
I'm a fan of simple database triggers, for audit purposes or otherwise. When you combine them with functions, they can get very powerful. Especially if we start to combine them with AWS's own PostgreSQL extensions, aws_s3.
I'll walk through an example of configuring a trigger to execute a query and output a CSV file to S3, keeping the CSV file up to date. A later post will dig into what we can then use that file for.
Using the aws_S3 extension did require me to use specific versions of the Amazon Aurora PostgreSQL server:

Setup

So we will skip over best practices for Terraform and databases in general, and just quickly stand up a cluster to test on. So don't have public databases, don't connect with the master user.. etc etc..
The code for this is located up on my GitHub repo. This will spin up an Aurora cluster in the default VPC, set it as public and set up a security group that allows anyone to connect to it on port 5432, while it can access anything externally (i.e. S3). It also creates a random bucket that we will dump our export into, and an IAM role that grants the RDS service permission to put objects into that bucket.
Simply head into the terraform-setup folder and execute the Terraform commands:
terraform init
terraform apply -auto-approve
This should take a few minutes as the database cluster stands up, but by the end you should have something similar to the following output:
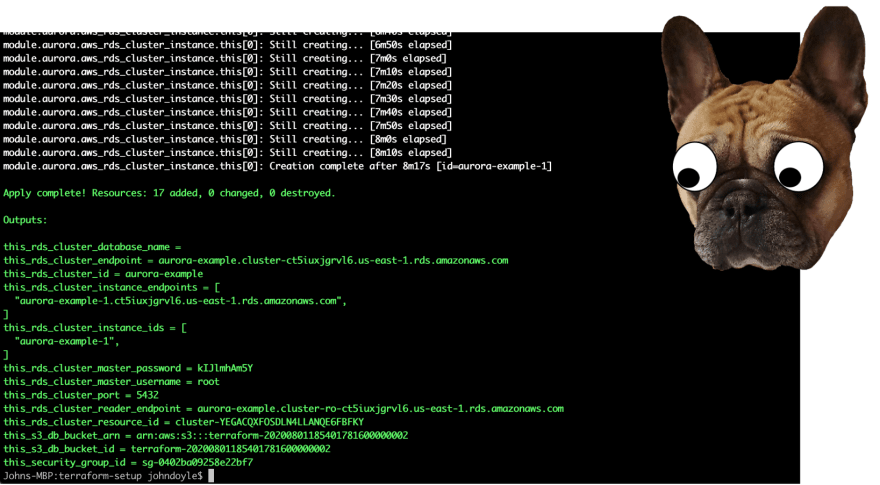
You'll want to note down:
- this_rds_cluster_endpoint
- this_rds_cluster_master_password
- this_s3_db_bucket_id
Now, we are left with one last step. Terraform currently has an issue applying roles to RDS Clusters, so we will use the AWS CLI to accomplish this.
./add_role_to_db_cluster.sh
This will take a few mins to apply fully, but we will keep trucking on.
Connecting to the DB
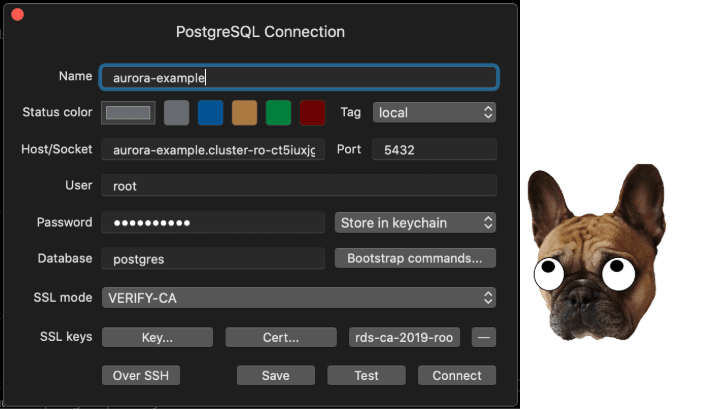
I'll be using TablePlus to connect to the DB, but first we will need to download the AWS CA Certificate for our server.
To get a root certificate that works for all AWS Regions, download it from https://s3.amazonaws.com/rds-downloads/rds-ca-2019-root.pem
Create a new connection with the details you noted down from Terraform, and set the username to root and the database to postgres. Set the SSL mode to VERIFY-CA and add the downloaded rds-ca-2019-root.pem under CA Cert.:
Now we can start working on the good old SQL. Get our extension installed and a sample table:
CREATE EXTENSION IF NOT EXISTS aws_s3 CASCADE;
CREATE TABLE sample_table (bid bigint PRIMARY KEY, name varchar(80));
Output to S3
Lets insert some data in manually to start off:
INSERT INTO sample_table (bid,name) VALUES (1, 'Monday'), (2,'Tuesday'), (3, 'Wednesday');
So we have data in the table, everything is set - and hopefully that role has had enough time to be fully applied to the Cluster!
The SQL to export out to S3 using the extension is:
SELECT
*
FROM
aws_s3.query_export_to_s3(
'select * from sample_table',
aws_commons.create_s3_uri(
'S3_BUCKET_NAME',
'test.csv',
'us-east-1'),
options :='format csv, delimiter $$,$$'
);
You will want to update S3_BUCKET_NAME with the output you noted down from Terraform.
If you receive the error:
Query 1 ERROR: ERROR: credentials stored with the database cluster can’t be accessed
HINT: Has the IAM role Amazon Resource Name (ARN) been associated with the feature-name "s3Export"?
CONTEXT: SQL function "query_export_to_s3" statement 1
Then wait a little longer for the role to apply.
While a successful export will return:
- Rows Updated
- Files Uploaded
- Bytes Uploaded

We can hop over to our bucket to see our new CSV file, test.csv:
aws s3api list-objects --bucket S3_BUCKET_NAME --query 'Contents[].Key'
And we can even download it, and view the output if we want:
aws s3api get-object --bucket terraform-20200801185401781600000002 --key test.csv output.csv && cat output.csv
Now to convert this into a trigger on the table, we first want to have a function that performs our query. Again you will want to update the S3 Bucket to match the Terraform output::
CREATE OR REPLACE FUNCTION export_to_s3()
RETURNS TRIGGER
AS $export_to_s3$
BEGIN
PERFORM aws_s3.query_export_to_s3(
'select * from sample_table',
aws_commons.create_s3_uri(
'S3_BUCKET_NAME',
'test.csv',
'us-east-1'),
options :='format csv, delimiter $$,$$'
);
RETURN NEW;
END;
$export_to_s3$ LANGUAGE plpgsql;
And now, we want to setup a trigger that calls this function on any changes to the table:
CREATE TRIGGER sample_table_trg
AFTER INSERT OR DELETE OR UPDATE OR TRUNCATE
ON sample_table
FOR EACH STATEMENT
EXECUTE PROCEDURE export_to_s3();
Testing
Great! We are now ready to test this - lets add another row to the table:
INSERT INTO sample_table (bid,name) VALUES (4, 'Thursday');
And if we check out the test.csv again, we should see it has been updated:
aws s3api get-object --bucket terraform-20200801185401781600000002 --key test.csv output.csv && cat output.csv
I'll follow up with another post on how we can really make use of this functionality with Amazon's new "code free" service, Amazon Honeycode!
Shutdown
Oh, and obviously lets clear everything up - don't want that public DB hanging around!
terraform destroy -auto-approve

Latest comments (0)