
Pandas 1.0.0 has been released. In this post, I have compiled the list of important changes that have been made.
Faster df.apply()
Apply now supports an engine key that allows the user to execute the routine using Numba instead of Cython. For rows greater than 1 million, the Numba engine can yield a significant increase in speed.
Dedicated string data type
String data type is now separate from the object data type. String data type is still experimental and probably shouldn't be used in production code. But it's nice to see a dedicated string type in the dataset. Also, in cases where you need to differentiate the string and object data types in the data, this change will come in handy.
NA singleton to denote missing values
Pandas used several values to represent missing data:
- np.nan for float data
- np.nan or None for object-dtype data
- pd.NaT for datetime-like data.
pd.NA provides a “missing” indicator that can be used consistently across data types.
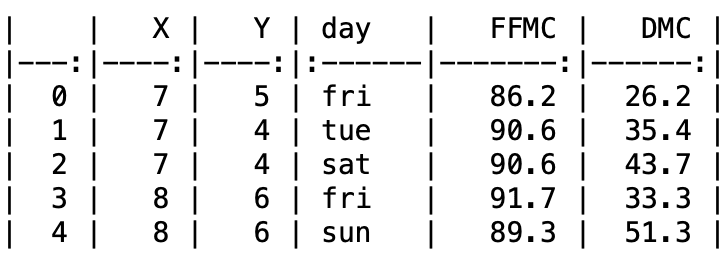
Markdown table
The data frame can now be printed as a markdown table using df.to_markdown()
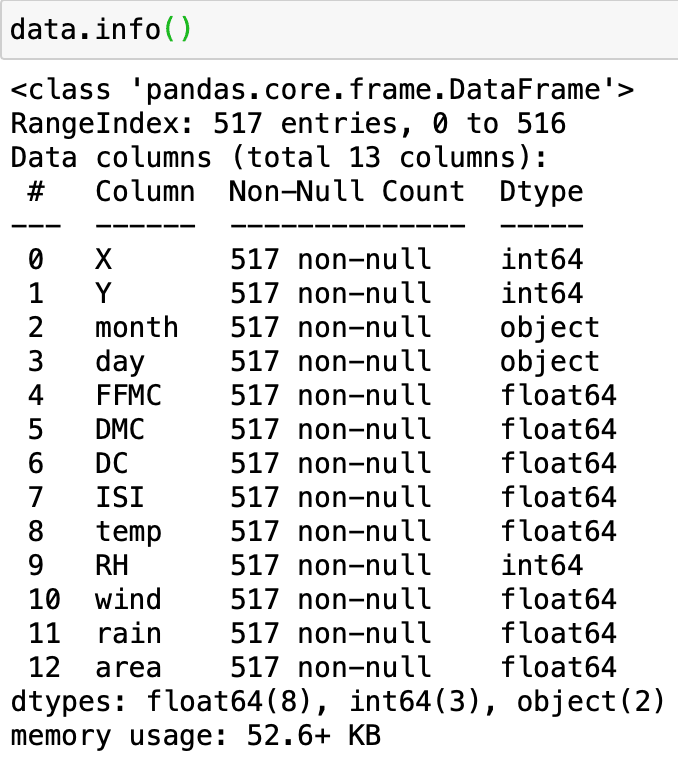
Better summary with DataFrame.info()
The dataframe summary now uses a more readable style
You can use pip install pandas==1.0.0rc0 to install pandas 1.0 into your python environment.

Top comments (0)