
Text is simpler than it looks!
Every developer hits a wall working with text sooner or later, and diving into the complexity of manipulating it correctly can easily scare people away.
Why can't we have nice things?
Unicode greatly simplifies working with text by providing a standard representation, but it isn't used everywhere. UTF-8 is the most popular character encoding scheme, but, you guessed it, it also isn't used everywhere. For historic reasons, UTF-16 remains the default in JavaScript, Java, C#, Windows, Qt, and the ICU project. Visit http://utf8everywhere.org/ to find out more.
UTF-8 vs ASCII, UTF-16, UTF-32
Before jumping into UTF-8, here's a quick comparison with other encoding schemes:
- UTF-8 is backwards compatible with ASCII, so everything in ASCII is already in UTF-8
- ASCII encodes only 128 characters, which is a tiny fraction of Unicodes' 143,859 in v13.0
- UTF-8 uses one to four 8-bit code units, giving it plenty of room for any additions to Unicode
- UTF-16 uses one or two 16-bit code units
- UTF-32 uses a single 32-bit code unit
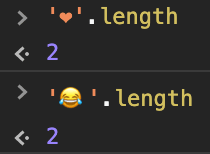
Isn't UTF-16 safe in most cases?
No. Consider the two most frequent emoji used in Twitter, ❤️ and 😂. While most characters will be treated as having a length of one, both of these emoji occupy two UTF-16 units. Example in JavaScript:
Can't we just use UTF-32?
UTF-32 is inefficient and increases the space required to store text. Contrary to common expectations, UTF-32 also isn't a silver bullet for manipulating text. While it is fixed-width, it only represents a single Unicode code point, and many characters like emoji, for example, consist of a combination of code points. Example in JavaScript:
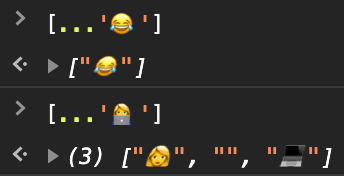
Code points ≠ characters
Many characters can be represented with a single code point, however, there are also many characters that span multiple code points.
For example, in Thai there are different tonal and vowel marks, อ อี อี้ อู้, which all consist of separate code points and can be typed and erased separately:

Different emoji also consist of combinations and variations:

If these aren't code points, then what are they? Find out more about grapheme clusters here.
How is UTF-8 stored?
UTF-8 encodes characters into one to four bytes and uses prefix bits to differentiate them. It can encode all characters in the range, U+0000..U+10FFFF (limited by the UTF-16 range).
(x represents code point bits)
0xxx-xxxx 1-byte sequence, 7-bit value
110x-xxxx 10xx-xxxx 2-byte sequence, 11-bit value
1110-xxxx 10xx-xxxx 10xx-xxxx 3-byte sequence, 16-bit value
1111-0xxx 10xx-xxxx 10xx-xxxx 10xx-xxxx 4-byte sequence, 21-bit value
Converting to UTF-32:
UTF-8 | UTF-32
---------------------------------------------------------------------
0ABC-DEFG | 0000-0000 0000-0000 0000-0000 0ABC-DEFG
110A-BCDE 10FG-HIJK | 0000-0000 0000-0000 0000-0ABC DEFG-HIJK
1110-ABCD 10EF-GHIJ 10KL-MNOP | 0000-0000 0000-0000 ABCD-EFGH IJKL-MNOP
1111-0ABC 10DE-FGHI 10JK-LMNO 10PQ-RSTU | 0000-0000 000A-BCDE FGHI-JKLM NOPQ-RSTU
Byte prefixes:
-
0- 1-byte sequence -
110- start of 2-byte sequence -
1110- start of 3-byte sequence -
11110- start of 4-byte sequence -
10- UTF-8 continuation byte
It's not very common to have to implement UTF-8 iteration from scratch, given that there are well tested open-source solutions out there. However, it's still a useful exercise to understand how it works. Here's an example of UTF-8 iteration in C++:
constexpr auto UTF8UnitMasks = std::array{
0b0011'1111, 0b0111'1111, 0b0001'1111, 0b0000'1111, 0b0000'0111};
int getUTF8Prefix(uint8_t c) {
if (c < 0b1000'0000) return 1; // 1-byte (ASCII)
else if (c < 0b1100'0000) return 0; // continuation
else if (c < 0b1110'0000) return 2; // 2-byte
else if (c < 0b1111'0000) return 3; // 3-byte
else if (c < 0b1111'1000) return 4; // 4-byte
else return -1; // invalid
}
// Returns the current code point and increments textBegin to the next one
int32_t nextUTF8(const char** textBegin, size_t size) {
if (!textBegin || !size) return -1;
auto& data = *reinterpret_cast<const unsigned char**>(textBegin);
auto units = getUTF8Prefix(data[0]); // count code point units
if (units < 1 || units > size) {
++data;
return -1;
}
// verify all subsequent units are continuation bytes, getUTF8Prefix(c) == 0
if (std::any_of(data + 1, data + units, getUTF8Prefix)) {
++data;
return -1;
}
auto value = int32_t(data[0]) & UTF8UnitMasks[units];
for (int i = 1; i < units; ++i) {
value = (value << 6) + (data[i] & UTF8UnitMasks[0]);
}
data += units;
// check for Unicode range and overlong encoding (e.g, ASCII in 2+ bytes)
switch (units) {
case 1: return value;
case 2: return value >= (1 << 7) ? value : -1;
case 3: return value >= (1 << 11) ? value : -1;
case 4: return value >= (1 << 16) && value <= 0x10FFFF ? value : -1;
default: return -1;
}
}
void example() {
auto text = std::string_view("สวัส\xFFดีครับ!"); // Hello in Thai + invalid
for (auto begin = text.begin(); begin < text.end();) {
std::cout << nextUTF8(&begin, text.end() - begin) << " ";
}
std::cout << std::endl;
// Output: 3626 3623 3633 3626 -1 3604 3637 3588 3619 3633 3610 33
// ^ 0xFF - invalid code point
}
This post only scratches the surface, but should help demystify some of the foundational bits.

Top comments (1)
hi martin, you see this project:
charcuterie.elastiq.ch/
😎