
Background
For a long time, unification or fragmentation were the two most popular predictions for the future of databases. With the advance of digitization, a single scenario cannot meet the needs of diversified applications — making database fragmentation an irreversible trend. While Oracle, the commercial database with the largest market share, has no obvious weaknesses, all sorts of new databases are still entering the market. Today, over 300 databases are ranked on DB-Engines.
An increasing number of application scenarios has exacerbated database fragmentation, making database architecture, protocols, functions, and application scenarios increasingly diversified. In terms of database architecture, the centralized database which is evolved from a single-machine system coexists with the new generation of native distributed databases. In terms of database protocols, MySQL and PostgreSQL, two major open source ecosystems, as well as the service ecosystems provided by depending vendors, also have a foothold in the global database system.
Today, it is normal for enterprises to leverage diversified databases. In my market of expertise, China, in the Internet industry, MySQL together with data sharding middleware is the go to architecture, with GreenPlum, HBase, Elasticsearch, Clickhouse and other big data ecosystems being auxiliary computing engine for analytical data. At the same time, some legacy systems (such as SQLServer legacy from .NET transformation, or Oracle legacy from outsourcing) can still be found in use. In the financial industry, Oracle or DB2 is still heavily used as the core transaction system. New business is migrating to MySQL or PostgreSQL. In addition to transactional databases, analytical databases are increasingly diversified as well.
When i claim that fragmentation is an irreversible trend for the database field, i base my assumptions on the above trends. A single type of database can only be applied to a certain (or a few scenarios at best)in which it excels.
Problems with database fragmentation
With the increasing variety of databases used by enterprises, various problems and pain points also arise.
1. Difficulties in architecture selection
To meet flexible business requirements, the application architecture can be transformed from monolithic to service-oriented and then to microservice-oriented. In this case, the database used to store the core data becomes the focus of the distributed system.
