
In our previous blog posts (1, 2), we explored how query optimizers may consider different equivalent plans to find the best execution path. But what does it mean for the plan to be the "best" in the first place? In this blog post, we will discuss what a plan cost is and how it can be used to drive optimizer decisions.
Example
Consider the following query:
SELECT * FROM fact
WHERE event_date BETWEEN ? AND ?
We may do the full table scan and then apply the filter. Alternatively, we may utilize a secondary index on the attribute event_date, merging the scan and the filter into a single index lookup. This sounds like a good idea because we reduce the amount of data that needs to be processed.
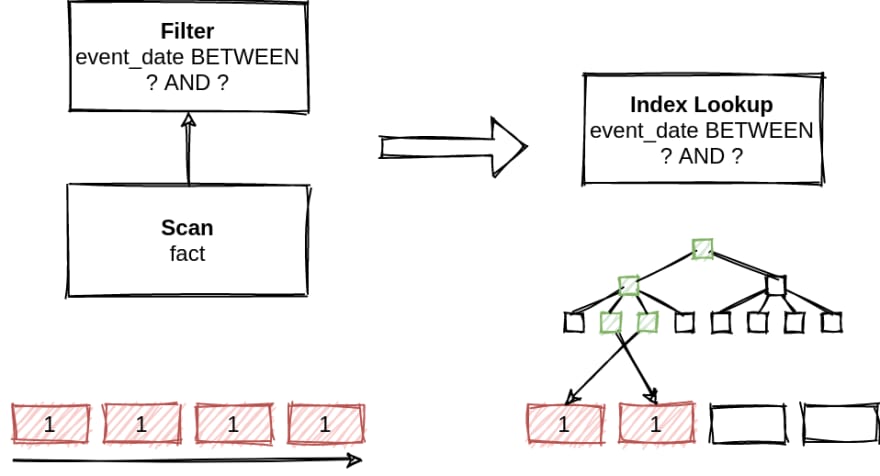
We may instruct the optimizer to apply such transformations unconditionally, based on the observation that the index lookup is likely to improve the plan's quality. This is an example of heuristic optimization.
Now consider that our filter has low selectivity. In this case, we may scan the same blocks of data several times, thus increasing the execution time.
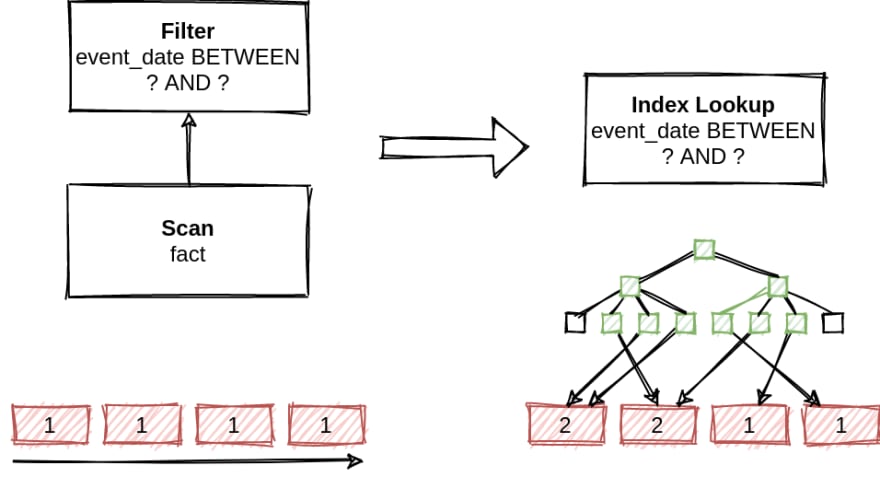
In practice, rules that unanimously produce better plans are rare. A transformation may be useful in one set of circumstances and lead to a worse plan in another. For this reason, heuristic planning cannot guarantee optimality and may produce arbitrarily bad plans.
