
Written by:
Andy Anske, Detection Engineer, Datadog
Zack Allen, Director of Security Research, Datadog
Overview
In January 2021, Ubiquiti disclosed a data breach in systems hosted by a third party cloud provider to their customers. The company sent emails to their customers and created two posts [1][2] on their official forum. The second post was a response to the investigative report released by Brian Krebs [3] detailing the incident. According to Krebs’ source, an attacker gained administrative access to the company’s AWS environment, which was then used to steal sensitive data. The actors allegedly attempted to extort the company for 50 Bitcoin ($2.8 million dollars at the time) to not release the data.
Almost a year later, the FBI released an indictment [4] of the actor, a former employee, who allegedly abused their privileged access to compromise the company in an insider threat scenario. The indictment outlines fascinating insight into the incident, and had details revolving around the Tactics, Techniques and Procedures (TTPs) used to masquerade the exfiltration of sensitive company data.
In this blog post, we will outline the techniques described in the indictment, map them to the MITRE ATT&CK framework, and provide a Detection Engineering methodology to the attack so others can perform logging and detection for these techniques moving forward.
Malicious Insiders, Threat Detection Engineering and MITRE ATT&CK
According to Maybury et al, a malicious insider “.. is motivated to adversely impact an organization’s mission through a range of actions that compromise information, confidentiality, integrity and/or availability” [5]. The authors in [5] then proceed to explore various ways to detect a malicious insider, and one of their hypotheses focused on “..fusing information from heterogeneous information sources” which “.. allows more accurate and timely indications and warnings of malicious insiders”.
Sixteen years later, this hypothesis remains grounded in best practices for Threat Detection Engineering. Detection Engineering is a concept in information security where security analysts, engineers and researchers create a hypothesis for finding a threat, generate one or many detections (via some DSL) for that hypothesis, and then see how well this detection performs in an environment. Red Canary has a fantastic blog [6] on how they use Detection Engineering to generate “tip-offs” for their response teams.
In an AWS cloud logging scenario, each product has some level of logging on the data or control plane. Our hypothesis for this insider threat breach is the following: if we map MITRE ATT&CK techniques to the tradecraft in the Ubiquiti breach, there should be ample log and detection coverage to help detect a malicious insider similar to the actor in this breach.
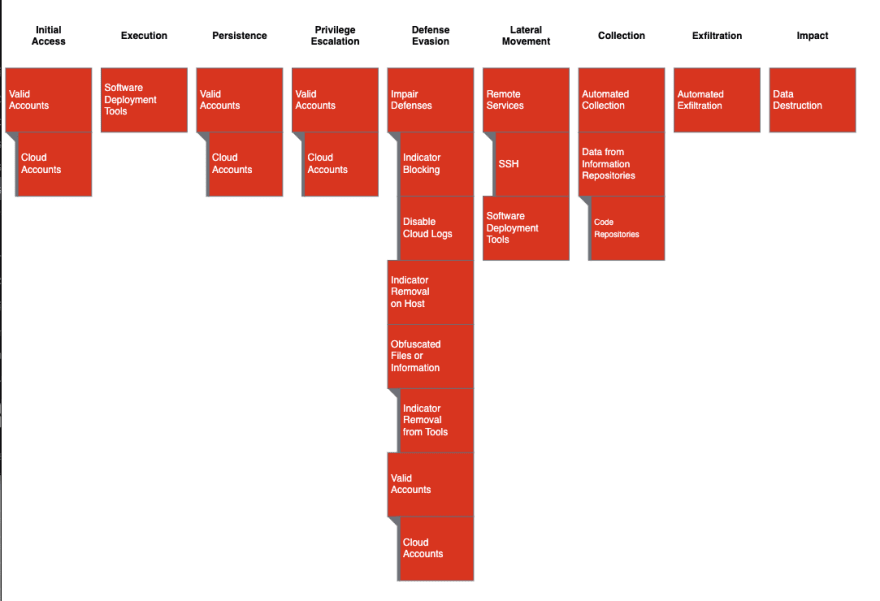
Figure 1: Datadog’s MITRE ATT&CK Map for Ubiquiti Breach
Figure 1 outlines Datadog’s attempt to map tradecraft listed in the indictment to MITRE ATT&CK. MITRE ATT&CK is a threat scenario modeling framework commonly used by the security industry. It provides a taxonomy of attacks against victim infrastructure during the lifecycle of the attack. For example, in Figure 1, we know the actor used Valid Cloud Accounts to log into AWS and change logging policies, so we marked Cloud Accounts under Initial Access, Persistence, Privilege Escalation and Defense Evasion.