Compared with stateless applications, it is all the more difficult to design a stateful database. Divide-and-conquer is the best practice for distributed systems. Obviously, database systems cannot respond to all service requests with a single product and an integrated cluster.
First of all, a single database category is unable to meet all kinds of business application needs, while maintaining high throughput, low latency, strong consistency, operation and maintenance efficiency, and even stability. It is less likely that a single application requires the coexistence of multiple databases, but the likelihood of multiple applications requiring multiple databases is much higher.
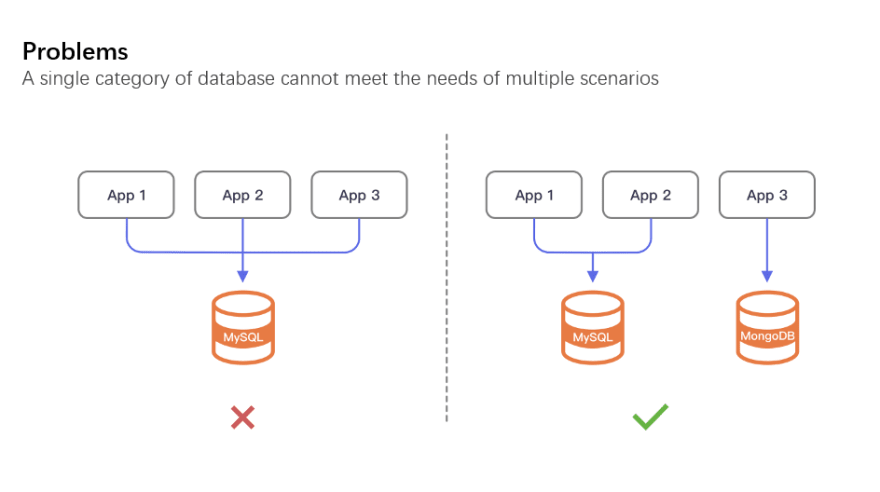
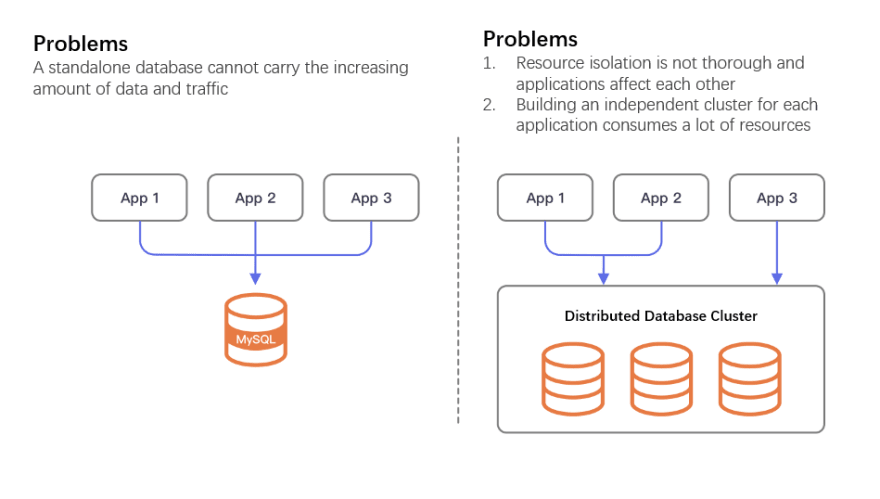
Secondly, no matter if we’re talking about standalone databases or All-in-One distributed database clusters, it is difficult to become the only storage support for the backend of many micro-service applications. Standalone databases cannot carry the increasing amount of data and traffic, so more and more applications choose to adopt distributed solutions. However, if multiple applications use a unified database cluster, the load on CPU, memory, disks, and network cannot be completely isolated. In this case, one application’s excessive resources consumption may lead to quality of service degradation for many unrelated applications.
Today, most distributed databases are expensive to build, requiring backup and redundant standalone servers at the compute node, storage node, and governance nodes. Building an independent distributed database for each micro-service will inevitably lead to unnecessary resource consumption and ultimately become unsustainable for enterprises.
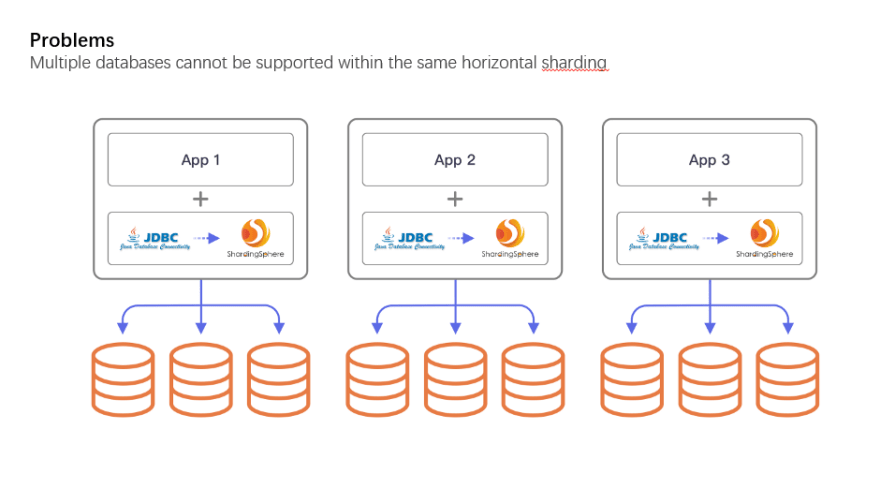
Finally, a large number of enterprises adopt a unitized architecture. Based on the data sharding solution, the split and unification of databases are completed on the application side. As the number of databases increases, the complexity of the architectural design increases exponentially. In the long run, the dev team will be unable to focus on R&D, but will have to dedicate a lot of energy to the maintenance of the underlying components. Although the data sharding feature of Apache ShardingSphere can solve related problems, it can only support the horizontal sharding for a single category of database, which is far from enough in the case of increasingly diversified databases.