Cost
In the previous example, we have two alternative plans, each suitable for a particular setting. Additionally, in some scenarios, the optimization target may change. For example, a plan that gives the smallest latency might not be the best if our goal is to minimize the hardware usage costs in the cloud. So how do we decide which plan is better?
First of all, we should define the optimization goal, which could be minimal latency, maximal throughput, etc. Then we may associate every plan with a value that describes how "far" the plan is from the ideal target. For example, if the optimization goal is latency, we may assign every plan with an estimated execution time. The closer the plan's cost to zero, the better.

The underlying hardware and software are often complicated, so we rarely can estimate the optimization target precisely. Instead, we may use a collection of assumptions that approximate the behavior of the actual system. We call it the cost model. The cost model is usually based on parameters of the algorithms used in a plan, such as the estimated amount of consumed CPU and RAM, the amount of network and disk I/O, etc. We also need data statistics: operator cardinalities, filter selectivities, etc. The goal of the model is to consider these characteristics to produce a cost of the plan. For example, we may use coefficients to combine the parameters in different ways depending on the optimization goal.
The cost of the Filter might be a function of the input cardinality and predicate complexity. The cost of the NestedLoopJoin might be proportional to the estimated number of restarts of the inner input. The HashJoin cost might have a linear dependency on the inputs cardinalities and also model spilling to disk with some pessimistic coefficients if the size of the hash table becomes too large to fit into RAM.
In practical systems, the cost is usually implemented as a scalar value:
- In Apache Calcite, the cost is modeled as a scalar representing the number of rows being processed.
- In Catalyst, the Apache Spark optimizer, the cost is a vector of the number of rows and the number of bytes being processed. The vector is converted into a scalar value during comparison.
- In Presto/Trino, the cost is a vector of estimated CPU, memory, and network usage. The vector is also converted into a scalar value during comparison.
- In CockroachDB, the cost is an abstract 64-bit floating-point scalar value.
The scalar is a common choice for practical systems, but this is not a strict requirement. Any representation could be used, as long as it satisfies the requirements of your system and allows you to decide which plan is better. In multi-objective optimization, costs are often represented as vectors that do not have a strict order in the general case. In parallel query planning, a parallel plan requiring a larger amount of work can provide better latency than a sequential plan that does less work.
Cost-based Optimization
Once we know how to compare the plans, different strategies can be used to search for the best one. A common approach is to enumerate all possible plans for a query and choose a plan with the lowest cost.
Since the number of possible query plans grows exponentially with the query complexity, dynamic programming or memoization could be used to encode alternative plans in a memory-efficient way.
If the search space is still too large, we may prune the search space. In top-down optimizers, we may use the branch-and-bound pruning to discard the alternative sub-plans if their costs are greater than the cost of an already known containing plan.
Heuristic pruning may reduce the search space at the cost of the possibility of missing the optimal plan. Common examples of heuristic pruning are:
- Probabilistic join order enumeration may reduce the number of alternative plans (e.g., genetic algorithms, simulated annealing). Postgres uses the genetic query optimizer.
- The multi-phase optimizers split the whole optimization problem into smaller stages and search for an optimal plan locally within each step. Apache Flink, Presto/Trino, and CockroachDB all use multi-phase greedy optimization.
Summary
The cost-based optimization estimates the quality of the plans concerning the optimization target, allowing an optimizer to choose the best execution plan. The cost model depends heavily on metadata maintained by the database, such as estimated cardinalities and selectivities.
Practical optimizers typically use ordered scalar values as a plan cost. This approach might not be suitable for some complex scenarios, such as the multi-objective query optimization or deciding on the best parallel plan.
Dynamic programming or memoization is often used in cost-based optimization to encode the search space efficiently. If the search space is too large, various pruning techniques could be used, such as branch-and-bound or heuristic pruning.
In future blog posts, we will explore some of these concepts in more detail. Stay tuned!
We are always ready to help you with your query optimizer design. Just let us know.

Top comments (0)