There are some notable techniques highlighted here:
Access to Cloud accounts provides a massive advantage to attackers who want to breach and organization
A malicious insider with privileged access might have the ability to remove traces of the breach using Cloud accounts
Use of common development tools (SSH & Git) allows for enough lateral movement capability to start collecting and exfiltrating sensitive data
The actor made a number of attempts to reduce the efficacy of audit logs, and at times destroyed them
For this detection exercise, let’s focus on log disruption. Section 20 of the indictment hints at the use of privileged account credentials in AWS where the alleged “..applied one-day lifecycle retention policies to certain logs on AWS which would have the effect of deleting certain evidence of the intruder’s activity within one day”.
A quick Google search for “lifecycle retention policy amazon” reveals the possible AWS technology the alleged tried to tamper with: S3 Bucket Lifecycle Configuration. Next, we’ll have a look at how logs - and in particular CloudTrail logs - should be handled to maintain their integrity. Then, we’ll discuss detection strategies for identifying an attacker attempting to cover their tracks using the same technique as the alleged Ubiquiti hacker.
Centralizing logs to guarantee their integrity
Whether in traditional or cloud environments, centralizing logs is paramount to ensure their integrity. Logs should be immutable, and an attacker should not be able to tamper with them, even if they have gained elevated privileges within the environment.
In our context, AWS best practices dictate to enable CloudTrail at the AWS Organization level, instead of at the account level. This also has the benefit of automatically turning on CloudTrail in all regions, in all your current accounts and the ones you create in the future. The target of this organization trail should be a S3 bucket created in a dedicated account for logging. This way, an attacker gaining administrative privileges to an AWS account cannot disrupt CloudTrail logging, nor remove logs. It also makes it much easier to collect your logs, and send it to an external service like Datadog. See also Stage 3 of the “Cloud Security Maturity Roadmap” from Scott Piper.
Finally, any S3 bucket with sensitive data should have versioning enabled, and - when not using IAM federation - MFA delete enabled. See also: S3 backups and other strategies for ensuring data durability.
Detecting abuse of AWS S3 Lifecycle Management
AWS created lifecycle configurations in S3 as a way to improve fault tolerance and for users to manage the cost of their data after it reached some policy threshold. An effective lifecycle logging configuration can also be used by security teams. Incidents are not always found as soon as they happen - some of the largest organizations find out about security breaches from days to years after they happen. For example, threat actors compromised Solarwinds for months before they were found 7.
To keep storage pricing effective for your organization you can use Amazon S3 Intelligent-Tiering (shown below) or you can create a transition action in a lifecycle policy. A transition action will move your data to a different data storage service after a certain amount of time specified by the administrator. Another action you can take is to create an expiration action in a lifecycle policy. This will delete objects in a bucket after a certain amount of days [8]. This action was applied to the CloudTrail log bucket by the insider threat mentioned above. For more information about these actions and creation of a lifecycle configuration see the Managing your storage lifecycle in AWS documentation.

