Scraping the California Secretary of State has been a goal of mine for a while now. It was something I couldn’t quite figure how to do well, however. Well, I’m pleased to say that I’m very happy with what I found. I feel that this is a better scrape than Oregon was and maybe on par with Idaho.
I was able to get them in a relatively correct date order! This is more than I had for Oregon, where I really am not sure who registered when. Idaho doesn’t really count because it allowed you to search by date range. It felt kind of like cheating.
California, however, is tough. Look at their search form:

Yes, that’s it. There is certainly no date there. Alright, let’s get into the investigation I did to figure out a good way to start. I’ll give you a hint, it has to do with the entity number.
Investigation

First step was that search form. I started with something like I did with Oregon and searched for just “a”. I was hoping that maybe at the least I could get a big list of all businesses that started with “a”. It didn’t turn out to be the case. California caps results at 500 with no option to get the remaining results.

Next I looked at the URL to see if there was anything there that could be useful. I was hoping maybe to find a date range or something. https://businesssearch.sos.ca.gov/CBS/SearchResults?filing=&SearchType=CORP&SearchCriteria=a&SearchSubType=Keyword Nothing helpful there. It was a POST request with just basic information sent.
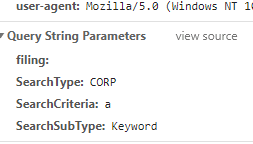
Journey to the details page

Alright, next stop? The details page. Nothing in the URL string so it was a POST. I next went to the network tab, hoping maybe, just maybe, I could find an http request with a bunch of JSON just waiting for me. I didn’t find the JSON waiting for me, but I did find the key for what helped me think of what to do next.
This was another POST with form data about what you would expect.
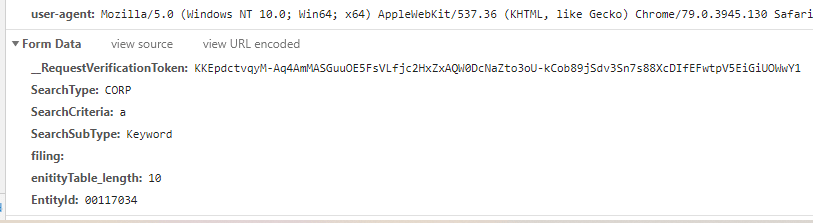
Seeing that EntityId made me wonder if it was random or just something that is incremented. It seems that if it’s a number, it’s incremented. Bigger numbers are more recent. If it’s just a big alphanumberic string like ‘as-3vaew42-adsf’ you probably won’t have such luck.
I started to try and make POST requests. My first attempt with axios looked something like this:
const url = 'https://businesssearch.sos.ca.gov/CBS/Detail';
const body = `__RequestVerificationToken=kvKWWWpQReRQhUaK5gKaj5e39FlOYQRuHoROdgstUQFtZMQdDrKEVVBP8k0Q-ZlGAHy8e7YMh4SXEt9mcvASYgytw-E1&SearchType=CORP&SearchCriteria=a&SearchSubType=Keyword&filing=&enitityTable_length=10&EntityId=04562715`;
const axiosResponse = await axios.post(url, body);
const $ = cheerio.load(axiosResponse.data);
const businessTitle = $('.col-md-12 h2').text();
const pageTitle = $('title').text();
console.log('titles', businessTitle, pageTitle);
Looks pretty okay, right? I just took the body sent in their post request and did the same. Unfortunately, I was not successful. The response was something like this:
I needed to see what the error was so I logged out all the html text with $('html').text();. The response:
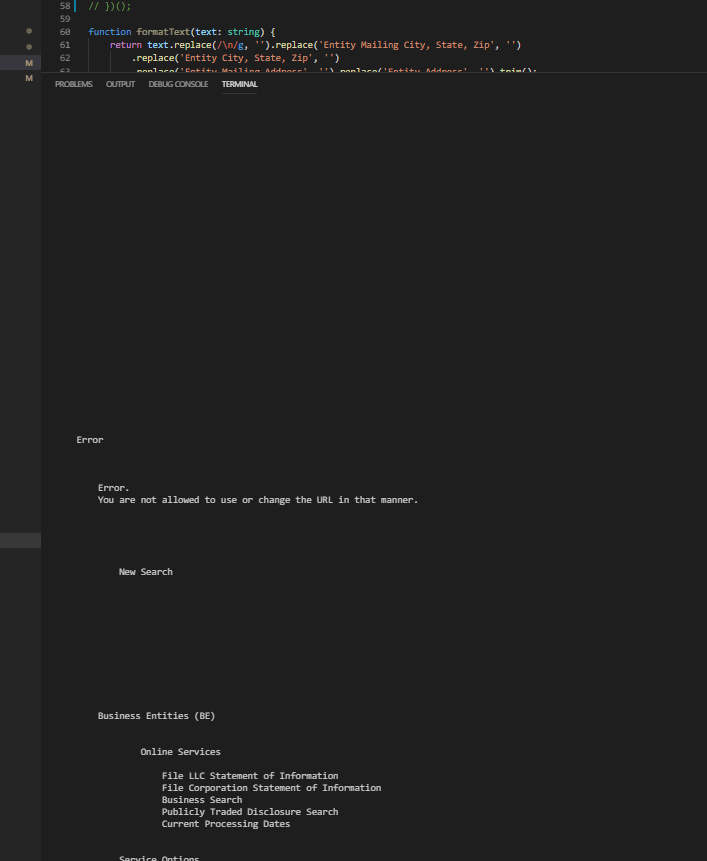
Okay, so it knows I’m not calling directly from their site. I added in a referer and useragent header. Same thing. I had to do a little digging and I just started to add headers and test it out. Eventually I landed on a winner. The cookie. My final axios request code looks like this:
const axiosResponse = await axios.post(url, body, {
headers:
{
'Referer': 'https://businesssearch.sos.ca.gov/CBS/SearchResults?filing=&SearchType=CORP&SearchCriteria=a&SearchSubType=Keyword',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'cookie': 'visid_incap_992756=UYJVNFkLR36DcGXJ3uKeD6tGT14AAAAAQUIPAAAAAAAlSfLf32PEO+bejQTnFqXJ; nlbi_992756=QLAYUB3h33aPqV8coj3WLQAAAAAbdvl6CmxsCba6WUXI+GQ9; incap_ses_724_992756=KGyFVCVZ/Gx4BVZlTysMCqxGT14AAAAAohsd3BEiWgmzW05qx+nIKA==; _ga=GA1.2.1977986284.1582253741; _gid=GA1.2.1859273065.1582253741; visid_incap_1000181=f3uCFO+ZTyq7CmO4aKOGfLFGT14AAAAAQUIPAAAAAAAb8rKfKc5uHMSr7YMK7JvE; ai_user=E1zKI|2020-02-21T02:55:46.915Z; __RequestVerificationToken=sSh_tTeIdfqWrG7ST-BI3f2Pu_WG-tjvA3NAZlVBCOiLN3WvZH6RqYPZ-TzrDNSLriQ0ejGtU9X42j2r6EU3ktMekrA1; nlbi_1000181=kabxFULIpDpvimhSowdtbQAAAABQKcDnnI8dtQEki2DnMyR6; ARRAffinity=aaca3866bf2684de4e3f67aa207c3eb6381f25edaa6d29022160c2d8f573c6fc; incap_ses_226_1000181=P1YxJ0t5TmVmiVh31OkiA3TQT14AAAAADGEynb/O5CknJ7n7KJcFNA==; _gat=1; ai_session=cgmyT|1582289014506.865|1582289014506.865'
}
});
Now, it’s quite likely there is an expiration time on that cookie. At that point, this would just need to be replaced by a new one. If you were doing this on an automated basis, I would build in some kind of thing to just replace this cookie regularly.
Finishing up
Now I had to find if the numbers were truly sequential based on date. This just took a lot of checking the numbers and finding the dead spots. I would increment up by 1,000, see if there were still results, and then continue on until I overshot. Then I would drop down until I hit some again.
Things got a little tricky around 04327745. There’s a huge hole until 4522201 where the numbers seem to just all be empty. These kinds of things really make me wonder what happened. Did someone mess up over there and then they just ended up deleting 200k records to fix it? Maybe they are taken by other entities that wouldn’t fall into the corp category? Who knows.

