
Day two at re:Invent 2017 was incredibly packed, crowded, and exciting. My favorite announcement so far is the new AWS AppSync, as it aligns with one of the most promising (yet somehow controversial) design principles adopted by the serverless community: GraphQL. If you are not familiar with GraphQL, we recently explained how to write GraphQL Apps using AWS Lambda, and hosted a webinar about the Love Story between Serverless and GraphQL. Here’s a quick look at what you need to know about AWS AppSync.
Mobile and Web App Challenges
I attended the first deep dive session on AWS AppSync, which brilliantly summarized the main technical challenges faced by most mobile and web applications:
- Authentication & user management
- Efficient network usage
- Multi-device support
- Data synchronization between devices
- Offline data access
- Real-time data streams
- Cloud data conflict detection & resolution
- Running server-side code (without managing servers)
Each of these challenges could merit its own article, but I am assuming that everyone has experienced a really bad mobile UX, and at least once from the user perspective (any implicit reference to the AWS re:Invent app is clearly unintentional). Moreover, most of these challenges are a direct consequence of how we’ve been designing RESTful interfaces for web and mobile.
If you are a web or mobile developer, GraphQL can help you solve many of these challenges, especially the ones related to network optimization, thanks to dynamic queries, and real-time data streams, thanks to GraphQL subscriptions.
How is GraphQL better than REST?
GraphQL can alleviate the pain caused by many complex problems that are pretty much unsolvable with REST only. This includes API resource relationships , reduced or customized information in API responses , dynamic query support , advanced ordering and paging , push notifications , etc.
GraphQL is basically a query language for APIs , and it makes it very easy to add an abstraction layer on top of already existing data and APIs. Plus, it's strongly typed and can act as a self-documenting contract between client and server.
Again, if you are not familiar with the concept of GraphQL Queries, Mutations, and Subscriptions, have a read here (it gets more technical from now on!).
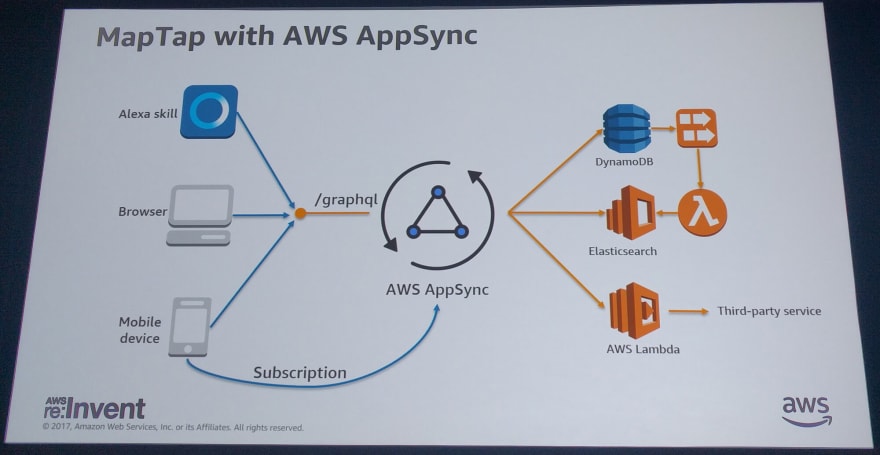
AWS AppSync Features & Gotchas
AWS AppSync allows you to focus on building apps instead of managing all the infrastructure needed to run GraphQL (either with or without servers).
AppSync will connect queries to AWS resources, and it provides built-in offline and real-time stream support via client-side libraries , which also come with different strategies for data conflict resolution (even custom Lambda-based implementations!). The service offers enterprise-level security features such as API keys, IAM, and Cognito User Pools support.
As with any GraphQL application, your development workflow would look like the following:
- Define your schema (queries, mutations, and subscriptions)
- Define resolvers (data sources)
- Use client tooling to fetch data via the GraphQL endpoint
AWS AppSync provides built-in support for three data sources:
- DynamoDB
- ElasticSearch
- Lambda (for custom or generated fields)
The AppSync client library is available both for mobile and web clients (iOS, Android, JavaScript, and React Native). Offline support is pretty straightforward, and the client will automatically sync data when a network is available. Since GraphQL is an open standard , you are not forced to use the AppSync client. In fact, any open-source GraphQL client will work. Of course, AppSync endpoints can be used by servers, too.
Mutation Resolvers can be mapped into data sources via mapping templates (Velocity). As with API Gateway templates, they come with a few utilities such as JSON conversion, unique ID generation, etc., and ready-to-use sample templates. Based on the specific data source, templates will allow for complete customization of the backend query (e.g. DynamoDB PutItem, ElasticSearch geolocation queries, etc.).
Since you’ll spend most of the time working with the Schema Editor, I was quite happy to notice that it is quite user-friendly, and it comes with search and auto-complete capabilities.
AWS AppSync and AWS Lambda
You can use AWS Lambda to compute dynamic fields, eventually in a batch fashion. For example, imagine that your schema defines a “paid” field that needs to be fetched from a third-party payment system for each invoice. You would probably define a ComputePaid Function and a ComputePaidBatch Function.
The batch function will be automatically invoked to process the value of multiple records without incurring the N+1 problem. Of course, you could use the same Lambda Function for individual and batch processing.
AWS AppSync Pricing
AppSync will be charged based on the total number of operations and real-time updates. More detailed, real-time updates are charged based on the number of updates and the minutes of connection.
Here are the numbers:
- $4 per million Query and Data Modification Operations
- $2 per million Real-time Updates
- $0.08 per million minutes of connection to the AWS AppSync service
Please note that data transfer is charged at the EC2 data transfer rate and that real-time updates are priced per 5kb payload of data delivered (prorated). While the service is completely free during the preview phase, it will come with a free tier once it is generally available.
Also note that AppSync has no minimum fees or mandatory service usage , compared to other similar offerings such as Graphcool.
Conclusions
I expect that AWS AppSync will be well received by the serverless community, and it will make GraphQL much easier to adopt for many use cases.
It will be a great option for applications that need to drastically optimize data delivery, or to transparently manage many data sources under the hood. Moreover, it will also allow developers to design self-documenting APIs powered by a strong type system and a powerful set of developer tools that will simplify API evolution.
Keep in mind that AWS AppSync is still in preview, but you can start playing with it by signing up here.
I’m looking forward to playing with it myself next week, and I can’t wait to share my first results with the community. If you already use GraphQL in production, let us know what you think of AWS AppSync in the comments below!

Top comments (0)