The reason this is so important is because the attacker updated an existing policy to have AWS delete the CloudTrail logs after 1 day. These CloudTrail logs are what enables security teams to audit actions across different AWS services like IAM, S3, EKS (managed kubernetes), etc. Without these logs in a bucket to be reviewed by the security team, the attacker evades them easily. Another useful log for auditing access to S3 buckets is the Amazon S3 server access log. This log will show access to a bucket/object like the one where your CloudTrail logs are stored. For the differences between Amazon S3 server access logging and CloudTrail logging please refer to Logging options for Amazon S3 docs page.
In order to detect this in the future, you need to enable a set of AWS S3 lifecycle logging policies for S3 buckets within your company’s AWS environment. Some examples of these policies can be found on AWS, located here. The image below shows a parsed JSON log that was ingested from Cloudtrail into Datadog’s Log Application and highlights an expiration date being set for the bucket and nonconcurrent versions of files in the bucket.

Another item that can help increase coverage of these TTPs is doing a threat modeling exercise against insider threats within your security team. This method is called STRIDE. STRIDE stands for “Spoofing, Tampering, Repudiation, Information disclosure, Denial of service, and Elevation of privilege”. This model helps answer the question of “What can go wrong in this system?”7 You can also use the AWS Access Analyzer service to “...lets you identify unintended access to your resources and data…”[9].
How does Datadog help?
With Datadog you can ingest the logs for S3 lifecycle policies by enabling the AWS Integration tile using the aws integration documentation. Once the integration is enabled, it will ship and ingest the lifecycle policy logs to your Datadog Account and if you have Security Monitoring enabled, the following out-of-the-box (OOTB) rules will begin alerting immediately.
An AWS S3 bucket lifecycle expiration policy was set to < 90 days - This rule will generate a signal on any bucket that is established with an expiration policy set to less than 90 days. Ideally you would tune this to your critical log buckets such as CloudTrail.
An AWS S3 bucket lifecycle expiration policy was disabled - This rule will generate a signal if somebody disables the expiration period set on a lifecycle configuration. This could help you identify somebody being malicious that does not fully understand the consequences of disabling the expiration period.
An AWS S3 bucket lifecycle policy removed or disabled - This rule will generate a signal if somebody disables the entire lifecycle policy for a bucket and can assist you in identifying a potential malicious action from somebody that is not aware what occurs to a bucket when this happens.
An AWS S3 bucket mfaDelete is disabled - This rule will generate a signal when somebody modifies a bucket configuration to disable requiring multi-factor authentication when deleting objects from a bucket. .
All of our OOTB rules have an associated markdown file that covers the goal, strategy and Triage & response actions that you should take if that rule generates a signal. If a rule is too noisy, you can tune it with suppression lists that will prevent the rule from triggering on that attribute again.
For this set of rules we recommend you clone the rule and adjust the buckets that a signal is generated on and the expiration policy to values that are appropriate for your environment and in accordance with the company’s policies.
References
[1] https://community.ui.com/questions/Account-Notification/96467115-49b5-4dd6-9517-f8cdbf6906f3
[2] https://community.ui.com/questions/Update-to-January-2021-Account-Notification/3813e6f4-b023-4d62-9e10-1035dc51ad2e
[3] https://krebsonsecurity.com/2021/03/whistleblower-ubiquiti-breach-catastrophic/
[4] https://www.justice.gov/usao-sdny/pr/former-employee-technology-company-charged-stealing-confidential-data-and-extorting
[5] Maybury, M., Chase, P., Chikes, B., & Brackney, D. et al (2005). Analysis and Detection of Malicious Insiders. International Conference on Intelligence Analysis, McClean, VA.
[6] https://redcanary.com/blog/detection-engineering/
[7] https://www.mandiant.com/resources/evasive-attacker-leverages-solarwinds-supply-chain-compromises-with-sunburst-backdoor
[8] https://docs.aws.amazon.com/IAM/latest/UserGuide/what-is-access-analyzer.html
[9] https://en.wikipedia.org/wiki/STRIDE_(security)

Top comments (0)