History
Kubernetes is lovely! I have built and shipped many applications to production using Kubernetes. The one thing I could not wrap my head around was the configuration. Each time I built a project, I would just copy repetitive configuration from my previous projects, and if I was trying something new, I would have to scour the internet till I came across a piece of configuration that matched what I was looking for. This was a terrible developer experience, and that is when I found Datree, a magical tool for preventing Kubernetes misconfigurations from reaching production.
Introduction
I have written a configuration policy for Datree. In this post, I will be sharing my experience about building a policy for Datree and reflecting upon the policy I built along with my final thoughts about Datree. The name of my policy is Horizontal Pod Autoscaler, and the policy can be found here.
About the Policy
My policy is about the Kubernetes component Horizontal Podautoscaler. If you're unfamiliar with what Horizontal Podautoscaler is, it is a Kubernetes component that automatically updates resources like a Deployment or StatefulSet. It does this horizontally, by increasing the number of pods, in response to the load. Coming back to my policy, my policy provides safety around building a Kubernetes configuration which aims to use Horizontal Podautoscaler to scale the application. Now, one could make a policy for absolutely any use case, but I chose to build a policy for the Horizontal Podautoscaler because this policy allows Kubernetes engineers to actually work on reducing costs and scaling their pods rather than ensuring correct configuration.
Policy Rules
Each Datree policy has a bunch of rules. A rule is, essentially, something for which you want to check some piece of configuration for. My policy has 4 rules, indicating that it checks 4 pieces of configuration. The rules in my policy have been laid out as follows:
Ensure target CPU utilization is set: This rule checks for the field targetCPUUtilizationPercentage which defines the target for when the pods are to be scaled. CPU Utilization is the average CPU usage of all pods in a deployment divided by the requested CPU of the deployment. If the mean of CPU utilization is higher than the target, then the pod replicas will be readjusted.
Ensure max replicas are set and valid: This rule checks for the field maxReplicas which is vital because it sets the maximum number of Pod replicas for the autoscaler. It is a value between 1 and 10.
Ensure min replicas are set and valid: This rule checks for the field minReplicas which defines the minimum number of replicas of a resource. As a best practice, it should be set to two, hence the minimum minReplicas one can set it to would be 2.
Ensure scale target ref is configured properly: This rule checks for the configuration of the field scaleRefTarget. The rule also checks for subfields like kind and apiVersion.
Testing the Policy
Getting started with Datree is fairly simple. You can read about it here. I won't get into it right now, but rather focus on just testing my policy in a sample Kubernetes project. To start off, you need the Datree CLI installed. After that, just test the policy using datree test manifest.yaml. Here is how the output looks:
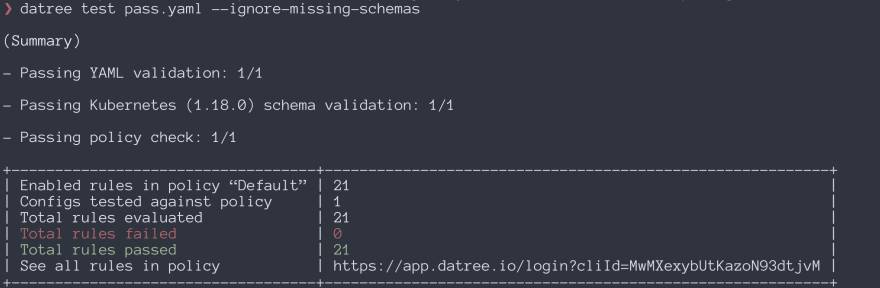
As you can see in the above image, the Datree CLI provides you with a complete summary of the policy. In our case, all of the rules were passed.
Conclusion
Overall, I'd say I learned a lot while building this policy. Not only did I experiment with configuration policies and Datree, but I also learned a great ton about YAML and Kubernetes. Finally, Datree is brilliant to use in production; it really enhances your productivity and boosts your workflow. After building a few policies and pushing some code to production, it really does the work and prevents K8s misconfigurations from reaching production.

Top comments (0)