
ANOTHER GIT TUTORIAL? WHY? WHY GOD, WHY?
Well for sure there is plenty of git guides etc out there, but from my own experience, I know that most of them are really, really basic and limit themselves to sort of copy/paste documentation and make it shorter. I really think that understanding how git works and what options it gives you requires more attention. Lots of people will throw git commands at you and say what those commands do when you use them, without explaining what really happens in the files while invoking the command. I will strive to provide a thorough understanding of the basic phrases, commands, and concepts that you’ll use frequently in your work with git (and that you are probably using already). It might prove to be a long read split into several articles and if you manage to go through all of them I will be really grateful for reading what I had to say.
I won’t lie that every concept and a word I will talk about in those guides came straight out of my head, I try to learn git more and more every day so I will often double check something I talk about and see what other people had to say about a given subject. I will provide links to all my sources that I use as a knowledge base and to all articles and posts that gave me a better understanding of concepts I talk about.
And finally, if I get something wrong - please be sure to comment on that. As I mentioned I strive to learn more and more and the process of learning is always ongoing while working on this series I hope to learn a lot myself, and if I manage to learn something from my readers then my life would be complete and I can end it all.
FOR THE ROAD
As much as I will try to explain everything along the way, if git is still something somewhat new to you, please make sure you have some reference to not get lost, like an official glossary https://git-scm.com/docs/gitglossary or even complete documentation https://git-scm.com/docs. I know that sending you straight to documentation might sound a bit like missing the point of a tutorial-like article, but if I make a mistake of not explaining something that I talk about, you can at least have an easy to-go reference to catch up on the given subject.
WHERE’S GIT?
A lot of text editors will by default, hide git files, and files ignored from git from you in their tree view. In general, it’s a good thing, but for educational purposes, I will use atom git tree to showcase some of git files structure.

GIT OBJECTS
Let’s get right into it and see what those files look like.
We should maybe start by checking the refs folder. Also, let’s compare it to our current CLI output and git position.


I’ve customized my CLI prompt to always showcase what git branch I am currently at and I suggest you do the same, it’s rather convenient. Anyway, we can see that we are currently in a branch called feature/branch_with_a_lot_of_stuff_to_do. In the file structure, we see a folder called feature and a file name branch_with_a_lot_of_stuff_to_do. Using “/” as a way to structure branches into features, hotfixes and releases is a popular way of naming and organizing branches, and git recognizes it nicely and creates adequate folders for it. What interests us the most right now though is the branch file itself. Let's open the file in a text editor since it’s just a text file.

And now run git log in the terminal.

The only content of the file is actually a checksum, that correlates with our current branch checksum. Still, it is a little bit disappointing that that's all there is, right? Where is the actual content, not just the pointers?
Let’s find out more about our commit, where did it come from, are where can it lead us.

cat-file commit might be a new command, but it can prove useful it provides us with more detailed info about git commit object. There are some other objects we need to learn about.

Here’s the view of object folder for where we will be looking for some objects.
Okay, so we have 3 git objects to discuss, blobs, trees, and commits. Once we get through that, we'll know the basics of git inner workings. We should start from the top, and at the top we have commit.
Commit as we saw thanks to cat-file commit contains mostly pointers and some message that we put in it. Pointers are once again cheksums, and the one that is the most interesting one for us right now is the tree pointer. So let’s go to our objects folder and look for the pointed tree. To find it we need to take the first two signs of the tree checksum (ca) and look for the folder called the same way. Check out the screenshot with folders from above, and you will be able to see it. Inside it, we have another text file, with the rest of the checksum (it’s only missing the first two letters that are in the name of the folder).


Here we investigate our tree with git ls-tree. The result shows us the list of our changed files, directories, and points us to their blobs. It also points us to other trees if the changes are nested, while blobs indicate a file has been changed in the current tree directory. This structure is often compared to branches on a tree, and I find it very fitting. Each branch (tree object) has something on it (blobs) but can also lead us further to another branch (tree object) which will have its own blobs and tree pointers. I hope this is clear enough.
Finally, we get to see our blobs which contain the actual changes to the files. I’ll just pick one of the blobs listed in the picture above.

