A time series database is a database optimized for time-stamped or time-series data. Typical examples of this kind of data are application performance monitoring logs, network data, clicks in an online application, stock market trading, IoT sensor data, and other use cases where the time of the data is important. So far it seems like something pretty much any database can manage, right? Well, the difference comes around the way the data will be accessed.
All the NoSQL and relational databases depend upon the existence of a key, generally some kind of string or integer. In a time-series database, however, the timestamp is the most important piece of information. This means that applications that look at data within a time range, and it is the time range that is crucial, would be well served by a time-series database because that data will be stored together (much like how relational databases store data in order by primary key) so getting a range of data based on a time range will be faster than getting data stored with a different type of key. Figure 1 shows how this works.

Figure 1. Time-series data stored by timestamp
A typical characteristic of time-series data is that when data arrives it is generally recorded as a new entry. Updating that data is more of an exception than a rule. Another characteristic is that the data typically arrives in timestamp order, so key scanning is minimized, and the data-write can be very performant. A thirds characteristic is that the non-timestamp data is stored as a value and is rarely included as part of the filtering in a query. Scaling is also especially important in time-series databases because there tends to be a lot of frequently created data that ends up being stored in this type of database. The last characteristic, as already mentioned, is that time is the primary axis. Time-series databases tend to include specialized functions around dealing with time series, including aggregation, analysis, and time calculations.
Amazon Timestream
Now that we have briefly defined the concept behind a time-series database, let us look at the AWS entry into the field, Amazon Timestream. Timestream is a serverless, automatically-scaling, database service that can store trillions of requests per day and is exponentially faster than a relational database at a fraction of the cost. Timestream uses a purpose-built query engine that lets you access and analyze recent and historical data together within a single query as well as supporting built-in time-series analytics functions.
Creating an Amazon Timestream database is one of the simplest processes that you will find in AWS. All you need to do is to provide a Database name and decide on the Key Management Service (KMS) key to use when encrypting your data (all Timestream data is encrypted by default). And that is it. Creating a table within the database is almost as simple; provide a Table name and then configure the Data retention policies.
These data retention policies are designed to help you manage the lifecycle of your time-series data. The assumption is that there are two levels of data, data that is frequently used in small segments for analysis, such as “the last 5 minutes”, and data that will be accessed much less often but in larger ranges, such as “last month”. Timestream helps you manage that lifecycle by automatically storing data in two places, in-memory and in a magnetic store. The data retention policies allow you to configure when that transition should happen. Figure 2 shows an example where data is persisted in memory for 2 days and then transferred to magnetic storage and kept there for 1 year.

Figure 2. Configuring the Data Retention policies for a Timestream table
Now that we have looked at creating a Timestream database and table, the next step is to look at how the data is managed within the database as this will help you understand some of the behavior you will see when using the database programmatically. The following are key concepts in Timestream:
· Dimension – describes metadata as key/value pairs and can be 0 to many within a record. An example could be the location and type of a sensor.
· Measure– the actual value being measured, as a key/value pair
Now that we have briefly discussed Timestream databases, our next step is to look at using it in a .NET application.
.NET and Amazon Timestream
We have spent some time accessing database services on AWS that are designed to emulate some other product, such as Redis. Timestream does not take that approach. Instead, you need to use the AWS SDK for .NET to write data to and read data from Timestream. The interesting thing about this is that AWS made the decision to break this data access process down by providing two discrete .NET clients for Timestream, the Write SDK client that persists data to the table and the Query SDK client that returns data from the table.
Let’s start our journey into Timestream by looking at a method in the code snippet below that saves an item, in this case, a Measurement.
1 using System;
2 using System.Collections.Generic;
3 using System.Threading.Tasks;
4 using Amazon.TimestreamWrite;
5 using Amazon.TimestreamWrite.Model;
6
7 public class Measurement
8 {
9 public Dictionary<string, double> KeyValues { get; set; }
10 public string Source { get; set; }
11 public string Location { get; set; }
12 public DateTime Time { get; set; }
13 }
14
15 public async Task Insert(Measurement item)
16 {
17 var queryClient = new AmazonTimestreamQueryClient();
18
19 List<Dimension> dimensions = new List<Dimension>
20 {
21 new Dimension {Name = "location", Value = item.Location}
22 };
23
24 Record commonAttributes = new Record
25 {
26 Dimensions = dimensions,
27 MeasureValueType = MeasureValueType.DOUBLE,
28 Time = ConvertToTimeString(item.Time)
29 };
30
31 List<Record> records = new List<Record>();
32
33 foreach (string key in item.KeyValues.Keys)
34 {
35 var record = new Record
36 {
37 MeasureName = key,
38 MeasureValue = item.KeyValues[key].ToString()
39 };
40 records.Add(record);
41 }
42
43 var request = new WriteRecordsRequest
44 {
45 DatabaseName = databaseName,
46 TableName = tableName,
47 CommonAttributes = commonAttributes,
48 Records = records
49 };
50
51 var response = await writeClient.WriteRecordsAsync(request);
52 // do something with result, such as evaluate HTTP status
53 }
When persisting data into Timestream you will use a WriteRecordsRequest, as shown on Line 43 of the above code. This object contains information about the table and database to use as well as CommonAttributes and Records. The CommonAttributes property expects a Record, or a set of fields that are common to all the items contained in the Records property; think of it as a way to minimize the data sent over the wire as well as act as initial value grouping. In this case, our common attributes contain the Dimensions (as discussed earlier) as well as the MeasureValueType which defines the type of data being submitted (although it will be converted to a string for the submission), and Time. This leaves only the list of measurement values that will be put into the Records property. The response from the WriteRecordsAsync method is an HTTP Status code that indicates success or failure.
Pulling data out is quite different; mainly because the process of fetching data is done by passing a SQL-like query string to the AmazonTimestreamQueryClient. This means that a simple query to retrieve some information could look like this:
SELECT location, measure_name, time, measure_value::double
FROM {databaseName}.{tableName}
WHERE measure_name=’type of measurement you are looking for’
ORDER BY time DESC
LIMIT 10
All of which will be recognizable if you have experience with SQL.
This is all well and good, but the power of this type of database really shines when you start to do time-specific queries. Consider the following query that finds the average measurement value, aggregated together over 30-second intervals (binned), for a specific location (one of the dimensions saved with each submission) over the past 2 hours.
SELECT BIN(time, 30s) AS binned_timestamp,
ROUND(AVG(measure_value::double), 2) AS avg_measurementValue,
location
FROM {databaseName}.{tableName}
WHERE measure_name = ’type of measurement you are looking for’
AND location = '{LOCATION}'
AND time > ago(2h)
GROUP BY location, BIN(time, 30s)
ORDER BY binned_timestamp ASC
As you can probably imagine, there are many more complicated functions that are available for use in Timestream.
Note: These time series functions include functions that will help fill in missing data, interpolations, functions that look at the rate of change for a metric, derivatives, volumes of requests received, integrals, and correlation functions for comparing two different time series. You can find all the time series functions at https://docs.aws.amazon.com/timestream/latest/developerguide/timeseries-specific-constructs.functions.html.
Once you have built the query, running the query is pretty simple, as shown below:
public async Task<QueryResponse> RunQueryAsync(string queryString)
{
try
{
QueryRequest queryRequest = new QueryRequest();
queryRequest.QueryString = queryString;
QueryResponse queryResponse =
await queryClient.QueryAsync(queryRequest);
return queryResponse;
}
catch (Exception e)
{
return null;
}
}
However, the complication comes from trying to interpret the results – the QueryResponse object that is returned by the service. This is because you are simply passing in a query string that could be doing any kind of work, so the response needs to be able to manage that. Figure 3 shows the properties on the QueryResponse object.

