This is the second post on scraping audible I’ve written. The first was pretty okay but I really like the strategy I have in this one even better. And…that is why I’m here, writing this post today.
I probably have a unique scenario that I’m using that won’t apply to most people. My family shares audible libraries. You can argue about the ethics of this all you want. We kind of treat it as if we’re loaning books to each other. Because we share libraries, we try not to overlap our purchases. When I go to make a purchase, I like to look at my siblings’ libraries to ensure they don’t have the book already.
So my goal? Get one place that has the combined list of audio books from three different libraries.
And so while the above scenario probably doesn’t apply to most people, the technique I used here I think is pretty cool and applies to a lot of different areas. While I do web scraping in this post, it’s mostly web automation. Getting access to my own data and compiling into one spot.
Authentication

The key to this comes down to authentication. In the previous post I did on Audible scraping, I would just save the username and password in a config/.env file and then use that when logging in. This worked great from my siblings’ account but not for mine, which has two factor authentication.
In order for it to work properly for me, I would need to actually be present when it was scraping. Which is okay but not great. It’s something that I would probably forget or not stick with doing on a regular basis. I wanted a solution where I could set up a cronjob and then forget it.
I know in order to this I would have to look to the cookie.
Look to the cookie!

I started off with an incognito browser and signed in and authenticated with my one time password (OTP). Then..I just went to the cookies and started deleting and refreshing. If I refreshed and I was still on audible’s home page, I knew that wasn’t the cookie I wanted.

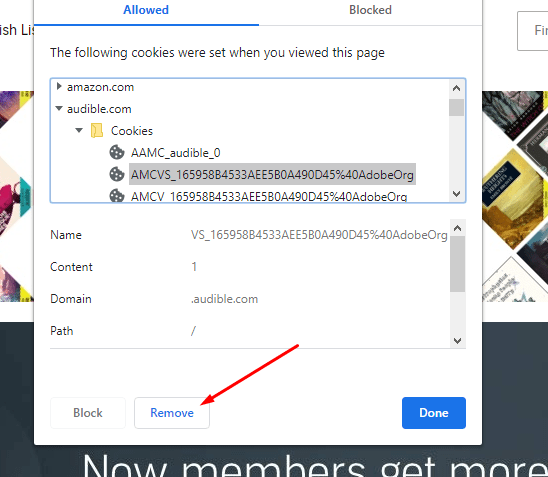
I have built a few authentication processes but I’m still not an expert in it. Audible uses sign in with Amazon so I wasn’t exactly sure if the authentication cookie I was looking for would be under the amazon.com domain or the audible.com domain. I figured it had to be associated with the current domain, so I decided to start there.
The notable ones that I thought would be responsible (session-id, sess-at-main, session-id-time weren’t ultimately responsible. I did get some false positives. It’s almost like there is a soft cookie and then a more strict cookie.
Soft cookie vs hard cookie

What I found was that there was a cookie that would keep me signed in. It’d allow me access to my name in the header, my credits available, and possibly other things (though I didn’t check too deep).
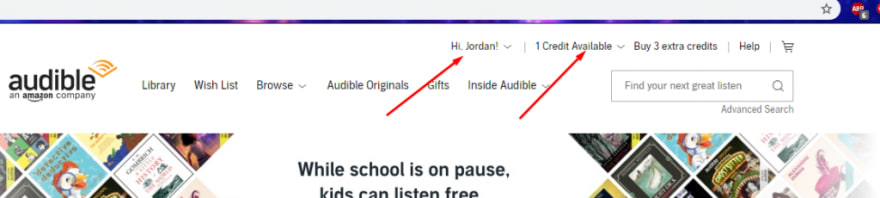
If I tried to navigate to my library or purchase history or something more sensitive, it would redirect me to a sign in. I have seen something like this before never really paid attention to it. The goal is probably to lower customer pain by trying to reduce how often they need to sign while still keeping the more sensitive stuff behind a stiffer cookie.
It’s pretty interesting stuff. I would think that would mean that the stiffer cookie would expire sooner and eventually I did find the one I was looking for, which was x-main.
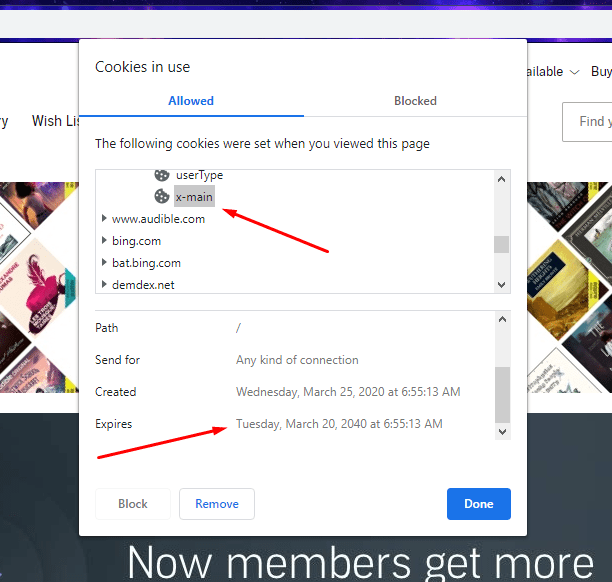
The official expiration on there is the same as all of the other cookies I looked at, 20 years from now. I’m pretty sure it will expire before then but I’m about two weeks in and still using the same x-main cookie successfully.
One thing that really threw me for a loop is that it didn’t always let me in. If I copied this cookie to my browser and then tried to navigate directly to my library, https://audible.com/library/titles, sometimes it would work great and sometimes it would prompt me to sign in. Like…what? As I said above, I’m not an expert in authentication matters but if a cookie is good shouldn’t a cookie be good?
¯_(ツ)_/¯
The code

