AWS CloudTrail service captures actions taken by an IAM user, IAM role, APIs, SDKs and other AWS services. By default, AWS CloudTrail is enabled in your AWS account. You can create "trail" to record ongoing events which will be delivered in JSON format to an Amazon S3 Bucket of your choice.



You can configure the trail to log read-write, read-only, write-only data events for all current and future S3 buckets
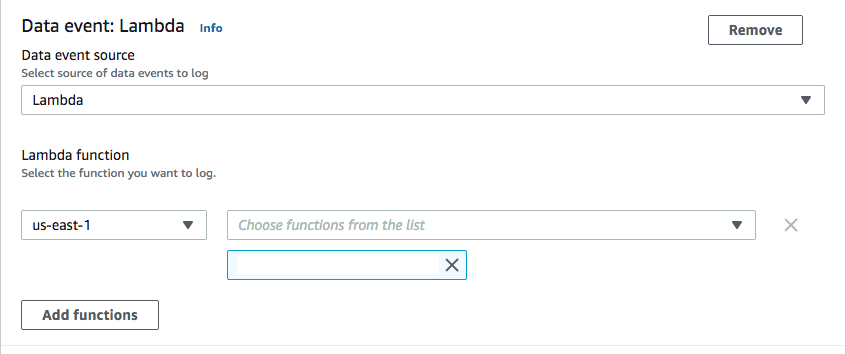
Also, you have the option to log data events for Lambda functions. You can select all region, all functions or specify any specific Lambda ARN or region.
The trail creates small, mostly KB size gzipped json files in the S3 Bucket.
You can select the file and use "Select from" tab to view the content of the file.
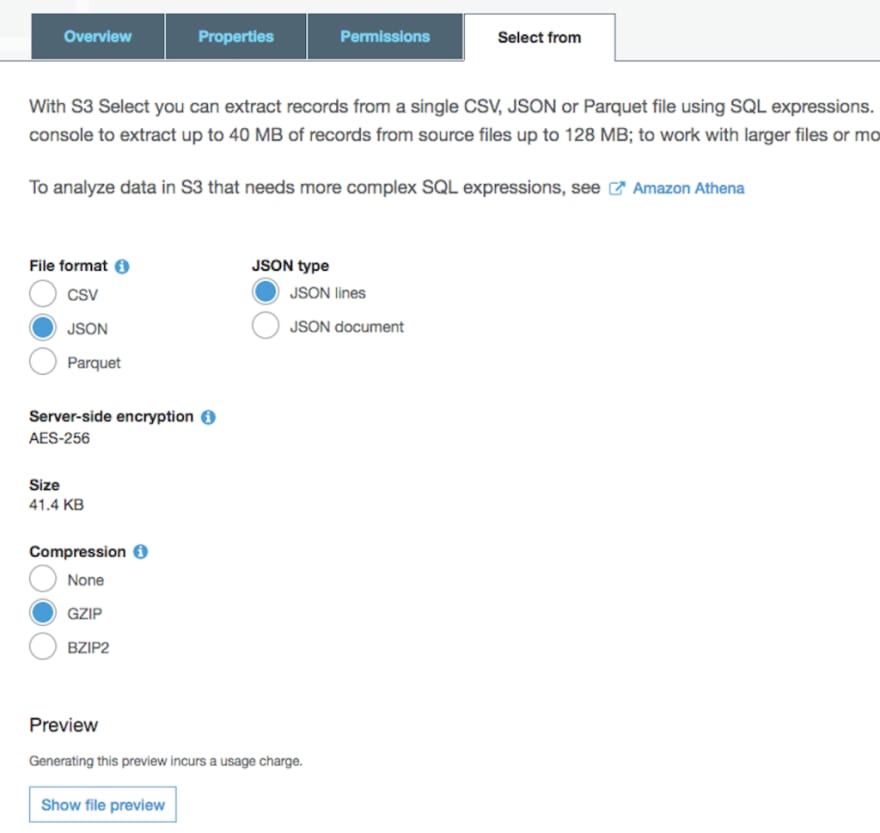
Below is an example of "PutObject" event to S3 bucket.
{
"eventVersion": "1.07",
"userIdentity": {
"type": "AWSService",
"invokedBy": "s3.amazonaws.com"
},
"eventTime": "2020-09-12T23:53:22Z",
"eventSource": "s3.amazonaws.com",
"eventName": "PutObject",
"awsRegion": "us-east-1",
"sourceIPAddress": "s3.amazonaws.com",
"userAgent": "s3.amazonaws.com",
"requestParameters": {
"bucketName": "my-data-bucket",
"Host": "s3.us-east-1.amazonaws.com",
"key": "mydatabase/mytable/data-content.snappy.parquet"
},
"responseElements": null,
"additionalEventData": {
"SignatureVersion": "SigV4",
"CipherSuite": "ECDHE-RSA-AES128-SHA",
"bytesTransferredIn": 107886,
"AuthenticationMethod": "AuthHeader",
"x-amz-id-2": "Dg9gelyiPojDT00UJ+CI7MmmEyUhPRe1EAUtzQSs3kJAZ8JxMe+2IQ4f6wT2Kpd+Czih1Dc2SI8=",
"bytesTransferredOut": 0
},
"requestID": "29C76F4BC75743BF",
"eventID": "6973f9b1-1a7d-46d4-a48f-f2d91c80b2d3",
"readOnly": false,
"resources": [
{
"type": "AWS::S3::Object",
"ARN": "arn:aws:s3:::my-data-bucket/mydatabase/mytable/data-content.snappy.parquet"
},
{
"accountId": "xxxxxxxxxxxx",
"type": "AWS::S3::Bucket",
"ARN": "arn:aws:s3:::my-data-bucket"
}
],
"eventType": "AwsApiCall",
"managementEvent": false,
"recipientAccountId": "xxxxxxxxxxxx",
"sharedEventID": "eb37214b-623b-43e6-876b-7088c7d0e0ee",
"vpcEndpointId": "vpce-xxxxxxx",
"eventCategory": "Data"
}
CloudTrail provides a useful feature under Event history to create Athena table over the trail's Amazon S3 bucket which you can use to query the data using standard SQL.


