Introduction.
This is the second episode in the series about how to build your own data platform. You can find the whole list of articles in the following link https://medium.com/@gu.martinm/list/how-to-build-your-own-data-platform-9e6f85e4ce39
Remember, a data platform will be used by many teams and users. Also the data to be stored could be coming from many and different sources. Data owners will want to set permissions and boundaries about who can access the data that they are storing in the data platform.
In this episode I will explain how you can add these capabilities to your data platform. Also I will introduce the concept of data mesh, and how you can use the authorization layer for implementing the workflow between data consumers and data owners that you will need for creating a successful data mesh.
Authorization layer.

Our authorization layer will be on the top of the storage one. In this way, users and applications willing to use the stored data will need to do it through this layer in a safe way. No data will escape from the storage layer without authorization.
For implementing this layer you can use different solutions like Unity Catalog from Databricks, Lake Formation from AWS, plain IAM roles also from AWS, Apache Ranger, Privacera and many others.
For this article, and because we are working with Amazon Web Services, we will be implementing this layer using IAM roles and Lake Formation.
Processing layer.

Human users and processes will be the ones accessing the stored data through the authorization layer. Machines and processes like Zeppelin notebooks, AWS Athena for SQL, clusters of AWS EMR, Databricks, etc, etc.
The problem with the authorization.
Data engineers, data analysts and data scientists work in different and sometimes isolated teams. They do not want their data to be deleted or changed by tools or people outside their teams.
Also, for being GDPR compliant, to access PII data, big restrictions will be required even at column or row level.
Every stored data needs to have an owner, and in Data Mesh, data owners are typically in charge of granting access to their data.
What is a Data mesh?
Taken from https://www.datamesh-architecture.com/#what-is-data-mesh

The term data mesh, coined in 2019 by Zhamak Dehghani, is based on four key principles:
Domain ownership: Domain teams are responsible for their data, aligning with the boundaries of their team's domain. An authorization layer will be required for implementing those boundaries for some team.
Data as a product: Analytical data should be treated as a product, with consumers beyond the domain. An owner-consumer relationship will exist, where consumers require access to products owned by a different team.
Self-serve data infrastructure platform: A data platform team provides domain-agnostic tools and systems to build, execute, and maintain data products.
Federated governance: Interoperability of data products is achieved through standardization promoted by the governance group.
Owner - consumer, relationship.

- A data consumer requests access to some data owned by a different team in a different domain. For example, a table in a database.
- The data owner grants access by approving the access request.
- Upon the approval of an access request, a new permission is added to the specific table.
Our authorization layer must be able to provide the above capability if we want to implement a data mesh with success.
Data Lake.
In this section we will write a brief recap about what we explained in previous article: https://medium.com/@gu.martinm/how-to-build-your-own-data-platform-f273014701ff
AWS S3.

Notebooks, Spark jobs, clusters, etc, etc, run in Amazon virtual servers called EC2.
These virtual servers require permissions for accessing AWS S3. These permissions are given by IAM Roles.We will be working with Amazon Web Services. As we said before, because the amount of data to be stored is huge, we can not use HDD or SSD data storages, we need something cheaper. In this case we will be talking about AWS S3.
Also, in order to ease the use of the Data Lake, we can implement metastores on the top of it. For example, Hive Metastore or Glue Catalog. We are not going to explain deeply how a metastore works, that will be left for another future article.
When using a notebook (for example a Databricks notebook) and having a metastore, the first thing that the notebook will do is to ask the metastore where the data is physically located. Once the metastore responds, the notebook will go to the path in AWS S3 where the data is stored using the permissions given by the IAM Role.
Direct access or with a metastore.
We have two options for working with the data. With or without using a metastore.
With the metastore, users can have access to the data in the Data Lake in an easier way because they can use SQL statements as they do in any other databases.

