Disclosure:I do receive an affiliate commission for everyone who pays for Scraper Api using the link I provide here. Using this promo code also gives a 10% discount – SCRAPE187707
When I first started web scraping I remember expecting there to be a lot of difficulty accessing a lot of the world’s internet. I remember a client asking me to scrape google results and when I saw it was against their terms of service I assumed they would take drastic measures in preventing it. I expected those drastic measures to be things like blocking my IP address completely. I specifically remember thinking how would my Android phone work if my IP was completely blocked from google services.
Then when I got into scraping Amazon I expected something similar. I remember even mentioning in a post talking to my wife, mostly jokingly, about how it would be to be completely banned from Amazon services.
The reality

The reality is, no one wants to block you. You are their customer. It’s messy and bad business to start blocking their customers. They employ a lot of other techniques first, like recaptchas and timing out requests.
Sometimes those things can stop you from attaining the data you want. Google is pretty diligent about doing these things and so I went and intentionally triggered their rate limiting. See below.
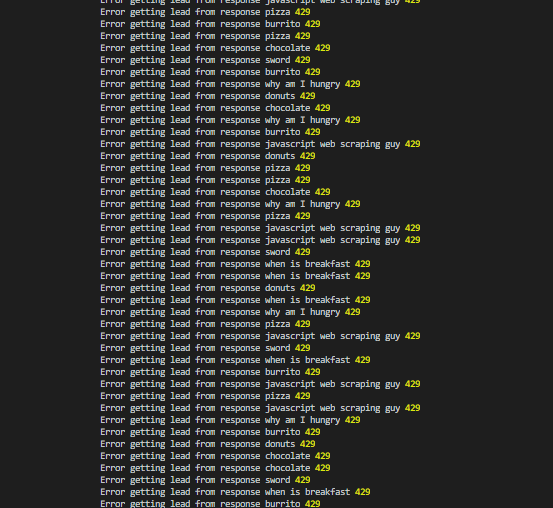
Scraper Api
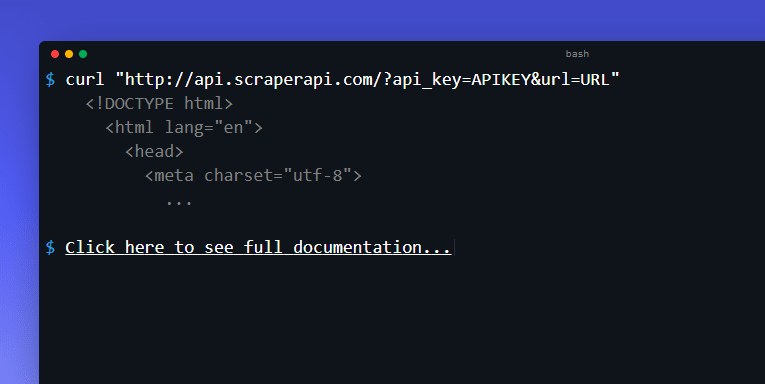
Here is where Scraper Api comes in to play. Scraper Api is a really, really neat tool that handles all the proxying and even CAPTCHAs for you. It’s incredibly easy to use. All you do is use the api key and url they provide and pass it the url you want to visit. Then it does the rest. I used the below requests right after the above ones where I was getting 429s. You can see that almost all of the responses were 200s after the fact.
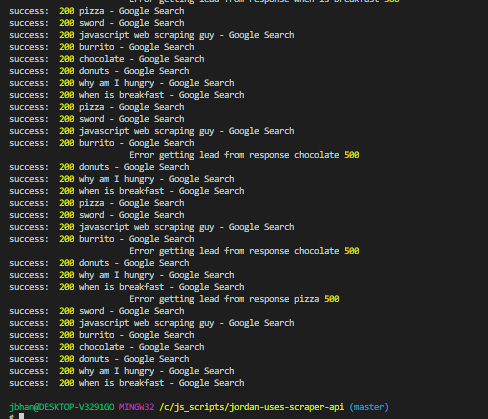
Speed test