Here’s an attempt of visualizing the structure that leads from commit, through the tree, all the way down to changes made in a file.
Let's backtrack a bit and understand the parent pointer that we saw in the commit. What does that mean? If we would want to change one of the blobs that our tree showed us (like the README file) git would create another blob (without overwriting or deleting the old one) and another tree and that tree would have a pointer to the new blob and all the other pointers our first tree has (assuming only one file changed). Then, at last, this tree would need a reference in a commit. This new commit would have a parent commit, which would be our older commit.
And in overall that’s how objects look like, work and correlate with each other in git! If you want more details about those aspects of git, check out the video I link at the end by Scott Chacon co-founder of GitHub.
GIT INDEX, AREAS
The next thing I want to talk about in the first part of those blog posts is “states” or “places” or “areas” in git (I will be using the last description, simply cause I like it the most). This will let us see how commits, blobs, and trees are used and created. Keep in mind though that even we might call them like some dedicated memory assets with directories and files, git doesn't actually have a directory called staging, no working directory (even though we will be using those names and they are accurate to what happens in them). The repository is, on the other hand, our place for the actual code.
The way all of this happens is through a file called index (hence the current header). This file tracks changes made to your files, through all three areas mentioned above. Adding changes to staging area updates the index with changes implemented, creates new blob and puts them in /objects along with other blobs for adequate commit.
Let's go through all of those three areas
Working directory area - this is where you start when you add new lines of code, new files, etc. They remain in this area until you add. Then they got transferred to…
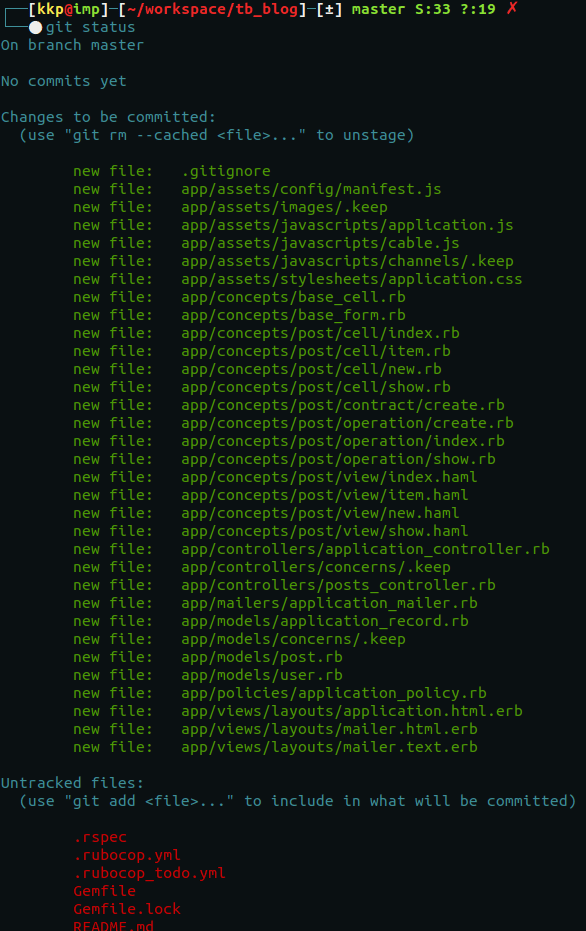
Staging area - On the picture above we see green stuff and red stuff. As you can see above all green files listed we have a prompt saying “Changes to be committed”. That is precisely what the staging area is. It’s all the changes that are gonna be inside your next commit. Red files will be omitted. If you want to learn more about manipulating the data you stage, you can try reading my other blog post about git add --patch.
Committing stage area changes created new files in /objects and we get our commits, blobs, trees. Remember though, that until they are committed, no actual real area is created in git and we are still using the index to store changes and understanding index in detail will be the last thing we do in this blog post but first...
Repository area - directory that holds all our code, that git keeps track of and updates its index based upon changes made to files in this area. In ./git the folders /objects is the place that contains all the pointers to the actual code (in the form of objects we talked about).
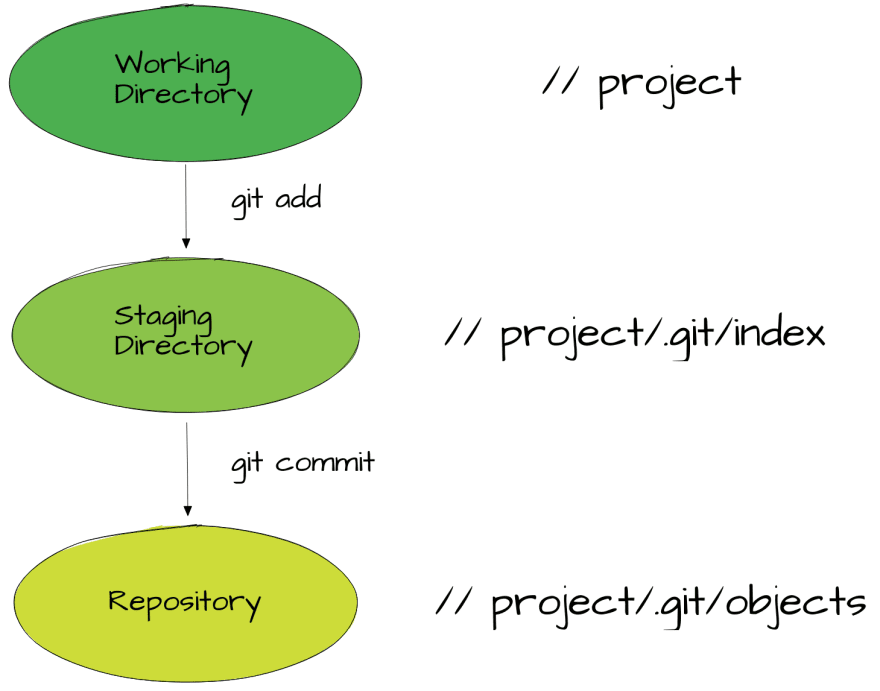
So let's talk about how index holds all the information needed.