2. Numerous technical challenges
When the coexistence of fragmented databases becomes the norm, the development costs and learning curve for R&D teams will inevitably increase constantly. Although most databases support SQL operation, there are still a lot of differences between databases in terms of SQL dialects.
If each database needs to be refined, it will take up a lot of energy of R&D teams, and the accumulated knowledge and experience are hard to be passed on. If we use the heterogeneous database with a coarse-grained standard model, it will annihilate the characteristics of the database itself.
3. High operation & maintenance complexity
It takes a lot of time and practical experience to master the characteristics of various databases and formulate effective operation and maintenance specifications. In addition to the most basic operation and maintenance work, the database peripheral supporting tools are also very different. Monitoring, backup, and other automated operation and maintenance work composed of peripheral supporting tools will incur substantial operation and maintenance costs.
4. Lack of collaboration and unified management among databases
From the perspective of a database, its primary goal is to improve its own capability instead of improving the online compatibility with other databases. Features such as correlated queries and distributed transactions across heterogeneous databases cannot be achieved within the database itself.
Unlike the relatively standard SQL, the protocol of the database itself and the peripheral ecosystem tools lack a unified standard. Increasing attention has been dedicated to the unified management and control of heterogeneous databases. Unfortunately, databases lack upper-level standards, so it is difficult to effectively promote collaboration and unified management between databases.
What is Database Plus?
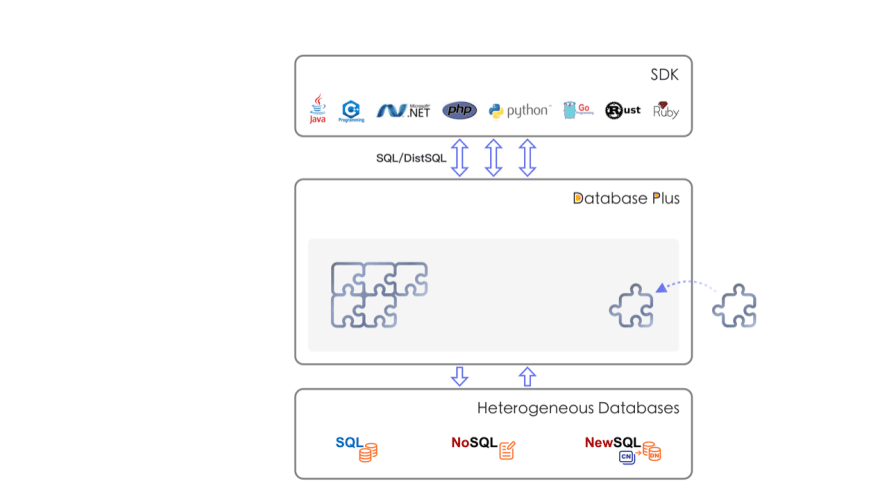
Database Plus is a design concept for distributed database systems, designed to build an ecosystem on top of fragmented heterogeneous databases. The goal is to provide globally scalable and enhanced computing capabilities, while maximizing the original database computing capabilities. The interaction between applications and databases becomes oriented towards the Database Plus standard, therefore minimizing the impact of database fragmentation on upper-layer services.
Connect, Enhance and Pluggable are the three keywords that define the core values of Database Plus.
1. Connect: building upper-level standards for databases
Rather than providing an entirely new standard, Database Plus provides an intermediate layer that can be adapted to a variety of SQL dialects and database access protocols, providing an open interface to connect to various databases.
Thanks to the implementation of the Database access protocol, Database Plus provides the same experience as a database and can support any development language, and database access client.
Moreover, Database Plus supports maximum conversion between SQL dialects. An AST (abstract syntax tree) that parses SQL can be used to regenerate SQL according to the rules of other database dialects. The SQL dialect conversion makes it possible for heterogeneous databases to access each other. This way, users can use any SQL dialect to access heterogeneous underlying databases.
