Previously, I tried to achieve my scalability requirements without using a cache-aside pattern to protect by downstream service, and the results could have been better. Read more here.
My current application is in the current status:
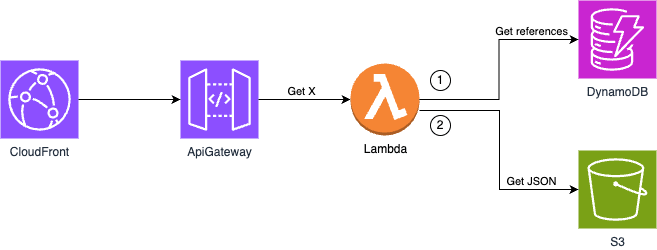
To enable my application to use a cache-aside pattern with Amazon ElastiCache
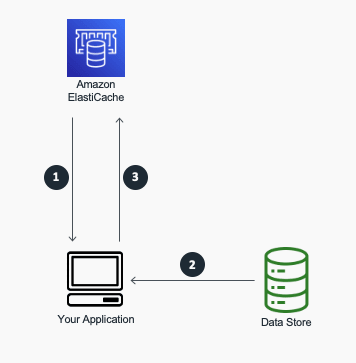
A cache-aside flow can be summarised as follows:
Check the Cache first to determine whether the data is available.
If the data is available, it is a cache hit, and the cached data is returned.
If the data isn't available, it is a cache miss. The database is queried for the data. The Cache is then populated with the data retrieved from the database, which is returned.
Please read more Source
I need to move my Lambda into a VPC.

Let's stop here for a moment and see what is going on:
My application flow is changing with the following step:
- Get from DynamoDB the references of request X
- Get JSON values from Cache, and return if I have a HIT
- If I have a MISS fallback into S3, and put them into Cache
Apart from the additional logic, there is a slight disparity from the initial setup.
The big changes are at the infrastructure level, and as you can see from the image above, I need to configure my account with Subnets:
- A subnet where I deploy my Lambda
- A subnet where I deploy my ElastiCache cluster
- VPC Endpoint for DynamoDB and S3
- Security groups to allow connection into the ElastiCache cluster subnet only from the Lambda subnet on a specific port 6379
- Plus all the other networking security routing in case of a NAT Gateway
- Optional subnet for your NAT Gateway if you need an outbound connection from your Lambda
Once I have done all of this without considering the time spent transforming myself from a software developer to a networking professional, I now have a possible cost burden on my infrastructure:
- 2 VPC Interface endpoints with 3 Availability Zones, and this has fixed cost in eu-central-1 is 52.56 USD, plus data processed N GB x 0.0100000000 USD
- Data Transfer is the same cost in VPC or not
- If I use NAT Gateway, I need to pay for a fixed price of 3 NAT Gateways of 113.88 USD, plus, of course, data processing costs X GB per month x 0.052 USD in eu-central-1
- Amazon ElastiCache for Redis for TEST, and here it is like gambling because now I could have 1 node for my test environment with the smallest instance, like a cache.t3.small and get a fixed cost of 27.74 USD
- Amazon ElastiCache for Redis for Production is a different discussion. How do I size it? Imagine it is a new service. I can guess based on the data I have inside S3 and do a rough calculation for network bytes IN/OUT, but the reality is I do not know how to size it, and I do not know anybody who could, and the famous pattern "just in case" will bring me to select some instance type like 3 nodes Cache.r6g.large with a fixed cost of 540.93 USD
After spending time in configuration and polite guessing of instance types, I finally reached the point of returning to my application and delivering values.
I started working with ElastiCache, and I can see immediately that I have 2 types of clients:
- ClusterClient
- Client
After researching, I realised that I needed to use ClusterClient. Therefore, I plan to modify my TEST cluster and add two more nodes to make it a three-node cluster. I don't need to change my code, though. However, with three nodes, my cost has increased to 83.22 USD, and I'm not sure if my manual tests will work as expected with such a small cluster.
let client = redis::cluster::ClusterClient::new(vec![
"rediss://mycluster-0001-001.mycluster.xxx.euc1.cache.amazonaws.com:6379",
"rediss://mycluster-0001-002.mycluster.xxxx.euc1.cache.amazonaws.com:6379",
"rediss://mycluster-0001-003.mycluster.xxx.euc1.cache.amazonaws.com:6379",
])?;
let redis_conn: redis::cluster_async::ClusterConnection = client.get_async_connection().await?;
Before I continue, I would like to explain why I use DynamoDB to find my Cache key references.
When using ElastiCache for Redis, I could search for all the keys at once using a pattern-matching feature called KEYS[https://redis.io/commands/keys/]. However, I discovered that this method could cause issues when dealing with large data. This operation could potentially crash the cluster by executing a SCAN command on a database. While it works fine with smaller records, it's not recommended for larger datasets.
I wasted time on this because I am not an expert on all commands. It turned out to be better to do more calls in parallel but use the efficient GET.
After confirming that my application was functioning as intended, I proceeded to conduct a load test:
- Item cached in the CDN for 3 minutes
- Test time 2h
- Total requests ~200M
- RPS > 10K
The results:
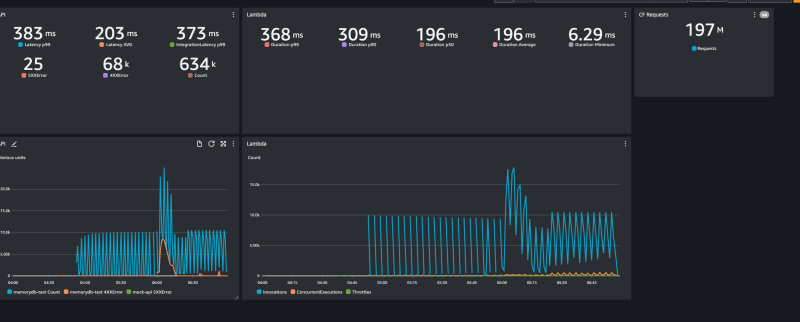
The success story is that I cut almost half the duration of the Lambda with a cache-aside pattern compared to the previous test.
The reality is armageddon during the following scenarios:
- Failover
- Scaling up and down
Plus, with the most tedious of all, MISS when the key exists

