As organizations increasingly adopt data-driven approaches to solve complex business problems, the need for collaborative data engineering and analytics platforms has never been greater. Databricks, a unified analytics platform built on Apache Spark, offers a powerful solution for managing and processing big data workloads in cloud environments. One of the key features that makes Databricks particularly effective for team collaboration is its implementation of optimistic concurrency control.
Understanding Concurrency Challenges in Data Lake Operations
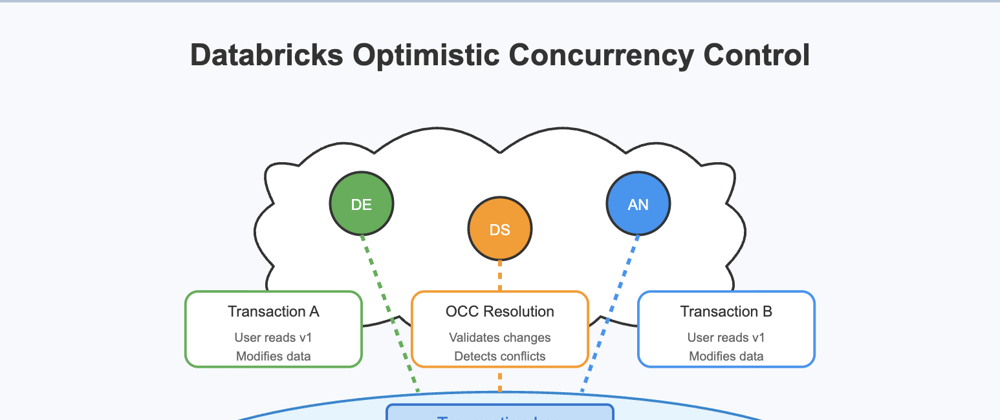
Before diving into optimistic concurrency control, let's understand the problem it solves. In modern data platforms, multiple users often need to access and modify the same datasets simultaneously. This concurrent access can lead to conflicts, data inconsistency, and the "last writer wins" problem where changes from one user overwrite another's work without warning.
These challenges are particularly acute in data lake environments, where teams of data engineers, data scientists, and analysts might all be working with the same tables and files. Without proper concurrency control, collaboration becomes risky and error-prone.
What is Optimistic Concurrency Control in Databricks?
Optimistic concurrency control (OCC) is an approach to managing concurrent access to data that assumes conflicts between users will be rare. Rather than locking resources when they're accessed (a pessimistic approach), optimistic concurrency control allows multiple users to read and modify data simultaneously, then validates changes before committing them.
Databricks implements OCC in its Delta Lake storage layer, providing ACID transactions and version control for data lake operations. This implementation enables collaborative data engineering workflows while maintaining data integrity and consistency.
How Databricks Implements Optimistic Concurrency Control
Databricks' optimistic concurrency control works through several key mechanisms:
1. Transaction Log Architecture
At the core of Databricks' OCC is the Delta Lake transaction log, which records all changes to tables as a series of atomic commits. Each transaction is represented as a JSON file that contains information about what changed, allowing Databricks to:
- Track the complete history of changes to a table
- Enable time travel queries to access previous versions
- Validate concurrent modifications to prevent conflicts
2. Version Control and Snapshot Isolation
When a user reads from a Delta table, they see a consistent snapshot of the data at a specific version. This snapshot isolation ensures that reads are never affected by concurrent writes, providing a stable view of the data throughout a transaction.
3. Commit-Time Conflict Detection
When a user attempts to commit changes, Databricks checks if the table has been modified since the user's transaction began. If another user has made changes that conflict with the current transaction, Databricks will detect this and can:
- Abort the transaction
- Provide detailed information about the conflict
- Allow for programmatic conflict resolution in some cases
4. Automatic Retry Mechanisms
To make optimistic concurrency control more user-friendly, Databricks provides automatic retry mechanisms that can handle many types of conflicts without user intervention. For example, if a transaction fails due to a conflict, Databricks can automatically retry the operation using the updated base state.