Authorization, direct access.
Consumers run their notebooks or any other applications from their AWS accounts and consume data located in the producer’s account.
These notebooks and applications run in Amazon virtual servers called Amazon EC2 instances, and for accessing the data located in AWS S3 in the producer’s account, they use IAM Roles (the permissions for accessing the data)

S3 bucket policy
For example, for being able to access to the S3 bucket called s3://producer, with the IAM Role with ARN arn:aws:iam::ACCOUNT_CONSUMER:role/IAM_ROLE_CONSUMER, we can use the following AWS S3 bucket policy in the s3://producer bucket:

Direct access
Here, we are showing an example, where from a Databricks notebook using the above IAM Role and running in the consumer account, we are able to access data located in the producer’s account.

Can we do it better?
With Glue Catalog as metastore, data in S3 can be accessed as if it was stored in a table with rows and columns.
If we use tables instead of the direct access, we can grant permissions even at column level.
Lake Formation provides its own permissions model that augments the IAM permissions model. This centrally defined permissions model enables fine-grained access to data stored in data lakes through a simple grant or revoke mechanism, much like a database. Lake Formation permissions are enforced using granular controls at the column, row, and cell-levels.
Authorization, Lake Formation.
For using Lake Formation we will need the following elements:
An application running in some machine in an AWS account. For example, an AWS EC2 instance where a Spark notebook will be executed.
A shared resource between the producer and consumer’s account. In this case we are sharing the S3 bucket called producer.
An IAM Role with permissions for using the producer’s bucket.
Two AWS Glue Catalogues as metastores. The one in the consumer's account will be in charge of forwarding the table resolution to the metastore in the producer’s account. Both metastores are also shared between the two accounts.
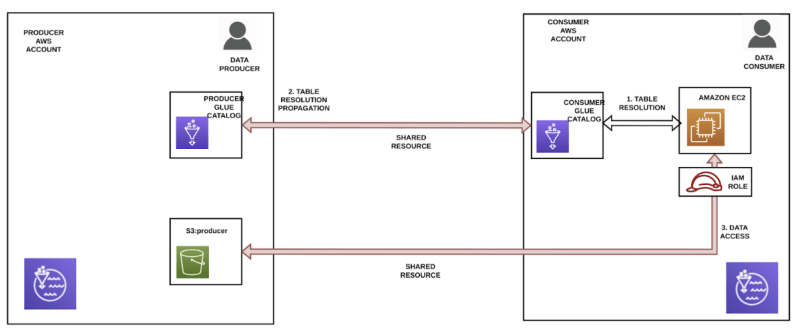
The catalogue in the producer’s account contains all the required information for translating the virtual table to its physical S3 location.
In the below screenshots you can see the Lake Formation configuration for the Glue metastore located in the producer’s account.
First you can see the table and database where the producer’s table is located. You can also see that we are sharing the specific table with the consumer’s account.
Database: schema
Table: producer

In the above table we can configure access permissions. For example, we can decide that we will be allowing only the use of SELECT statements from the consumer’s account and also the only column that will be shown is the one called brand_id.

Now, from the Spark notebook running in the consumer’s account we can run SQL statements against the table located in the producer’s account.
Because we only allowed access to the column called brand_id, the consumer will only see values for that column. Any other column will be hidden.

Conclusion.
In this article we have explained how you can implement an authorization layer using AWS IAM Roles and AWS Lake Formation.
With this authorization layer we will be able to resolve the following problems:
Producers and consumers from different domains must have the capability of working in an isolated way (if they wish so) if we want to implement a data mesh with success.
Producers must be able to decide how consumers can access their data. They are the data owners, and they decide how others use their data.
Fine grained permissions can be established. At column and even if we want, at row level. This will be of great interest if we want to be GDPR compliant. More information about how to implement the GDPR in your own data platform will be explained in future articles.
Stay tuned for the next article about how to implement your own Data Platform with success.
I hope this article was useful. If you enjoy messing around with Big Data, Microservices, reverse engineering or any other computer stuff and want to share your experiences with me, just follow me.

Top comments (0)