 Which One to Take? WHY NOT BOTH!
Which One to Take? WHY NOT BOTH!
Data science and artificial intelligence might be the hottest topic in tech right now, and rightfully so. There are tremendous breakthroughs both on application level and research fields. This is a blessing, and a curse, at least for students and enthusiasts that want to break into this area. There are too many algorithms to learn, too many coding/engineering skills to hone, and way too many new papers to keep up with even if you felt you’ve mastered the art.
The journey is long, the learning curve is steep, the strife is real, yet the potential is so great people still flock into it. The good thing is we also have great educators and instructors working on mitigating the pain and make the process a little less harsh and a bit more fun. We’ll explore two of the greatest among them and share a potentially effective approach to help you swim through the sea of Data Science a bit happier.
AI Learning ‘Burn-out’
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--WcHFkmVk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/6552/0%2AvniRBklRl5-vxXQU)
If you list what one needs to learn to become an ‘OK’ data scientist or machine learning engineer, it could be scarily long:
Math: Linear Algebra, Calculus, Statistics, Algorithms, …
Coding: Python, R, SQL/NoSQL, Hadoop, Spark, Tensorflow/PyTorch, Keras, Numpy, Pandas, OpenCV, Data Visualization…
**Algorithms: **Linear Regression, Logistic Regression, Support Vector Machine, PCA, Anomaly Detection, Collaborative Filtering, Neural Network, CNN, RNN, K-Means, NLP, Deep Learning, Reinforcement Learning, AutoML, …
**Engineering: **Command Line, Cloud platform(AWS, GCP, Asure), DevOps, Deployment, NGINX/Apache, Docker…
The list can easily make the head spin for a person just entering the filed. Yet, it is still just scratching the surface. Some people make an ambitious plan(Siraj Raval’s plan is great btw) and dive right into it. Some lost momentum and felt totally under the water and the exit is nowhere to be seen. What went wrong?
You ‘Overfit’ Yourself
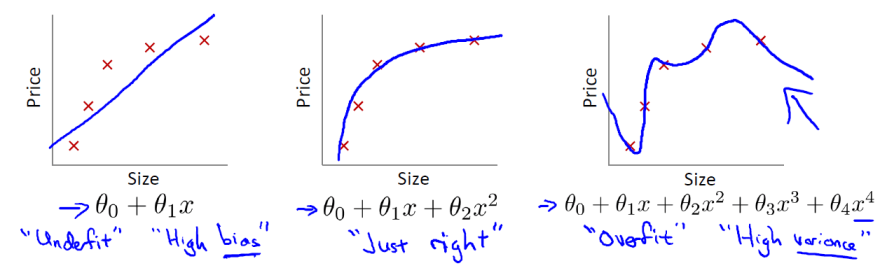 From Andrew Ng’s Machine Learning course
From Andrew Ng’s Machine Learning course
Overfitting is a very familiar idea for anyone that knows a bit of Machine Learning. It basically means your algorithm learned ‘too much’ of the data and buried itself into the little details of the data-set and missing the big picture. Come to think of it, sometimes when we learn something, we dive so deep we forgot why we were learning it and how it will fit into the big picture. It’s something I’d like to call ‘overfitting’ your own learning. This happens especially often for people coming from academia background. A math Ph.D. tends to make sure all the theorems are fully understood before proceeding to the next one. This is great for learning math. Have a profound understanding of theories will give you great intuition and confidence. It will enable you to see patterns and issues people without the training cannot see easily, yet Data Science demands more.
Theory aside, there is also a practical part to it. A properly applied algorithm coupled with efficient codes, carefully tuned hyper-parameters, and well-designed pipeline will usually achieve decent results, but not algorithm alone. Delve down too deep into theory, and you risk missing the practical side of the learning. It’s equally important to accumulate experiences on how to implement what you learned and handle real-life complexities. How to address this? Entering deeplearning.ai and fast.ai courses.
Deeplearning.ai and Fast.ai
A lot of courses have been developed to help navigate people through the learning process. Among them, Deeplearning.ai and fast.ai are two unique ones that have their own approaches and can give us some insights into a potentially effective way of learning Data Science.
deeplearning.ai

deeplearning.ai is a paid course developed by Andrew Ng. Like his other courses, it is known for its well-designed learning curve, calm and smooth teaching style, and challenging while fun assignments. It is well accepted as the Deep Learning course one cannot go wrong with. It starts from the fundamental theories and works its way up on how to put all the pieces together to solve real-life problems. It’s also called a ‘Bottom-up’ approach.
fast.ai

fast.ai is introduced by Jeremy Howard and Rachel Thomas as a free course to teach people with basic coding experience state-of-the-art deep learning techniques. Without much explanation of the underlying theories, with very few lines of code, student of fast.ai is capable of achieving astoundingly great results on its own domain quickly into the lessons. (I built a Chinese Calligraphy Style Classifier that reaches 96% accuracy rate and deployed it on the cloud after finishing lesson 1 of fast.ai course.) It teaches you how to tackle the real-world problem first, then digs deeper and deeper into how and why things work. It’s also called a ‘Top-down’ approach.
Which One is the Best Approach? Both!
So ‘Bottom-up’ and ‘Top-down’, which one is better? Which one should we take? The answer is Both!
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--ohH_btPO--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/9000/0%2A0E2S0M23a9GtlOfI)
See, these two courses complement each other. Say you start from Andrew Ng’s deeplearning.ai course, you buried yourself into endless formulas and theories, you gained a lot of intuition, but after weeks of learning, you still have nothing to show to your friends and not quite sure when you can apply your newly gained knowledge. Your study on the machine learning fundamentals is getting diminishing returns. Your brain slows down and you start to feel boring. Now is the perfect time to start taking a lesson or two of the fast.ai course. With the help of the powerful fast.ai library and few lines of code, you’ll be able to build impressive models that solve real-life problems and even beat some state-of-the-art papers and Kaggle competitions. This will give your brain a totally different kind of stimulation and your heart more confidence and passion to delve deeper into why everything works. Once you built a couple of projects and ‘wow’ed your friends, you will be more motivated to learn more about the fundamentals, then you can go back to deeplearning.ai course and keep your study there. These two courses push each other forward, you can just rinse and repeat till you finished both.
This forms a perfect learning circle.
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--DuC-yctx--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/9688/0%2AY-6oyPq53_8ppU0o)
The best thing about taking both courses this way is once you finished both, you’ll be fully prepared. You have tons of projects built along the way from fast.ai course to showcase to potential employers and you also have the deep knowledge of how everything works or even published one paper or two to show your findings. You are now a well-rounded Data Scientist. How cool is that?

Top comments (0)