Benefits of Optimistic Concurrency Control for Data Teams
Implementing optimistic concurrency control in your Databricks workflows offers several significant advantages:
Enhanced Collaboration Capabilities
Data teams can work simultaneously on shared datasets without fear of corrupting each other's work. This parallel development accelerates project timelines and improves team productivity.
Data Consistency and Integrity
OCC ensures that all changes to data maintain ACID properties (Atomicity, Consistency, Isolation, Durability), preventing data corruption and maintaining the integrity of your data lake.
Improved Performance for Concurrent Workloads
By avoiding locks that could block operations, optimistic concurrency control generally provides better performance for workloads with multiple concurrent users compared to pessimistic locking approaches.
Simplified Debugging and Auditing
The transaction log created by Databricks' OCC implementation provides a complete history of changes, making it easier to audit operations and debug issues when they occur.
Implementing Optimistic Concurrency Control in Databricks
Let's look at how to work effectively with optimistic concurrency control in Databricks:
Basic Table Operations with Concurrency Control
When creating and modifying Delta tables in Databricks, OCC is applied automatically. Here's a simple example of creating a Delta table:
# Create a Delta table
data = spark.range(0, 1000)
data.write.format("delta").save("/path/to/delta-table")
# Read from the table
df = spark.read.format("delta").load("/path/to/delta-table")
Handling Concurrency Conflicts
When conflicts occur, Databricks provides detailed error messages that help identify the issue. For example, you might see an error like:
ConcurrentModificationException: The Delta table has been modified by other transactions after the transaction was started.
You can handle these conflicts programmatically:
from delta.exceptions import ConcurrentModificationException
try:
# Attempt to write to the table
df.write.format("delta").mode("overwrite").save("/path/to/delta-table")
except ConcurrentModificationException as e:
# Handle the conflict
print(f"Conflict detected: {e}")
# Potentially resolve and retry
Advanced Concurrency Control with Condition Predicates
For more precise control, you can use condition predicates to specify the conditions under which a write operation should succeed:
from delta.tables import DeltaTable
deltaTable = DeltaTable.forPath(spark, "/path/to/delta-table")
# Update with condition
deltaTable.update(
condition="id = 5",
set={"value": "new_value"},
predicate="version = 3" # Only succeed if current version is 3
)
Best Practices for Working with Optimistic Concurrency Control
To get the most out of Databricks' optimistic concurrency control, consider these best practices:
1. Design for Conflict Avoidance
Structure your workflows to minimize the likelihood of conflicts. For example:
- Partition data to reduce the chance of users modifying the same files
- Use smaller, more frequent transactions rather than large, long-running ones
- Implement application-level coordination for highly contentious resources
2. Implement Proper Error Handling
Always include error handling for concurrency exceptions in your code, especially for automated processes that might run unsupervised.
3. Monitor Transaction Metrics
Databricks provides metrics on transaction success rates, retry counts, and conflict occurrences. Monitor these to identify potential issues with your concurrency patterns.
4. Use Version Control Features Strategically
Take advantage of Delta Lake's time travel capabilities to implement more sophisticated conflict resolution strategies when needed.
Conclusion
Optimistic concurrency control in Databricks is a powerful feature that enables collaborative data engineering and analytics while maintaining data integrity. By understanding how it works and following best practices, data teams can build robust, concurrent workflows that scale with their organization's needs.
As data volumes and team sizes continue to grow, leveraging these concurrency control features becomes increasingly important for maintaining productivity and data quality. Whether you're building ETL pipelines, performing interactive analytics, or deploying machine learning models, Databricks' optimistic concurrency control provides the foundation for collaborative, reliable data operations.
Have you encountered concurrency challenges in your Databricks workflows? Share your experiences and solutions in the comments below!

Top comments (0)