If you have spent any time with CoreData you will have opinions.
I personally love it. It's a simple persistence layer with graphical modelling and relationship resolution. The current NSPersistentContainer API can be spun up in just a few lines of code. The team who make it clearly like it too and every year brings a fresh crop of improvements.
You do need to realise that CoreData is not an SQLite database. While the default mode is to store your data in a SQLite file that's just an implementation detail. CoreData is also not a relational database so don't treat it like one.
One activity that can strike fear into even the most veteran developer is upgrading your xcdatamodel. Simple changes like addition of properties are very easy but more complex changes like modifying relationships can be difficult particularly when you have multiple model versions to deal with. No-one wants to lose client data.
In reality using the automated model upgrade system by using the upgrade toggle in your persistent store when you is mostly easy and transparent.
let container = NSPersistentContainer(name: "Unicorn")
let url = //url to store file
let store = NSPersistentStoreDescription(url: url)
store.shouldMigrateStoreAutomatically = true
store.shouldInferMappingModelAutomatically = true
container.persistentStoreDescriptions = [store]
container.loadPersistentStores { (storedesc, error) in
//do data dependant setup
}
You can set shouldMigrateStoreAutomatically & shouldInferMappingModelAutomatically to true and move on with your day.
How do you deal with updating your model without introducing an new xcdatamodel version? If you prepare in advance you can add a little bit of wriggle room to your entities to avoid a dreaded model upgrade.
You use the Bucket of Goo™ technique. You add a place in your entity to store a generic Dictionary and store synthetic properties in that dictionary. This is not quite an anti-pattern, but it's not very scalable as there are costs both direct and in the form of technical debt. Still it might get you out of a temporary hole.
The first thing to do is add an metadata attribute to your Entity of type Data. You'll also see why you don't want to use String as the type.
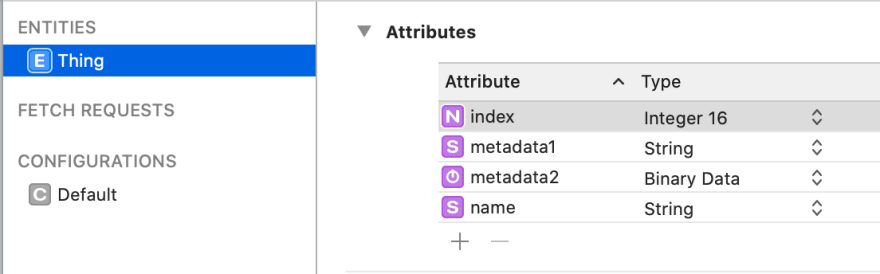
Either the autogenerated class files or one that you create for yourself will look something like this
class Thing: NSManagedObject {
@NSManaged var name: String?
@NSManaged var index: Int16
@NSManaged var metadata1: String?
@NSManaged var metadata2: Data?
}
All the properties are expressed as @NSManaged to bind them into Objective-C runtime and KVO mechanics.
Next you want to provide simple access to your synthetic dictionary.
var metadataDictionaryString: SwiftDict {
get {
let string = metadata1
if let dict = string?.propertyList() as? SwiftDict {
return dict
}
return [:]
}
set {
let string = (newValue as NSDictionary).description
metadata1 = string
}
}
Don't use this snippet. It's included to show you what an idiot past me was. It relies on the fact that description used to generate a valid plist for NSString,NSDictionary and NSArray. Thats no longer the case and types such as Data will crash at runtime.
The way to implement synthetic properties is to use Data for your bucket type and PropertyListSerialization to shuttle in and out.
var metadataDictionaryData: SwiftDict {
get {
if let data = metadata2 {
do {
let dict = try PropertyListSerialization.propertyList(from: data, options: [], format: nil) as? SwiftDict
return dict ?? [:]
}
catch {
print("plist decode err - ",error)
}
}
return [:]
}
set {
do {
let data = try PropertyListSerialization.data(fromPropertyList: newValue, format: .binary, options: 0)
metadata2 = data
}
catch {
print("plist encode err - ",error)
}
}
}
The next step is to synthesise your new unexpected attribute. Lets call it extendedName.
extension Thing {
@objc var extendedName: String? {
get {
return metadataDictionaryData["extendedName"] as? String
}
set {
metadataDictionaryData["extendedName"] = newValue
}
}
}
You now have a new attribute in your model without needing to burn an xcdatamodel generation.
What's the cost?
The cost is:
- Time to use. Each request needs to shuffle in or out of a
Datablob. - CPU Cycles == Power consumption.
- Not accessible via
NSFetchRequest, i.e not searchable. - Possible tech debt from not doing it correctly first.
Taking a short test on macOS you can see
To access and update name which is a property on the entity Thing.
0.00485 s to add 1000 items
0.00513 s to update 1000 items
0.00657 s to read 1000 items
To access and update extendedName which is the synthetic property backed by metadata2
0.02022 s to add extended 1000 items
0.03116 s to update extended 1000 items
0.01254 s to read extended 1000 items
- Add operations are ~5x more expensive.
- Update is ~6x more expensive.
- Read is ~2x more expensive.
Can you mitigate this?
In write-few/read-many situations you can use a cache. This does however increase your memory footprint.
fileprivate var metadata2Cache: SwiftDict?
var metadataDictionaryData: SwiftDict {
get {
if let cache = metadata2Cache {
return cache
}
if let data = metadata2 {
...
}
return [:]
}
set {
do {
let data = ...
metadata2 = data
metadata2Cache = nil
}
catch {
print("plist encode err - ",error)
}
}
}
Load the cache on first get and burn it down on any set.
Take a look at the difference.
**0.02022 s to add extended 1000 items
**0.03116 s to update extended 1000 items
**0.01254 s to read extended 1000 items
**0.00972 s to read extended 1000 items
**0.00840 s to read extended 1000 items
First read needs to decode the Data blob but subsequent reads come out of the cache and are about ~1.25x more expensive than a native attribute.
Conclusions
You can avoid a model upgrade by dumping attributes into synthetic version but there are large disadvantages in terms of processing cost. This technique would not be suitable for a performance sensitive loop.
You might be able to dig yourself out of a hole with this technique but don't rely on it as a long term expansion strategy. Create new model generations.

Top comments (0)