
Visão Computacional é a ciência responsável pela visão de uma máquina, pela forma como um computador enxerga o meio à sua volta. A proposta é imitar a visão humana, para tanto, oferecemos como entrada uma imagem, realizamos um processamento e entregamos como saída uma interpretação da imagem recebida.
Os sistemas de Visão Computacional portanto, tem como missão desenvolver tecnologias que permitam que as máquinas enxerguem e identifiquem os elementos que estão sendo visualizados. Mas como isso funciona na prática?
Ensinar um computador a ver não é uma tarefa trivial. Você até pode colocar uma câmera incrível nele, mas ainda assim, isso não vai resolver o seu problema. Para que uma máquina realmente veja o mundo e identifique pessoas, animais ou objetos, ela depende de técnicas de Visão Computacional associada a técnicas de Machine Learning/Deep Learning.
E afinal de contas, como as máquinas enxergam?
Para entender bem, vamos pensar e observar primeiro, como os humanos enxergam:
- Você visualiza um objeto.
- Processa na sua cabeça e observa se você já viu este objeto antes.
- Se você já viu este objeto, associa o nome que te falaram que ele possui e o reconhece. Se você nunca viu este objeto antes, pergunta para alguém e aprende o nome deste objeto ou pode ignorar e só considerar aquele objeto uma coisa desconhecida.
Ok, para o computador, temos etapas bem parecidas, com algumas técnicas sendo aplicadas em cada uma delas:

- O computador visualiza o objeto, utilizando a câmera como se fossem olhos.
- Realiza alguns pré-processamentos na imagem, que pode ser um corte em torno do objeto de interesse, filtros para facilitar a identificação do objeto.
- Associa o objeto que está sendo visto, há certos padrões de imagens de objetos que já foram mostrados para a máquina.
- Se conhece o objeto, exibe o nome do objeto, se não reconhece indica que o objeto é desconhecido.
Já sabemos que as câmeras são equivalentes aos nossos olhos, mas precisamos saber que elas atuam como sensores. O que significa que elas convertem informações que estão ai no nosso mundo biológico para informações discretizadas, ou seja, as câmeras convertem tudo que pode ser visto, em números para que o computador entenda esta informação.
Você já deve ter chegado bem perto do seu monitor ou da sua televisão, a ponto de ter visto vários quadradinho coloridos, certo? Se não fez ainda, faça isso agora! Cada quadradinho é um pixel, que é a menor unidade da imagem.

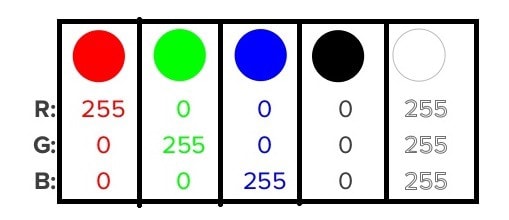
Em cada pequeno espaço deste preenchemos com certa quantidade de três cores: Vermelho, Verde e Azul. E por que utilizamos apenas estas cores? Simplesmente porque após estudos, descobrimos que os nossos olhos possuem receptores sensíveis a estas três cores e a partir da combinação delas, podemos criar todas as outras. Isto é chamado espaço de cores RGB (Red, Green, Blue).
De forma simplificada, atribuímos valores de 0 a 255 para a cada uma das cores. Você pode criar diferentes cores, alterando os níveis RGB, nesta ferramenta: https://color.adobe.com/pt/create
Observe na imagem abaixo, para formar a cor Vermelho, “enchemos” o balde de cor Red com 255 e zeramos todos os outros e assim sucessivamente com a cor Verde, colocamos o valor 255, no segundo item que representa o Green e zeramos todos os outros, na cor Azul, colocar o 255 no terceiro item, que representa o Blue e zeramos os outros.
No caso da cor preta, que é a ausência de todas as cores, colocamos o valor zero em todos os três campos e a cor branca “enchemos” o Red, Green e Blue.
Geralmente, nos sistemas de Visão Computacional, também trabalhamos com as imagens em escala de cinza, pois nela passamos a ter apenas um canal de cor, representando a mesma imagem, com valores entre 0 a 255, em cada pixel. Esta é uma maneira simples de reduzir a quantidade de informação a ser processada e obter melhores taxas de processamento e velocidade na aplicação.
Se temos uma imagem de 100 pixels de largura por 100 pixels de altura, na prática temos uma matriz de 100 linhas e 100 colunas, com informações variando entre 0 a 255, como na imagem abaixo:

Utilizando técnicas de Machine Learning e/ou Deep Learning, os sistemas de Visão Computacional, procuram padrões numéricos para identificar bordas, cores semelhantes e texturas.
Assim, extraindo várias características da imagem, é possível detectar os padrões presentes no perfil de cada objeto a ser identificado.

Onde estamos e para onde vamos?
Neste momento, estamos numa fase bem parecida com os primeiros anos de vida de uma criança. Os sistemas de Visão Computacional já conseguem detectar alguns elementos com facilidade, como rostos e carros.
Para que eles sejam capazes de reconhecer novos objetos, precisamos realizar um treinamento exatamente como fazemos com as crianças humanas. Se você mostrar a ela um objeto e dizer o nome dele algumas vezes, logo a criança aprenderá a reconhecer este objeto.
No 4° episódio da ótima série Silicon Valley, vemos um grupo de amigos que desenvolveu um aplicativo de Visão Computacional, capaz de identificar se qualquer objeto é um cachorro-quente, ou não.
No exemplo do hotdog acima, os desenvolvedores ofereceram várias fotos de cachorros-quentes. E a partir dai a aplicação desenvolve uma ideia geral do que é uma imagem de um cachorro-quente e o que deveria ter nela. Coisas como cores, formatos e extremidades são levadas em consideração.
Quando você oferece uma nova imagem, ela compara cada pixel a ideia geral de cachorro-quente que já foi criada. Se a imagem nova atingir um limite mínimo de pixels semelhantes, declaramos que é um cachorro-quente.

Para fazer o reconhecimento um sistema de visão necessita uma base de conhecimento dos objetos, esta base de conhecimento pode ser implementada diretamente no código, através, por exemplo, de um sistema baseado em regras, ou esta base de conhecimento pode ser aprendida a partir de um conjunto de amostras dos objetos a serem reconhecidos utilizando técnicas de aprendizado de máquina.
O TED abaixo exemplifica bem essa definição, a pesquisadora de Stanford Fei-Fei Li, criou em 2007 o projeto Imagenet, um repositório de imagens para identificação de padrões visuais e explica os principais desafios da área.
Até uma próxima,
AI Girl
Escritora: Suzana Mota
Siga a comunidade nas redes sociais!!

Top comments (0)