I've been building an open-source real-time voice AI workspace for the past few weeks and I want to walk through the architecture decisions that were actually hard — not the happy-path stuff you see in tutorials.
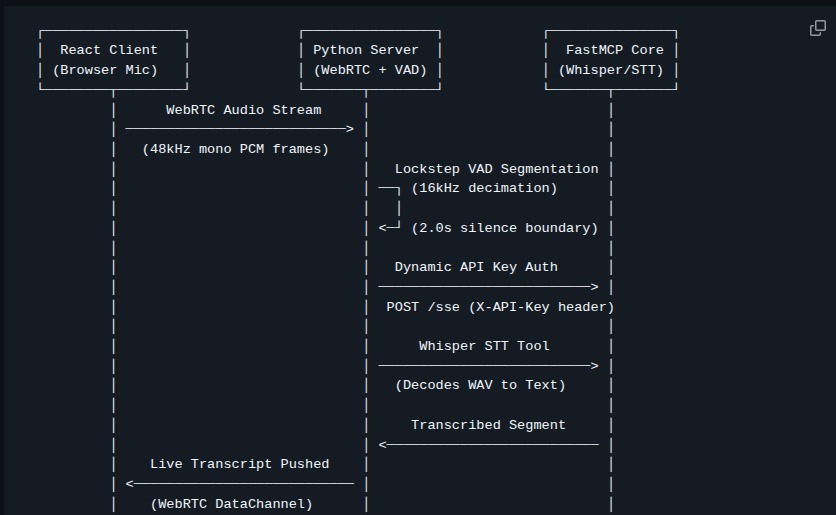
The stack: React client → WebRTC Python backend → FastMCP server (Whisper STT, Mail, Calendar) → transcript delivered back over a WebRTC DataChannel. The LLM orchestration layer is still in progress, but the pipeline underneath it is fully live and tested.
Here's what I want to focus on: three engineering decisions that weren't obvious.
The Problem With Securing Local Microservices
When two services run on the same machine — in this case the WebRTC server and the MCP server — the standard advice is to put them behind a shared secret or an API key stored in an environment variable. That works, but it has failure modes: leaked .env files, rotation pain, and the cognitive overhead of managing secrets across services that should be able to trust each other without a database call.
I wanted something stateless and self-expiring.
The solution I landed on is a time-locked hash generator. Both servers independently compute the same key by applying deterministic math to the current UTC timestamp divided by a 5-second epoch window:
import math, hashlib, time
def generate_api_key() -> str:
epoch_window = int(time.time()) // 5
raw = math.sqrt(math.log10(epoch_window))
return hashlib.sha256(str(raw).encode()).hexdigest()
The Starlette middleware on the MCP server recomputes this hash on every incoming request and compares it to the header. If the timestamp window is off by more than one epoch — five seconds — the request is rejected. No database lookup. No token storage. No rotation script. The key rotates itself every five seconds and both sides always agree on what it should be.
This is not production-grade for internet-facing services (TOTP with a proper shared seed is better for that), but for securing local inter-service communication during development and staging it is clean, auditable, and has zero ops overhead.
**The Dual-Rate Audio Pipeline**
WebRTC gives you audio at 48kHz. Whisper is happiest at 16kHz. `webrtcvad` only accepts 8, 16, or 32kHz. Feeding everything through one sample rate loses either fidelity for transcription or compatibility for VAD.
The backend handles both independently in the same 30ms processing loop:
- The full 48kHz PCM buffer accumulates separately for Whisper
- A parallel downsampled 16kHz frame array feeds `webrtcvad` at aggressiveness level 3
- A sliding window tracks the ratio of active to silent frames
- When fewer than 1 in 10 frames in the last 2.0 seconds are active — that's the boundary
python
SILENCE_RATIO_THRESHOLD = 0.1
SILENCE_DURATION_SECONDS = 2.0
active_frames = sum(vad_window)
total_frames = len(vad_window)
if active_frames / total_frames < SILENCE_RATIO_THRESHOLD:
trigger_pipeline()
Splitting the buffers means you get high-quality STT input and accurate VAD detection without either compromising the other.
Service Singletons and the Cold Start Problem
Whisper is not fast to load. If you initialize the model on the first request, your first transcription takes 3–6 seconds depending on hardware. Every user who speaks first gets a broken experience.
The fix is a LoadModelService singleton that runs at server startup:
class LoadModelService:
_model = None
@classmethod
def get_model(cls):
if cls._model is None:
cls._model = whisper.load_model("small")
return cls._model
This gets called inside the FastMCP lifespan hook, so by the time the first WebSocket connection arrives the model is already in memory. Every subsequent transcription call hits a warm model.
The same pattern applies to the mail and calendar services — singletons initialized once, reused across tool calls, with a token-bucket rate limiter (0.5 req/s for Gmail) sitting in front of anything that touches an external API.
**The Pytest Suite**
You can't calibrate a VAD pipeline without tests. The suite covers:
- Frame decimation accuracy at different sample rates
- Speech onset boundary detection under various silence patterns
- SMTP integration with mock SMTP server
- Calendar tool with automatic `.ics` fallback when no calendar service is configured
[ RUN ] test_frame_decimation_48k_to_16k
[ OK ] test_frame_decimation_48k_to_16k
[ RUN ] test_vad_silence_boundary_2s
[ OK ] test_vad_silence_boundary_2s
[ RUN ] test_smtp_send_integration
[ OK ] test_smtp_send_integration
Running `pytest tests/ -v` from the `mcp/` directory gives you live output with real pass/fail visibility — not just a summary at the end.
**What's Next**
The LLM orchestration and conversation routing layer is actively in development. Once that's in, the full loop closes: speech → STT → LLM agent → tool use → response.
The entire codebase is open source and structured as an educational reference for WebRTC, MCP, and secure microservices. If you're building anything in this space — voice agents, real-time audio pipelines, MCP tool servers — I'd love contributions, issues, or just a look.
GitHub: https://github.com/zkzkGamal/AI-RTC-Agent

Top comments (0)