
Author: Ed Huang (Co-Founder & CTO at PingCAP)
This post is the first part in our series. You can see the second part **here: *Long Live MySQL: Kudos to the Ecosystem Innovators***.
Imagine you’re an application developer, and your manager tells you to prototype a new application in a week. What would you choose for your database? Probably MySQL.
MySQL is ubiquitous
Many engineers love MySQL. DB-Engines reports MySQL is the second most popular database; however, some other databases, such as SQLite and IBM Db2, are decreasing in popularity.
Database popularity ranking according to DB-Engines
From the 73,317 responses of Stack Overflow’s 2021 Developer Survey, MySQL ranked as the most popular database.

Database popularity ranking according to Stack Overflow’s 2021 Developer Survey
MySQL is also popular when it comes to hiring. I searched for jobs on Indeed with the keywords of top used databases, and there were 31,245 jobs returned for “mysql.” Job openings that require a “mysql” skillset are the second highest among the top databases.
MySQL is ubiquitous. In fact, at PingCAP, MySQL was one of the few databases a lot of our engineers knew how to use before they joined PingCAP. I was one of them.
My 20 years with MySQL
I used MySQL for the first time when I was a high school student in 2003. Back then, I wanted to develop a web application (Online Judge) with PHP for programming competition hobbyists and help them run their code and check whether it was correct. To store the data users submitted, I needed a database. MySQL was my best choice because it was so straightforward and user friendly. I could use MySQL client to write SQL and operate the database in PHP directly and then Apache rendered the dynamic page results.
In 2012, I joined a startup company whose infrastructure was based on MySQL. I was one of the few infrastructure engineers. The company business grew so fast, its data volume soon spiked beyond MySQL’s single-machine capacity. So I began to seek solutions. For example, I used MySQL binlog for highly available primary and secondary layers and applied horizontal sharding. When I left that company, its database cluster had more than 30 shards which could hold dozens of terabytes. For me, solving these issues was a very fulfilling experience.
Because of these MySQL-related experiences, I had the opportunity to meet many excellent engineers who had similar memories working with MySQL. In 2015, when I decided to start my own business and build a brand new database, MySQL was the first ecosystem that popped into my mind.
Why so many people love MySQL
MySQL’s popularity is unquestionable, although its earlier versions were not as advanced as what we see today. The secret sauce behind its popularity is that MySQL is simple and easy to use. Many user-friendly features like Binlog were introduced to MySQL early as well. As a result, the number of MySQL users grew dramatically in the following three decades. In addition, many users gave their feedback on using MySQL or contributed to MySQL directly, all of which led to a more prosperous MySQL ecosystem. In its heyday, MySQL became a natural choice for many businesses because:
- Many engineers are using it, making a large talent pool available for database companies.
- It is open-sourced, making it easy to obtain and use.
- You could find the answers to almost any MySQL question on the internet.
- It has a vibrant ecosystem. A large number of open source projects, such as WordPress and phpMyAdmin, heavily relied on MySQL and made it even more prevalent.
Things have changed
During the past 20 years, the world has been changing rapidly and we have witnessed many significant changes in technology such as the explosion of the mobile internet and today’s digital transformation. Our application scenarios have changed enormously as well. What are these changes? Let’s explore them from a data perspective.
Data volume increased exponentially, making distributed technology a must for almost all modern databases. NoSQL databases do a very good job of building a distributed architecture. They provide transparent scalability while maintaining consistent usage, so that developers can scale in and out without worrying about application change. However, NoSQL databases provide users with an even more limited set of functions than SQL databases. This was not a big problem in the early days of Web 2.0 because although data volume increased, business models were relatively simple. Take Twitter for example: in its earliest versions, it provided nothing more than a giant shared note service within a limit of 140 characters.
If enterprises plan to build complicated applications, especially those that require strong consistency and complex association analysis such as JOIN and GROUP BY, SQL is still their best option. Unfortunately, traditional relational databases including MySQL and PostgreSQL made few innovations for a long time even though they embraced distributed technology. They developed their databases for a single machine, making sharding the only mainstream solution to deal with distributed requirements. Recently, however, we have seen some new database projects that can be called real distributed SQL databases.
At first, data models evolved from complicated to simple, and then became even more complicated. This evolution comes with the significant change in technology like the mobile internet explosion. The then-prevalence of NoSQL and sharded databases made data modeling subject to a limited set of functions. For a while, data application modeling had to be simplified to key-value pairs, documents, and other flexible and simple models.
However, when the low-hanging fruit is picked, the really hard problems get trickier. As more industries such as financial services and e-commerce begin their digital transformation to accelerate their online business, the databases’ application scenarios are becoming more complicated. So, the relational model plus SQL is almost always our best database solution. In the last 10 years, we have seen many attempts to model data with new domain-specific languages (DSL)—GraphQL is one example—but I think none of them can shake the dominant place of a relational model plus SQL combination. Google described this situation succinctly in its research paper “F1: A Distributed SQL Database That Scales”:
"When we sought a replacement for Google’s MySQL data store for the AdWords product, that option was simply not feasible: the complexity of dealing with a non-ACID data store in every part of our business logic would be too great, and there was simply no way our business could function without SQL queries."
The demand has been increasing for stronger consistency and real-time transactional processing and analytics. In the early days, MySQL’s default storage engine was MyISAM, but eventually InnoDB took its place. I think one of the main differences is that InnoDB supports strongly consistent transactions. The more consistent semantics the database layer provides, the less complexity the application layer has to bear. This is especially true when you are dealing with failovers. If the database does not support strong consistency, it is difficult to guarantee data integrity when performing a disaster recovery. This is not acceptable in most financial scenarios.
In the last decade, there have been many innovations in database management technologies. However, one obvious trade off is the separation of Online Transactional Processing (OLTP) and Online Analytical Processing (OLAP). Streaming technologies such as Apache Kafka, Apache Storm, and Apache Spark have emerged to form the so-called “lambda architecture,” which combines the two systems and eliminates the latency of extract, transform, load (ETL). While this approach works in many situations, the architectural complexity introduced has been a tough nut to crack. It is also difficult to keep the data consistent on this head-scratching technology stack. This has caused great challenges for many businesses that require real-time insights at the minute or even millisecond level. Due to the technical barriers, companies might have to suppress their business needs and turn to solutions that are more traditional but easier to tame. As data volume and the demand of real-time analytics have risen in recent years, OLTP and OLAP are on the track of integration.
The way data is generated and consumed is becoming multifaceted. In the past, writing to a database was simple: the client connected directly to the DB through SQL statements. If you take a closer look at how data enters the DB today, you can see that the upstream is much more diversified; it could be a message queue or batch writing from an ETL job. The challenge for batch writing is that users normally care more about the throughput performance than whether the ACID isolation requirements are met. In such scenarios, traditional transaction mechanisms such as locking would be unnecessary. On the other hand, the dramatic rise in real-time requirements lead to the need for data change synchronization to a downstream message queue for consumption. Change Data Capture (CDC) has become a mainstream implementation for modern databases. For example, MySQL has Binlog, Oracle has GoldenGate, and PG has pg replication.
Data quality is increasingly required and the scope of observability extends from the execution panel to the data panel. Twenty years ago, most of our focus was on simple database system metrics such as queries per second (QPS), transactions per second (TPS), latency, and query plan level. With the dramatic increase in data volume and the emergence of distributed databases, we are not satisfied with basic system information; we want to observe how data is accessed, and from that, gain business insights. Take TiDB’s KeyVisualizer as an example. It reflects the distribution of data access in real time so that you can tell at a glance which data is frequently accessed and what are the characteristics of the access.
TiDB’s KeyVisualizer
However, these observability dimensions are still limited to the database system itself. Recently, a new trend has started to emerge: data observability, which tries to measure the quality of data. Anomalo is a good example, and I think this will be a very promising direction for database products.
The hardware infrastructure is changing dramatically. As the cloud is becoming more prevalent, managed services are becoming the mainstream. When MySQL was released, there were no SSDs or 20G NICs. The advances in hardware have alleviated many problems. For example, B+Tree solved the problem of the slow reads and writes of traditional mechanical disks; however, this is not an issue with modern NVMe SSDs. With wide adoption of modern cloud environments, shared storage solutions on the cloud, such as AWS EBS, perform as well, if not better, than local disks. This will profoundly change the design of database storage engines. On the other hand, database vendors and cloud providers can offer fully managed experience on the cloud, so that users won’t have to worry about operations and maintenance and can focus on the business development. This is also a reasonable business model for vendors providing database services on the cloud.
Is good old MySQL outdated?
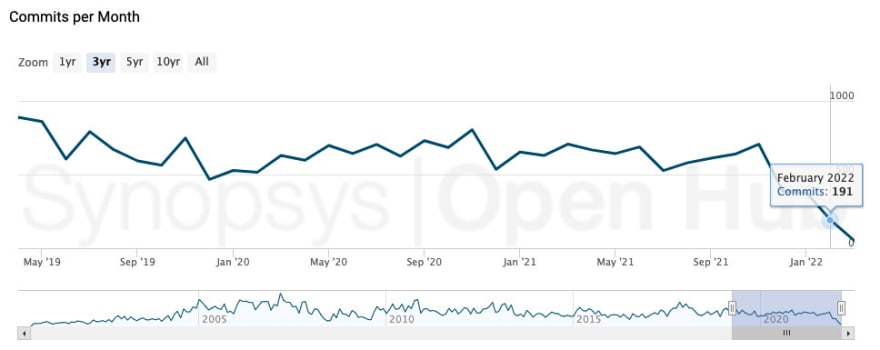
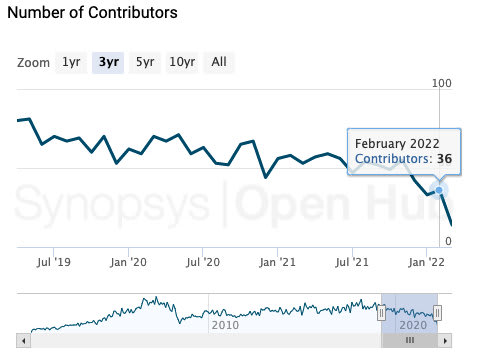
Having witnessed all those changes happening in the technology world, I could not help but think: is MySQL outdated? As a database kernel developer, I am more than concerned that the contribution from Oracle to MySQL is dwindling.

The growth trend of the number of MySQL contributors

MySQL’s commits trend during past 3 years
I don’t know what’s going on inside Oracle, and it would be great for them to make an explanation to the community.
Even so, I still love MySQL and its ecosystem. The MySQL ecosystem will not go away. MySQL applications and developers are still the foundations of the database market. But do we need a more modern MySQL? Absolutely yes. In my next post, I will share with you some major players in the modern MySQL ecosystem. Stay tuned.
This post is the first part in our series. You can see the second part here: *Long Live MySQL: Kudos to the Ecosystem Innovators***.

Top comments (0)