
When we started with the Litmus project, we defined a sub category in Chaos Engineering called Cloud Native Chaos Engineering and assigned some architectural goals for building a generic stack around this category. They are published here. As we spent more time with the Litmus community and as the new technologies such as GitOps evolved around cloud native, we updated the core chaos engineering principles around which Litmus has evolved into a fully featured platform to practice end-to-end chaos engineering for cloud native services and applications.
The first version started with four principles - Open source, Chaos APIs/CRDs, Plugins and Community Chaos. We realised that the principle around Plugins is more about integration into other DevOps tools and can be realised by having a good API. During the evolution of chaos community, we observed two additional patterns:
- Observability and chaos engineering are closely related and
- Scaling of chaos engineering or automation of chaos engineering is an important aspect
With these observations, we defined the following five cloud native chaos engineering principles:
- Open source
- Community collaborated experiments
- Open API and chaos life cycle management
- Scaling and automating through GitOps
- Observability through generic chaos metrics
Open Source
Cloud native communities and technologies have been revolving around open source. Chaos engineering frameworks being open source in nature benefit in building strong communities around them and help them make them more comprehensive, rugged and feature-rich.
Chaos Experiments as Building Blocks
Chaos experiments need to be simple to use, highly flexible and tunable. Chaos experiments have to be rugged, with little or no chance of resulting in false negatives or false positives. Chaos experiments are like Lego blocks: You can use them to build meaningful chaos workflows.
Manageable Chaos Experiments and API
Chaos engineering has to employ well-known software engineering practices. Managing chaos scenarios can quickly become complex, with more team members getting involved, more changes happening frequently and the requirements being altered. Upgrading chaos experiments becomes common. The chaos engineering framework should enable management of chaos experiments in an easy and simple manner, and should be done in the Kubernetes way. Developers and operators should think of chaos experiments as Kubernetes customer resources.
Scale Through GitOps
Start with low-hanging fruit in terms of obvious and simple issues. As you start fixing them, chaos scenarios become more comprehensive and large; the number of chaos scenarios also increases. Chaos scenarios need to be automated or need to be triggered when a change is made to the applications of the service. Tools around GitOps may be used to trigger chaos when a configuration change happens to either application or chaos experiments.
Open Observability
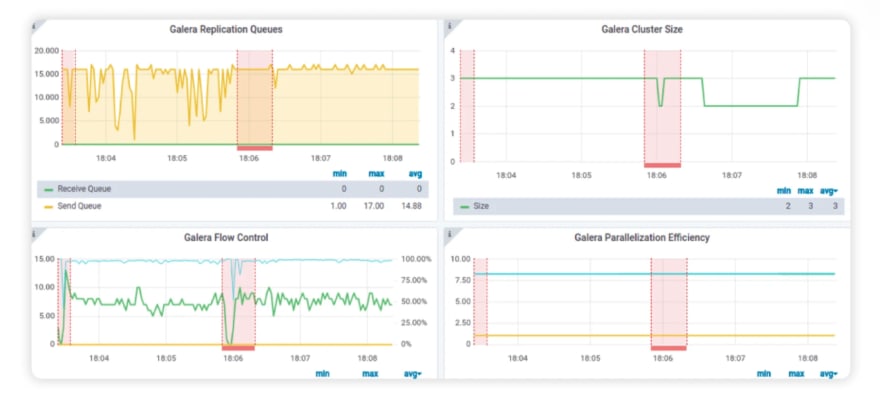
Observability and chaos engineering go together when fixing issues related to reliability. There are many observability stacks and systems that are well-developed and put into practice. Introduction of chaos engineering should not require a new observability system. Rather, the context of chaos engineering should fit nicely into the existing system. For this, chaos metrics from the system where chaos is introduced are exported into the existing observability database, and the context of chaos is painted on to the existing dashboards. The below dashboard consists of red chaos rectangles to depict the chaos periods, making the chaos context very clear to the user.
LitmusChaos 2.0
Litmus recently achieved 2.0 GA status with all the principles of cloud native chaos engineering implemented in it. Litmus makes the practice of chaos engineering easy. Get started with Litmus here.

Latest comments (0)