People always ask me why I do those kinds of tests, and sarcastically (with my Italian accent) I respond:
"Right!!! Always forget that nothing is failing."
As everything Amazon ElastiCache is not free from issues, and the main ones to consider are:
- Memory usage - If the dataset grows larger than the available memory, it can lead to performance issues or even crashes
- Client Reconnections - In high-traffic situations, Redis clients may need to frequently reconnect to the server due to network issues or connection timeouts.
- Commands - Some Redis commands can lead to contention and slow down the system in high-request scenarios.
- Scale Up - Bursty workload often takes more than 5 min to be detected (need for and add capacity). Burst is usually over before autoscaling kicks in.
- Cold Caches During Scale Up - Partitions are created when scaling up the cluster, requiring time to hydrate. This is called "cold cache", and during this time, there are performance degradations.
Overprovisioning the cluster is a potential result of all these issues. The "just in case pattern" of scaling up/down during events is risky as it could result in a large number of errors, leading to "Cache Avalanches". These avalanches can saturate the network bandwidth, leading to system failures across clusters and severely impacting your downstream services.
Conclusion
The journey to scalability also means embracing changes. I have to change my application architecture, increase the infrastructural complexity, and make peace with the extra fixed costs given by the infrastructure choice.
A loading test is essential to verify the architectural choice, and it turned out that while I decreased the p99 of my service, I still have the potential of catastrophic failure given by the Amazon ElastiCache component that I need to maintain and manage. The ~70K errors in the simulation showed me that my application will fail. It is just a matter of when.
I firmly believe that overprovisioning because of the "just in case pattern" is a bad practice. As a developer, I know failure is around the corner, and I cannot avoid it. Still, I need to build and architect my application to mitigate those issues, keeping the cost down and allowing me to focus on what counts. Managed Amazon ElastiCache was the first step in the right direction, but it still forced me into particular consideration.
The next article will explore an alternative to ease my development with Serverless Cache Momento.

Top comments (0)