**Database gateway is the best interpretation of Connect. **It is the prerequisite for Database Plus providing a solution for database fragmentation. This is done by building a common open docking layer positioned in the upper layer of the database, to pool all the access traffic of the fragmented databases.
2. Enhance: database computing enhancement engine
Following decades of development, databases now boast their own query optimizer, transaction engine, storage engine, and other time-tested storage and computing capabilities and design models. With the advent of the distributed and cloud native era, original computing and storage capabilities of the database will be scattered and woven into a distributed and cloud native level of new capabilities.
Database Plus adopts a design philosophy that emphasizes traditional database practices, while at the same time adapting to the new generation of distributed databases. Whether centralized or distributed, Database Plus can repurpose and enhance the storage and native computing capabilities of a database.
The capabilities enhancement mainly refers to three aspects: distributed, data control, and traffic control.
Data fragmentation, elastic scaling, high availability, read/write spliting, distributed transactions, and heterogeneous database federated queries based on the vertical split are all capabilities that Database Plus can provide at the global level for distributed heterogeneous databases. It doesn’t focus on the database itself, but on the top of the fragmented database, focusing on the global collaboration between multiple databases.
In addition to distributed enhancement, data control and traffic control enhancements are both in the silo structure. Incremental capabilities for data control include data encryption, data desensitization, data watermarking, data traceability, SQL audit etc.
Incremental capabilities for traffic control include shadow library, gray release, SQL firewall, blacklist and whitelist, circuit-breaker and rate-limiting and so on. They are all provided by the database ecosystem layer. However, owing to database fragmentation, it is a huge amount of work to provide full enhancement capability for each database, and there is no unified standard. Database Plus provides users like you with the permutation and combination of supported database types and enhancements by providing a fulcrum.
3. Pluggable: building a database-oriented functional ecosystem
The Database Plus common layer could become bloated due to docking with an increasing number of database types, and additional enhancement capability. The pluggability borne out of Connect and Enhance is not only the foundation of Database Plus’ common layer, but also the effective guarantee of infinite ecosystem expansion possibilities.
The pluggable architecture enables Database Plus to truly build a database-oriented functional ecosystem, unifying and managing the global capabilities of heterogeneous databases. It is not only for the distribution of centralized databases, but also for the silo function integration of distributed databases.
Microkernel design and pluggable architecture are core values of the Database Plus concept, which is oriented towards a common platform layer rather than a specific function.
ShardingSphere’s exploration of Database Plus
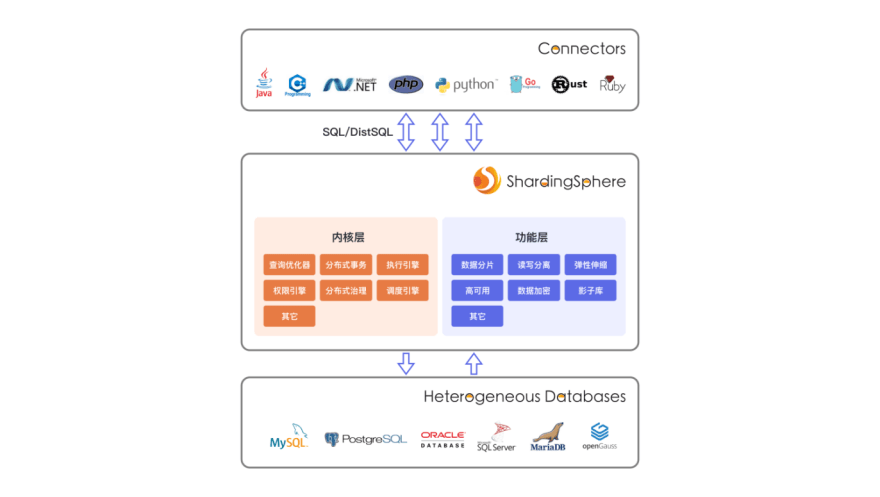
The Apache ShardingSphere project has a long history. From being an open source database sharding middleware to being the Database Plus concept initiator. Currently, Apache ShardingSphere follows the Database Plus development concept and has completed most of its foundations according to the three core values of Database Plus.
