Scaling Postgres RDS
Multiverse
The Many-worlds interpretation is quantum mechanics theory that asserts there is a multiverse. Hugh Everett, a physicist, developed this theory to solve the wave function collapse issue when an observer measures a quantum particle.
Bottleneck
The database is one of the most common bottlenecks that the Engineering Team faces.
We always want to provide an extensive database with a lot of resources.
But optimize too soon, and you will end up optimizing two times!
Nevertheless, at a certain point, IT Team has no choice but to scale up their databases. Scaling can be done in two different dimensions, horizontal and vertical.
This article will dive into these two manners of scaling our database. This is part of a Series about AWS RDS. Do not hesitate to check the other one to have more context.
Universe A: Scaling Vertically
In the first universe, we are in a situation where our RDS database faces a lot of write, but few reads. Recently customers have struggled to register due to the pick of customer registration.
In this situation, we prefer to scale our database vertically. Vertically scaling our database means giving it more resources to work with.
This could mean more CPU, more memory more storage. But also increasing read and write velocity on the disk.
We are building a one could say a bigger machine for our database.
Let's say you have a t3.micro database in RDS; you can vertically scale your database by creating a t3.medium, for example.
resource "aws_db_instance" "db-test1" {
allocated_storage = 10
identifier = "postgres-test2"
db_subnet_group_name = aws_db_subnet_group.default.id
engine = "postgres"
engine_version = "14"
instance_class = "db.t3.medium" ##"db.t3.micro"
username = "postgres"
password = "postgres"
vpc_security_group_ids = [aws_security_group.allow_tls.id]
skip_final_snapshot = true
}
That's it. You have vertically scaled your instance. There are other parameters to tweak, and modifying them will also be a part of Vertically Scale.
Universe B: Horizontal Scaling
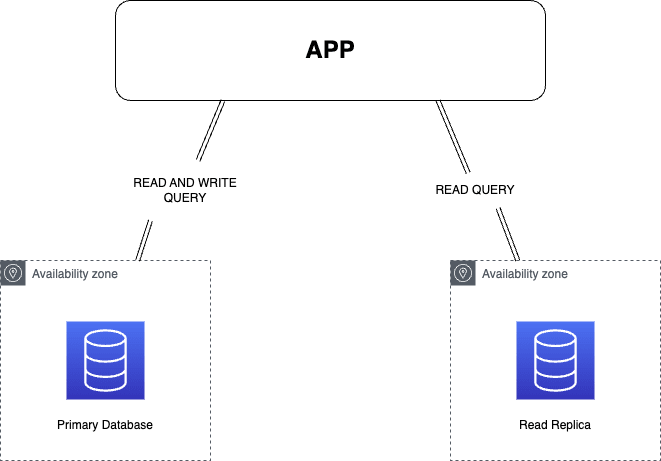
In this second universe, we are a completely different situation; we have a database much more solicited for reading than writing.
This schema is generalist, there are two different AZ on this schema, but it can be the same.
resource "aws_db_instance" "db-master" {
allocated_storage = 10
identifier = "postgres-test2"
db_subnet_group_name = aws_db_subnet_group.default.id
engine = "postgresql"
engine_version = "14"
instance_class = "db.t3.medium"
username = "postgres"
password = "postgres"
vpc_security_group_ids = [aws_security_group.allow_tls.id]
publicly_accessible = true
skip_final_snapshot = true
maintenance_window = "Mon:00:00-Mon:03:00"
backup_window = "03:00-06:00"
backup_retention_period = 1
}
resource "aws_db_instance" "db-read" {
allocated_storage = 10
identifier = "postgres-test-read"
replicate_source_db = aws_db_instance.db-test1.identifier
engine = "postgres"
engine_version = "14"
instance_class = "db.t3.micro"
username = ""
password = ""
vpc_security_group_ids = [aws_security_group.allow_tls.id]
publicly_accessible = true
skip_final_snapshot = true
backup_retention_period = 0
}
We need to deploy another aws_db_instance to deploy our Postgres database read replica. First, you will need a few specificities,
On the primary instance :
maintenance_windowbackup_window-
backup_retention_period
Why are these necessary? I did not manage to find the profound reason why yet. But if you have an idea or a response, I would love to hear about it!
[Edit] : To create a database read replica, AWS needs to create a snapshot of your main database. This will be automated by creating a backup retention period to something else than 0.
On the read replica instance :
- the
replicate_source_dbis the source database for the replication on this read replica. - Not specifying any username or password
Deploying read replicas on AWS RDS are straightforward; we need to avoid the pitfall of some tweak to deploy it.
Conclusion
After our little adventure in the multiverse, we have seen that Vertical and Horizontal scaling responds to two different use cases. We can apply either or both of these strategies on AWS RDS relatively quickly, even if there are pitfalls.
If you want to see the whole file, you can check it out here on this gist
Keep in Touch
On Twitter : @yet_anotherDev
On Linkedin : Lucas Barret

Top comments (0)