In the previous post, we discussed how the perceptrons connect to form a layer of a neural network and how these layers connect to form what is called a deep neural network. In this post, we will start with an example and learn how a neural network is trained. Further, we will discuss, how the network computes loss.
Example
Let us consider an example problem where we want to predict whether a student will pass or fail a class given the number of lectures attended(x1) and the number of hours spent(x2) on the final project by the student.
We can represent this problem with the following model:

To make a prediction, we need to initialize the weights(W). We can start by initializing weights randomly. Now let us say, for a student who attended 4 lectures and spent 5 hours on the final project, the model predicted output of 0.1 or 10%. But in reality, the student passed the class. We need a way to tell our model that the predicted output was wrong so that the model can adjust its weights to predict an output closer to the actual value. This can be done by defining a loss function:
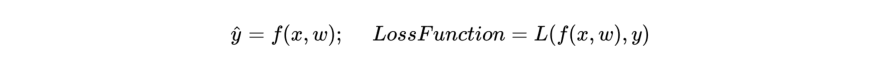
We can average up the loss for each training set sample to calculate the final average loss. This is also called the cost function or empirical loss.

Loss
We can use different loss functions for different models depending on the output produced by the model. Some of the common functions include mean squared error loss & binary cross-entropy loss
Mean Squared Error Loss can be used with models that produce continuous numbers as output. An example of this would be predicting the score of a student or the price of a house.

Binary Cross-Entropy Loss can be used with models that produce a probability between 0 & 1. An example of this would be predicting whether a student will pass or fail.

The final piece left in training the model is to optimize the loss. By optimizing we mean that we want to minimize the loss of the model over all the inputs in the training data. This can be achieved by using an optimization algorithm called Gradient Descent.
Conclusion
In this post, we learned how loss is calculated for a neural network. In the next post and final post, we will learn about the Gradient Descent Algorithm and how it can be used to minimize the loss so that our model can predict outputs with better accuracy.
I would love to hear your views and feedback. Feel free to hit me up on Twitter.

Top comments (0)