Finally, I hit pay dirt at 4562714. Beyond this point, there were no further records (that I could tell).

After this, it’s just easy html parsing with cheerio. I also have a friendly 1 second time out between requests, because I’m not a monster. I grabbed that information with just picking the correct divs, mostly using nth-of-type. Example:
const businessListing = {
filingDate: formatText($('#maincontent div:nth-of-type(3) div:nth-of-type(2)').text()),
status: formatText($('#maincontent div:nth-of-type(6) div:nth-of-type(2)').text()),
formedIn: formatText($('#maincontent div:nth-of-type(4) div:nth-of-type(2)').text()),
agent: formatText($('#maincontent div:nth-of-type(7) div:nth-of-type(2)').text()),
physicalAddress: formatText($('#maincontent div:nth-of-type(8) div:nth-of-type(2)').text()),
mailingAddress: formatText($('#maincontent div:nth-of-type(9) div:nth-of-type(2)').text()),
title: businessTitle.replace(`C${startingEntityId + i}`, '').replace(/\n/g, '').trim(),
sosId: startingEntityId + i
};
I formatted the text to get rid of some labels.
function formatText(text: string) {
return text.replace(/\n/g, '').replace('Entity Mailing City, State, Zip', '')
.replace('Entity City, State, Zip', '')
.replace('Entity Mailing Address', '').replace('Entity Address', '').trim();
}
If going to production

There are a few things I would add if I was going to use this on a regular basis. I’d set it up to run every day, starting from the number we ended on. It doesn’t appear that the numbers go exactly in order but if any numbers past 4562714 don’t exist now but then they suddenly exist tomorrow, that means they are new. I would want to be sure as I check, though, that I’m not getting any duplicates.
Once I was happy with the data I was getting on a daily basis, I’d push each lsiting into an array as I looped through. From there, I could save the data off into a CSV or I could save it to a database. The database would make it a bit easier to start from the correct number each day but either would work.
And that’s it. Scraping California’s secretary of state database.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of States: California appeared first on JavaScript Web Scraping Guy.

Oldest comments (0)