Now, depending on the duration and events captured, CloudTrail would create lots of small files in S3, which can impact execution time, when queried from Athena.
Moving ahead, I will show you how you can use AWS Data Wrangler and Pandas to perform the following:
- Query data from Athena into Pandas dataframe using AWS Data Wrangler.
- Transform eventtime string datatype to datetime datatype.
- Extract and add year, month, and day columns from eventtime to dataframe.
- Write dataframe to S3 in Parquet format with hive partition using AWS Data Wrangler.
- Along with writing the dataframe, how you can create the table in Glue catalog using AWS Data Wrangler.
For this example, I have setup a Sagemaker Notebook with Lifecycle configuration. Once you have the notebook open, you can use conda_python3 kernel to work using AWS Data Wrangler.
Import the required libraries
import awswrangler as wr
import pandas as pd
pd.set_option('display.width', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.notebook_repr_html', True)
pd.set_option('display.max_rows', None)Python function to execute the SQL in Athena using AWS Data Wrangler
def execute_sql(sql, database, ctas=False):
return wr.athena.read_sql_query(sql, database, ctas_approach=ctas)SQL query to get details related to S3 Events
s3ObjectSql = """
SELECT
useridentity.sessioncontext.sessionissuer.username as username,
useridentity.sessioncontext.sessionissuer.type as type,
useridentity.principalid as principalid,
useridentity.invokedby as invokedby,
eventname as event_name,
eventtime,
eventsource as event_source,
awsregion as aws_region,
sourceipaddress,
eventtype as event_type,
readonly as read_only,
requestparameters
FROM cloudtrail_logs_cloudtrail_logs_traillogs
WHERE eventname in ('ListObjects', 'PutObject', 'GetObject') and eventtime > '2020-08-23'
"""Execute the sql and have results in Pandas dataframe
data = execute_sql(sql=s3GObjectSql, database='default')
Find unique username(just for fun)
data['username'].value_counts()If you observe, eventtime column is "string" datatype so performing any date transformations will be difficult. So here we will create a new column with datetime datatype and drop eventtime.
String to Datetime conversion for eventtime column
data['event_time'] = pd.to_datetime(data['eventtime'], errors='coerce')

data.drop('eventtime', axis=1, inplace=True)Lets extract and add year, month, day columns from event_time column. With this change you can write the data back to S3 as Hive partitions.
Extract and add new fields to dataframe
data['year'] = data['event_time'].dt.year
data['month'] = data['event_time'].dt.month
data['day'] = data['event_time'].dt.dayNow using AWS Data Wrangler s3.to_parquet API you can write the data back to S3 partitioned by year, month, day, and in parquet format. You can also add database and table parameters to it, to write the metadata on Athena/Glue catalog. Note that the database must exists to be command to be successful.
wr.s3.to_parquet(
df=data,
path='s3://my-bucket/s3_access_analyzer/cloudtrail/',
dataset=True,
partition_cols=['year', 'month', 'day'],
database='default', # Athena/Glue database
table='cloudtrail' # Athena/Glue table
)You can query the Athena to view the results

The query took just 1.74 seconds to complete with 0 KB of data scanned. Now why 0 KB? Well, I will leave that for you to think and answer :)
To conclude, with AWS Data Wrangler you can easily and efficiently perform extract, transform and load (ETL) task as shown above. It is well integrated with other AWS services and is actively being updated with new features and enhancements.

Top comments (0)