This is a small part of binary dump for my index file for a small project. This output takes a lot of space and it might be a bit hard to read. Let's try a hex dump version.
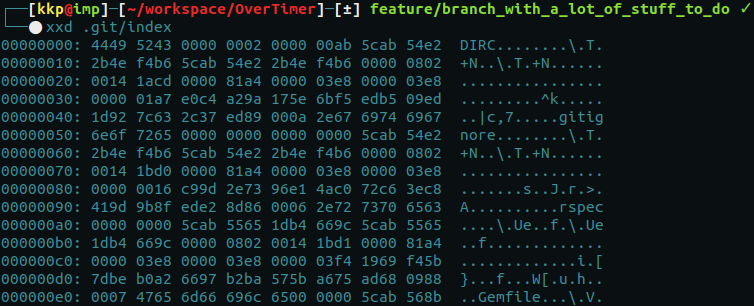
Slightly better, right? Hexes are a bit faster to read (imho).
What we see here is a 12-byte header consisting of a 4-byte signature “DIRC” which stands for DirCache.
There’s also a 4-byte version number “2” (0x00000002), which is the current version of my git index format.
The rest is a number of index entries, the checksums we talked about during objects section.
So basically the index contains every bit of information needed to create a tree object. Not only that it can be used to compare the working tree with the currently used tree, which is a very important part of git itself (being able to see your changes, this is where it originates to). It also represents merge conflicts and helps with resolving three-way merge (a merge, where the final version is somewhere in between of two versions you had).
In final notes, I would like to recommend putting git ls-files --stage in your console and figuring out what the output tells you.
Next up I will explain in more detail what happens in git when you use some of the more popular git commands.
So what really happens when I…
1. Use git add
2. Use git commit
3. Use git branch
4. Use git checkout
5. Use git merge
6. Use git push
7. And more…

SOURCES
https://www.youtube.com/watch?v=ZDR433b0HJY
https://mincong-h.github.io/2018/04/28/git-index/
https://stackoverflow.com/questions/21309490/how-do-contents-of-git-index-evolve-during-a-merge-and-whats-in-the-index-afte
https://shafiul.github.io//gitbook/7_the_git_index.html

Top comments (0)