1. Connect layers
ShardingSphere supports database protocols such as MySQL, PostgreSQL, openGauss, and MySQL, PostgreSQL, openGauss, SQL Server, Oracle, and all SQL dialects that support the SQL 92 standard.
The abstract top-level interface of the connect layers is open for other databases to interconnect, including database protocols, SQL parsing, and database access.
2. Enhance layers
The function enhancement of ShardingSphere is divided into the kernel layer and the optional function layer.
The kernel layer contains query optimizers, distributed transactions, execution engine, permission engine, and other functions heavily related to the database kernel, as well as scheduling engine, distributed governance, and other functions heavily related to the distribution.
Each module of kernel function must exist, but it can be switched to a different implementation type. Take the query optimizer as an example. If the SQL to be executed can be perfectly pushed down to the backend database, a computational pushdown engine based on the interaction between the original SQL and the database is used. If the SQL to be executed requires correlated queries across multiple data sources, a federated query engine based on the interaction between the query plan tree and the database is used.
In addition to the most typical data sharding and read/write splitting, the functional modules such as high availability, elastic scaling, data encryption, and shadow library are being gradually improved.
3. Pluggable layers
The project has been completely transformed from the original architecture model centered on MySQL plus data fragmentation to the current microkernel plus pluggable architecture. ShardingSphere is completely pluggable from the database types and enhancements that provide connectivity, to its kernel capabilities.
The core and periphery of ShardingSphere architecture are composed of three layers of models realized by microkernel, pluggable interface, and plugins. A single dependence is realized between layers, which means that the microkernel does not need to perceive plug-ins at all and plug-ins do not need to depend on each other. For a large-scale project with 200+ modules, the decoupling and isolation of the architecture is an effective guarantee of open collaboration between communities to minimize the impact of errors.
Summary
Database Plus is the development concept driving ShardingSphere, and ShardingSphere is the best practitioner of the Database Plus concept. As ShardingSphere becomes increasingly mature, the Database Plus puzzle will have found a prime example.
The advantages of Database Plus
Database Plus brings too many benefits for us to be able to list them all in this article. This article will only illustrate its impact on system architecture design and technology selection.
1. Adaptability to flexible application scenarios
You can fully customize features according to your needs. Data sharding is no longer indispensable when using ShardingSphere, and there are many ShardingSphere users who use the data encryption function independently. The pluggable capability of ShardingSphere is not only limited to the database access layer and the function enhancement module itself.
Take data sharding as an example. As a pluggable part of the data sharding module, the sharding algorithm can be fully customized. Whether it is the standard hash, range, time and other sharding algorithms, or custom sharding algorithms, they all can be configured freely and flexibly according to your needs in a bid to achieve optimal performance.
2. Microservice backend support capability for architects
Apache ShardingSphere is the best solution for database unitization at the backend of microservices. As mentioned above, different microservices share a set of distributed database clusters, which cannot be viewed as a perfect and elegant solution in terms of architecture design asymetry or uncontrollable resource isolation. Building a distributed database cluster for each set of microservices would cause unnecessary resources waste.
Compared with the heavyweight distributed database cluster, ShardingSphere-Proxy saves a lot of resources, laying a good foundation for each microservice cluster to have an independent set of database clusters. However, even if the microservice splitting is refined, it still takes a lot of resources to build a set of Shardingsphere-Proxy for each set of microservices. In this case, the less resource-intensive ShardingSphere-JDBC can be used, which is deployed with the application code as a class library with no additional resource footprint.
ShardingSphere-Proxy and ShardingSphere-JDBC can be used in a hybrid deployment to meet needs such as user-friendliness, cross-language adaptation, high-performance, and resource management. Additionally, ShardingSphere-Proxy and ShardingSphere-JDBC can be routed to each other in SQL requests with different characteristics through Traffic Rule to minimize the impact of application resource usage.
