In this post we'll talk about Processes in Postgres as well as Memory Management.
Process Management
Postgres uses a collection of processes usually referred to as a PostgreSQL server to manage a database database cluster.
It contains the following types of processes:
- A postgres server process is a parent of all processes related to a database cluster management.
- Each backend process handles all queries and statements issued by a connected client.
- Various background processes perform processes of each feature (e.g., VACUUM and CHECKPOINT processes) for database management.
- In the replication associated processes, they perform the streaming replication.
- In the background worker process supported from version 9.3, it can perform any processing implemented by users.
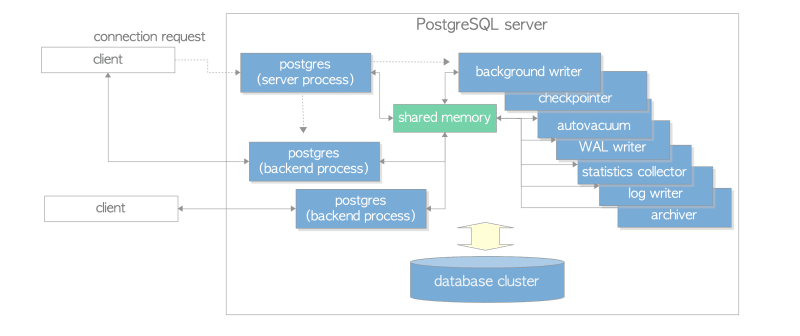
Postgres Server Process
The parent of all in a PostgreSQL server. In the earlier versions, it was called postmaster.
By executing the pg_ctl utility with start option, a postgres server process starts up.
- Allocates a shared memory area in memory.
- Starts various background processes.
- Starts replicating associated processes and background worker processes if necessary.
- Waits for connection requests from clients. On receiving a connection request from a client, it starts a backend process (which handles all queries issued by the connected client.)
A postgres server process listens to one network port, the default port is 5432. Although more than one PostgreSQL server can be run on the same host.
Backend Processes
A backend process, (also called postgres), is started by the postgres server process and handles all queries issued by one connected client. It communicates with the client by a single TCP connection, and terminates when the client gets disconnected.
As it is allowed to operate only one database, you have to specify a database you want to use explicitly when connecting to a PostgreSQL server.
PostgreSQL allows multiple clients to connect simultaneously; the configuration parameter max_connections controls the maximum number of the clients (default is 100).
If many clients such as Web applications frequently repeat the connection and disconnection with a PostgreSQL server, it increases both costs of establishing connections and of creating backend processes because PostgreSQL has not implemented a native connection pooling feature. Such circumstance has a negative effect on the performance of database server. To deal with such a case, a pooling middleware (either pgbouncer or pgpool-II) is usually used.
Background Processes
Here are the detailed description of some processes.
| process | description |
|---|---|
| background writer | Writes dirty pages on the shared buffer pool gradually and regularly to a persistent storage. (In version 9.1 or earlier, it was also responsible for checkpoint process.) |
| checkpointer | (version 9.2+) Performs checkpointing. |
| autovacuum launcher | The autovacuum-worker processes are invoked for vacuum process periodically. |
| WAL writer | Writes and flushes periodically the WAL data on the WAL buffer to persistent storage. |
| statistics collector | Collects statistics information such as for pg_stat_activity and for pg_stat_database, etc. |
| logger | Writes error messages into log files. |
| archiver | Archiving logging. |
Memory Management

Memory architecture in PostgreSQL can be classified into two broad categories:
1. Local memory area
Each backend process allocates a local memory area for query processing; each area is divided into several sub-areas – whose sizes are either fixed or variable.
| sub-area | description |
|---|---|
| work_mem | Executor uses this area for sorting tuples by ORDER BY and DISTINCT operations, and for joining tables by merge-join and hash-join operations. |
| maintenance_work_mem | Some kinds of maintenance operations (e.g., VACUUM, REINDEX) use this area. |
| temp_buffers | Executor uses this area for storing temporary tables. |
2. Shared memory area
A shared memory area is allocated by a PostgreSQL server when it starts up, and is used by all processes of a PostgreSQL server. This area is also divided into several fix sized sub-areas.
| sub-area | description |
|---|---|
| shared buffer pool | PostgreSQL loads pages within tables and indexes from a persistent storage to here, and operates them directly. |
| WAL buffer | Buffering area of the WAL data before writing to a persistent storage. To ensure that no data has been lost by server failures. |
| commit log | Commit Log (CLOG) keeps the states of all transactions (e.g., in_progress, committed, aborted) for Concurrency Control (CC) mechanism. |
In addition to them, PostgreSQL allocates several other areas such as:
- Sub-areas for the various access control mechanisms. (e.g., semaphores, lightweight locks, shared and exclusive locks, etc)
- Sub-areas for the various background processes, such as checkpointer and autovacuum.
- Sub-areas for transaction processing such as save-point and two-phase-commit.

Top comments (0)