Figure 3. Object definition of the QueryResponse object
There are five properties in the QueryResponse. The QueryStatus returns Information about the status of the query, including progress and bytes scanned. The QueryId and NextToken properties are used together to support pagination when the result set is larger than the default length, ColumnInfo provides details on the column data types of the returned result set, and Rows contains the results set.
You can see a simple request/result as captured in Telerik Fiddler Classic in Figure 4.
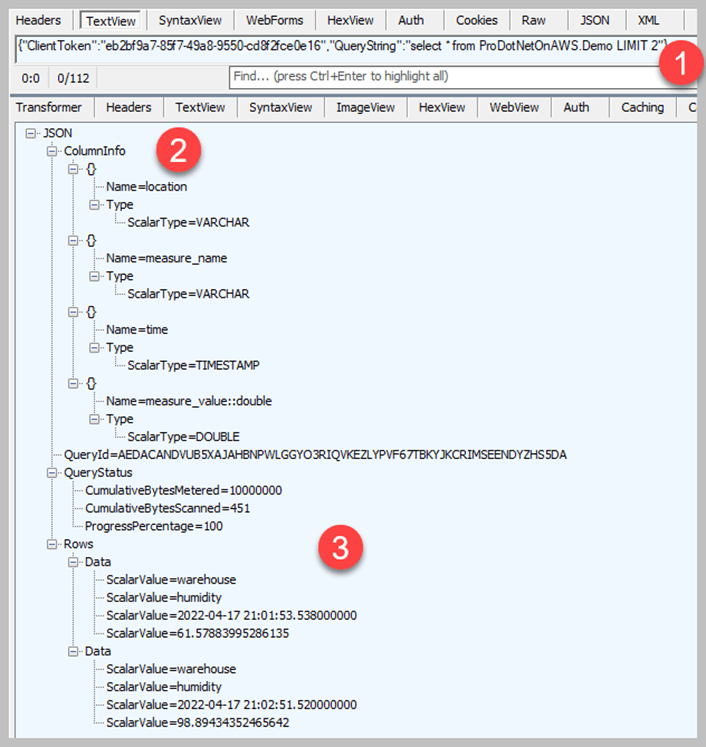
Figure 4. Amazon Timestream query response in JSON
There are three areas called out. Area 1 is the query that was sent, as you can see it is a simple “SELECT ALL” query with a limit put on of 2 rows. Area 2 shows the ColumnInfo property in JSON, with each item in the array corresponding to each of the ScalarValues found in the array of Data that makes up the Rows property.
Looking at this, you can probably see ways in which you can transform the data into JSON that will deserialize nicely into a C# class. Unfortunately, however, AWS did not provide this functionality for you as part of their SDK.

Latest comments (0)