Traffic Rule can send the requests consuming more computing resources to ShardingSphere-Proxy which has exclusive resources according to user-defined SQL characteristics (such as aggregate calculation and full-route queries without sharding keys), while reserving transactional lightweight operations at the microservice application end. This coincides with the concept of edge computing, which means the computing capability of ShardingSphere-JDBC in microservice applications is similar to that of edge computing nodes. ShardingSphere-Proxy, which is used for central computing, can deploy independent clusters to serve multiple groups of microservices according to business needs.
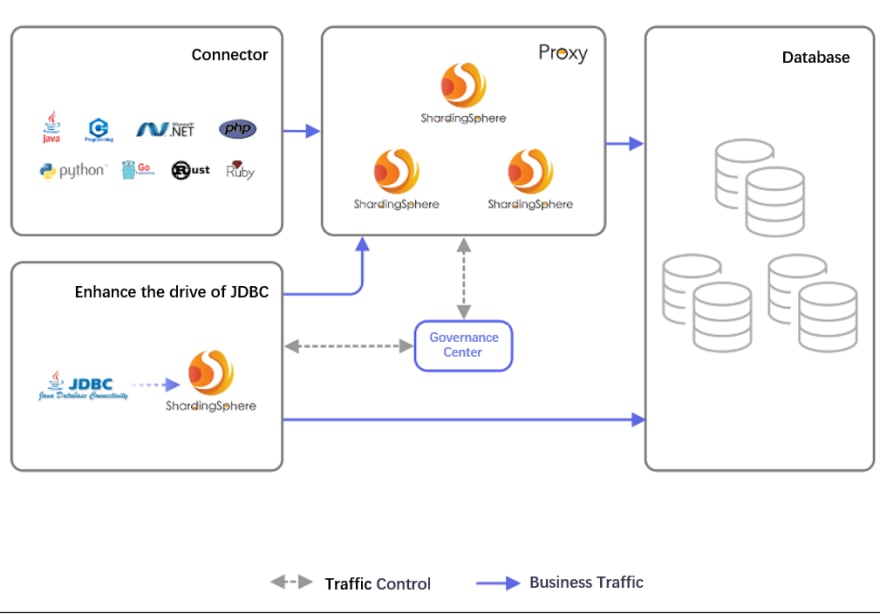
The flexible use of ShardingSphere-Proxy, ShardingSphere-JDBC, and Traffic Rule will continue to support architects’ design inspiration and creativity. As a joke, the proper use of ShardingSphere for elegant system design can be regarded as the threshold for a good architect.
3. DistSQL brings a native database operation experience to DBAs
Whille enhancing functions such as data sharding and data encryption, the previous version of Apache ShardingSphere mainly adopted YAML configuration. For developers, the flexible YAML configuration is convenient to use, but YAML configuration is actually inconvenient for DBAs. Apart from changing the SQL operating habits of DBAs, it is unable to connect with third-party systems such as permission, security, work order, monitoring, and audit.
The new version of Apache ShardingSphere adds DistSQL operation mode. This allows you to use the enhanced features through SQL at any database terminal such as MySQL, Cli, or Navicat. DistSQL matches all of the powerful functions such as data sharding, data encryption, and read/write splitting. You can configure all functions using SQL syntax such as CREATE, ALTER, DROP, or SHOW that the DBA is familiar with. DistSQL also supports the management and control of authorized statements and records all user operations through an SQL audit platform.
The database table structure is the metadata of theDatabase, and enhancement function configuration is the metadata of Database Plus. DistSQL not only improves the user-friendliness, but also completes the final puzzle for the release, operation and maintenance of Apache ShardingSphere.
4. Proxyless model contributes to optimal performance
In the field of Service Mesh, Istio plus Envoy is the most widespread architecture. It manages Envoy through Sidecar deployment while remaining non-intrusive to applications — giving what is called Proxy Service Mesh. It reduces development, use, and upgrade costs but its performance is lowered due to the addition of the Proxy/Sidecar layer in access links.