Any time you are working with proxies you are going to have a speed hit and working with Scraper Api was no exception. Here are some of the results with and without Scraper Api:
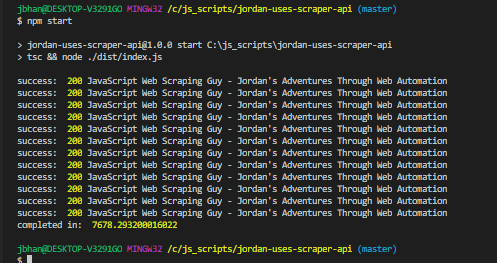
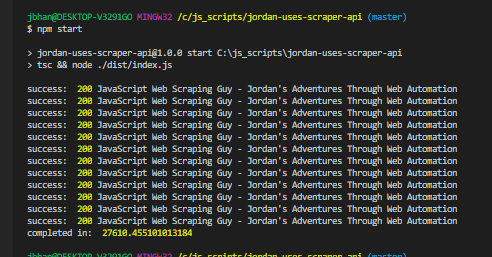
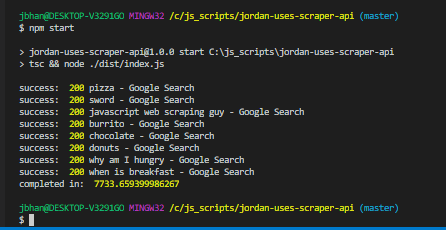
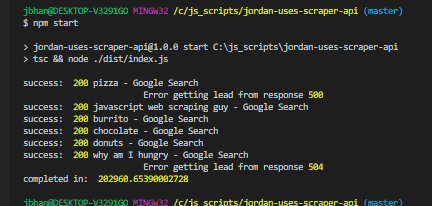
As you can see, when hitting this website it about four times longer than normal with Scraper Api. Google was a lot worse. I think that’s mostly because Scraper Api rotates proxies for about 60 seconds. So if it gets a problem at all, it’ll start rotating proxies until successful. That means that for those errors it took a full 60 seconds. Ouch. The good news is, Scraper Api doesn’t bill for any failed attempt.
Using Scraper Api in Practice

Because of the significant speed hit, I have to recommend using Scraper Api second, after the conventional methods. Here’s an example of how I think good code could work with Scraper Api:
const terms = [
'pizza',
'sword',
'javascript web scraping guy',
'burrito',
'chocolate',
'donuts',
'why am I hungry',
'when is breakfast'
];
// Scraper Api limits how many concurrent requests we have at once
const agent = new Agent({
maxSockets: 25
});
scrape('pizza', agent);
function scrape(term: string, agent: Agent) {
const url = `https://google.com/search?q=${term}`;
const scraperApiUrl = `http://api.scraperapi.com?api_key=${process.env.apiKey}&url=`
axios.get(url).then((response) => {
const html = response.data.content ? response.data.content : response.data;
const $ = cheerio.load(html);
const title = $('title').text();
console.log('Success: ', response ? response.status : 'no status', title);
}, (error) => {
if (error.response) {
console.log(' Error getting response', term, error.response ? error.response.status : 'no response');
if (error.response && error.response.status === 404) {
return `404 for ${url}`;
}
}
else if (error.request) {
console.log(' Error getting request', term, error.request.message);
}
else {
console.log(' Some other error', error.message);
}
// Use Scraper Api with maxSockets
axios({
url: scraperApiUrl + url,
method: 'GET',
httpAgent: agent,
httpsAgent: agent
}).then((response) => {
const html = response.data.content ? response.data.content : response.data;
const $ = cheerio.load(html);
const title = $('title').text();
console.log('Success: ', response ? response.status : 'no status', title);
}, (error) => {
console.log(`Failed getting ${url} with Scraper Api`, error);
});
});
}
The main takeaways here are there if an error happens, we check to see if it’s a 404. A 404 is more of an intentional error and means the page actually doesn’t exist. We don’t need Scraper Api for that.
If it’s not a 404, we then proceed to try the request again with Scraper Api. Scraper Api does limit how many concurrent requests you are allowed to have going at once. This is where the agent comes in. At the top you can see that I create a new Agent with a limited number of maxSockets. The Node.js documentation states that this “Determines how many concurrent sockets the agent can have open per origin.” So you can manage your concurrent requests here and prevent any problems from Scraper Api with the concurrent requests.
The end
So, there you have it. Scraper Api is a powerful, extremely easy to use tool in your scraping tool box. Use this promo code for a 10% discount –
SCRAPE187707. They also have a 1000 free api calls!
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!

Top comments (0)