
Original Post: https://aidangee.dev/blog/5-tips-to-help-scale-your-app-scale
Intro
You want your multichannel application to grow and have more users. But as this grows you will need to be able to handle the increased traffic whilst also balancing the cost of infrastructure. If you get that big brand customer you don't want them to take down your service for themselves and other customers! (seen this first hand!)
The quick solution is often to vertically or horizontally scale the compute, but costs can quickly get out of control.
I have worked on both small and extremely high traffic applications and wanted to share some techniques I have seen successfully used.
1. Serverless
Serverless Architecture is ideal for allowing an initially small web application to scale over time. Serverless infrastructure is both auto-scaling and pay per use. So whilst your app is small you will not need to pay for idle compute costs and when the time comes you have the capacity for significant growth in the future.
This fits well with applications that have a 'spikey' traffic pattern. For example ticket sales or product launches, in these use cases the user traffic is generally condensed into a short window of time and serverless compute like lambda or cloud functions allow for the instant scale needed to support this. Whilst keeping costs low.
This doesn't just end with compute, there is a growing number of serverless database solutions as well. DynamoDB, MongoDB, FaunaDB, Aurora these all offer a serverless way to store your data. Meaning there is little to no infrastructure for you to worry about managing across your stack.
Example of a Serverless Application built on top of AWS:

What to check out: Serverless Framework, Lambda, Cloud Functions, Cloud Run, Cloudflare Workers, Netlify
2. Client side rendering / Pre-rendering / Hybrid
Depending on the user experience you need to provide and your SEO requirements, the way you render your UI can make a big difference to how your application scales.
If your application is purely server side rendered, it might be worth asking yourself the question "does it need to be?". Moving some server-side work to the user's browser or pre-rendering it at build time could save on some resources. For example, in the past I have moved an e-commerce website's checkout process to an SPA which cut down the traffic hitting their web servers on average by 30%. This made a big difference to infrastructure costs and scale at high traffic events. With little change to the users experience.
This is a varied subject based on your use case, I have written a whole post on rendering options with JavaScript if you want to learn more.
Theres also a fantastic talk recently from Rich Harris (Svelte Maintainer) on the trade-offs between server rendering and SPA's.
3. Queues & Asynchronous Workers
Queues and background workers can help improve the scalability of your application by offloading slow or intensive tasks. This is commonly by decoupling a user action from some processing that could cause a backlog and effect performance.
Some common examples of this might be uploading an image, generating a report or processing a video. If we take the example of generating a report for a large dataset, this might take a few minutes for a user. You do not want this process using up a large amount of resources and holding open connections on the same infrastructure that is dealing with the requests of your other users. You risk an extra large report or a few reports running simultaneously to start effecting performance or cost.
Shifting this work to the background can allow this to be dealt with predictably. Sending these requests to a queue that can push (or pull) the work to a set of worker processes allows you to control the scaling of infrastructure and not risk the affecting other requests coming in.
What to check out: AWS SQS, Cloud Tasks, render.com background workers, Heroku workers, Go Worker
4. Spot / Preemptible Instances
If you have auto-scaling servers, costs can quickly rack up as you grow. Spot instances (preemptible VMs on GCP) make use of unused compute for upto 90% savings on the usual on-demand price.
Integrating with spot instances has been made much easier the past year or so with integrations with EC2 auto-scaling and Spot fleet. But there can still be some responsibility to handle interruptions and rebalancing if your application is not 'fault-tolerant'. To take away these concerns services like Spot can guarantee a high availability and abstract away some of the complexities.
What to check out: Spot intances, Preemptible VM instances
5. Event Driven Architecture
Applications usually start with monolithic design. A singular running process to do everything from logging & metrics to sending emails. If part of that fails, or you get a long running task, then this could clog up the system.
An event driven approach allows you to decouple these different pieces into seperate services that can scale & fail independently of one another. This system uses events to trigger and communicate between decoupled services.
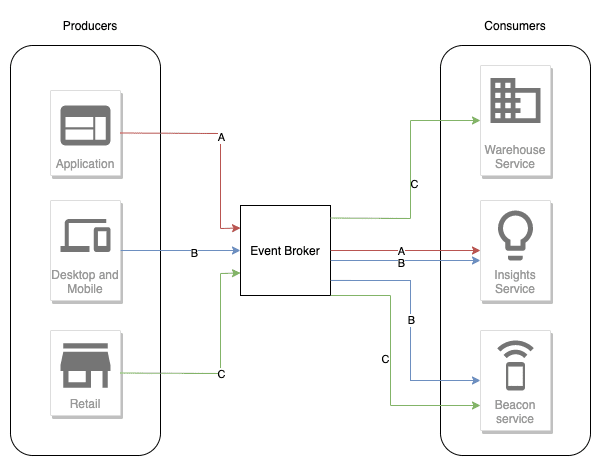
What to check out: AWS video series, Event Bridge, Eventarc
Bonus: Monitoring!
Something that I think is often overlooked is the power of performance monitoring. How do you know if a new release is using significantly more resources, is it from your metrics or when you get the big infrastructure bill at the end of the month?
Theres a ton of Application monitoring solutions out there with integrations for all types of languages. New Relic & DataDog are 2 popular examples. They allow you to get much more fined grained than just CPU, Memory usage & scaling. You can see information such as :
- External API performance
- Code-level visibility e.g. inspecting a particular methods performance
- Traces for slow performing request
And way more !
Performance monitoring can help you stay scalable whilst you continue to make changes.

Top comments (0)