud-data-warehouse
- https://github.com/tspannhw/EverythingApacheNiFi#etl--elt--cdc--load--ingest
- https://www.linkedin.com/pulse/2020-streaming-edge-ai-events-tim-spann/
- https://github.com/tspannhw/ApacheConAtHome2020
That's it. Happy Holidays!


Top comments (0)