Proxyless Service Mesh adopts another design model, which derives from the implementation of xDS protocol by gRPC. The new version of Istio allows the application code to pass directly through the SDK provided by Istio Agent through gRPC plus xDS programming, notably improving communication efficiency.
In the field of distributed databases, the architecture design of storage/computing splitting has been widely accepted. The design of splitting compute and storage nodes is somewhat similar to the architectural model of Proxy Service Mesh. ShardingSphere-Proxy is also designed with the aforementioned model. It can effectively reduce development, use, and upgrade costs for users, but its performance is inevitably lowered.
For performance-sensitive applications, ShardingSphere-JDBC, which coincides with the design concept of Proxyless Service Mesh, is undoubtedly more applicable and can be used to maximize system performance. A recent performance test with 16 servers to the TPC-C model using ShardingSphere plus openGauss achieved over 10 million transactions per minute (tpmC), breaking performance records.
Summary
The gRPC’s Proxyless design concept was born recently, while the ShardingSphere-JDBC project has been around since the open source project began in 2016. Therefore, ShardingSphere-JDBC did not refer to the design concept of Proxyless. It was born based on the demand Internet focused businesses from Asia, for maximum performance including high concurrency and low latency.
The same is true for the design of the Database Plus concept, borne out of to solve real world enterprise bottlenecks. ShardingSphere is the best example Database Plus, as its design is derived from real business scenarios. The Chinese Internet vertical where i spent most of my professional experience, is undoubtedly one of the most comprehensive scenarios in the world. Thus, a design concept born in such scenarios must also have extensive room for development.
Future plan
Although the Database Plus concept has witnessed more and more iterations, Apache ShardingSphere still has a long way to go. The database gateway and heterogeneous federated query are the important functional pieces of the puzzle to complete the Database Plus concept.
1. Database gateway
Although Apache ShardingSphere supports the interconnection of heterogeneous databases, it cannot achieve the conversion of dialects between databases. In ShardingSphere’s route planning, SQL dialect conversion is an important function to achieve database gateway. It is no longer a difficult task for users to access MongoDB in MySQL dialect via PostgreSQL’s database protocol.
2. Heterogeneous federated query
Apache ShardingSphere currently only supports federated queries between homogeneous databases. In ShardingSphere’s route planning, federated query between heterogeneous databases will also be put on the agenda. It will no longer be far away for users to query MySQL and HBase with one SQL.
Conclusion
The Apache ShardingSphere community has been active in open source for 7 years. Through perseverance, the community has become mature we’d like to extend our sincere welcome to any devs or contributors who are enthusiastic about open source and coding to collaborate with us.
Among our recent achievements we’re particulary proud of, Apache ShardingSphere’s pluggable architecture and data sharding philosophy have been recognized by the academic community. The paper, Apache ShardingSphere: A Holistic and Pluggable Platform for Data Sharding, has been published at this year’s ICDE, a top conference in the database field.
Author
Zhang Liang, the founder & CEO of SphereEx, served as the head of the architecture and database team of many large well-known Internet enterprises. He is enthusiastic about open source and is the founder and PMC chair of Apache ShardingSphere, ElasticJob, and other well-known open source projects.
He is now a member of the Apache Software Foundation, a Microsoft MVP, Tencent Cloud TVP, and Huawei Cloud MVP and has more than 10 years of experience in the field of architecture and database. He advocates for elegant code, and has made great achievements in distributed database technology and academic research. He has served as a producer and speaker at dozens of major domestic and international industry and technology summits, including ApacheCon, QCon, AWS summit, DTCC, SACC, and DTC. In addition, he has published the book “Future Architecture: From Service to Cloud Native” as well as the paper “Apache ShardingSphere: A Holistic and Pluggable Platform for Data Sharding” published at this year’s ICDE, a top conference in the database field.

Top comments (0)