Puppeteer makes this really simple. I just do the following:
async function auth(context: BrowserContext, cookie: string) {
const page = await context.newPage();
const cookies: puppeteer.Cookie[] = [
{
name: "x-main",
value: cookie,
domain: ".audible.com",
path: '/'
} as puppeteer.Cookie
];
await page.goto('https://audible.com');
// Set cookie and then go to library
await page.setCookie(...cookies);
const libraryUrl = 'https://audible.com/library/titles';
await page.goto(libraryUrl);
try {
await page.$eval('.adbl-library-content-row', element => element.textContent);
}
catch (e) {
throw e;
}
return page;
}
My try/catch is to see if we actually hit a valid page. If not, I catch the throw in the calling function and then try it again. This is probably a bit dangerous for when it’s fully automated because if the cookie dies, it could continue forever. I’d probably put a check to have it try ~10 times.
Once we’re in, I just do some normal Puppeteer scraping magic.
async function getBooks(page: Page, existingBooks: any[]) {
const bookData: any[] = [];
try {
let notTheEnd = true;
let pageNumber = 1;
const libraryUrl = 'https://audible.com/library/titles';
while (notTheEnd) {
let owner = await page.$eval('.bc-text.navigation-do-underline-on-hover.ui-it-barker-text', element => element.textContent);
// This breaks if nothing is left after the split
owner = owner.split(',')[1].replace('!', '').trim();
const booksHandle = await page.$$('.adbl-library-content-row');
for (let bookHandle of booksHandle) {
const title = await bookHandle.$eval('.bc-text.bc-size-headline3', element => element.textContent);
const author = await bookHandle.$eval('.bc-text.bc-size-callout', element => element.textContent);
const image = await bookHandle.$eval('img', element => element.getAttribute('src'));
let url: string;
try {
url = await bookHandle.$eval('.bc-list-item:nth-of-type(1) .bc-link.bc-color-base', element => element.getAttribute('href'));
}
catch (e) {
console.log('Cannot find url. Probably a journal. I do not want it.');
}
// Only add if it does not find
if (!existingBooks.find(book => book.title === title) && url) {
bookData.push({
title: title.trim(),
author: author.trim(),
image: image,
url: url,
owner: owner
});
}
}
const pagingElementHandles = await page.$$('.pagingElements li');
// Let's check if the last one is disabled
const lastPageElementClasses = await pagingElementHandles[pagingElementHandles.length - 1].$eval('span', element => element.classList);
// If one of the classes on the last one is disabled, we know we're at the end and we should stop
if (Object.values(lastPageElementClasses).includes('bc-button-disabled')) {
notTheEnd = false;
}
else {
pageNumber++;
await page.goto(`${libraryUrl}?page=${pageNumber}`);
}
}
}
catch (e) {
throw e;
}
return bookData;
}
And…that’s the end. Best part about it is the cookie work. It really is pretty cool and makes me want to learn more about cookies and how they work.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Audible Libraries Using Cookies appeared first on JavaScript Web Scraping Guy.

Top comments (0)