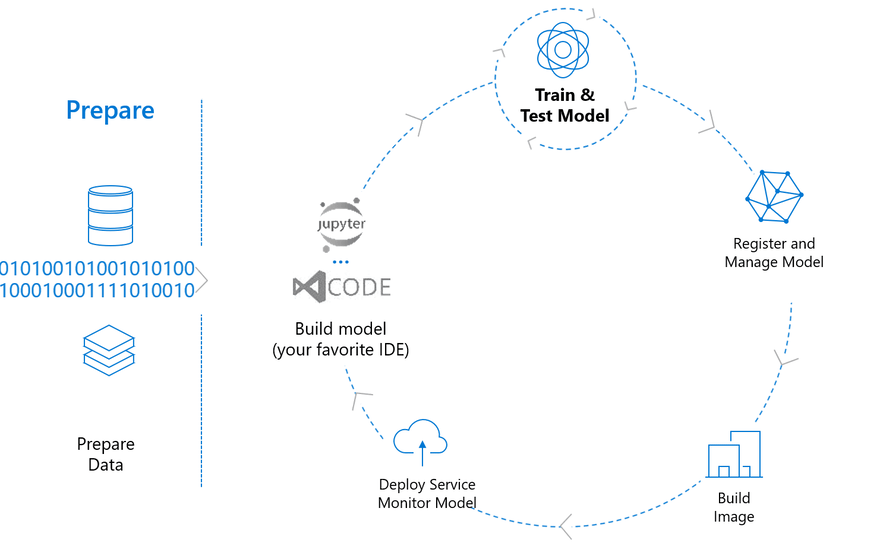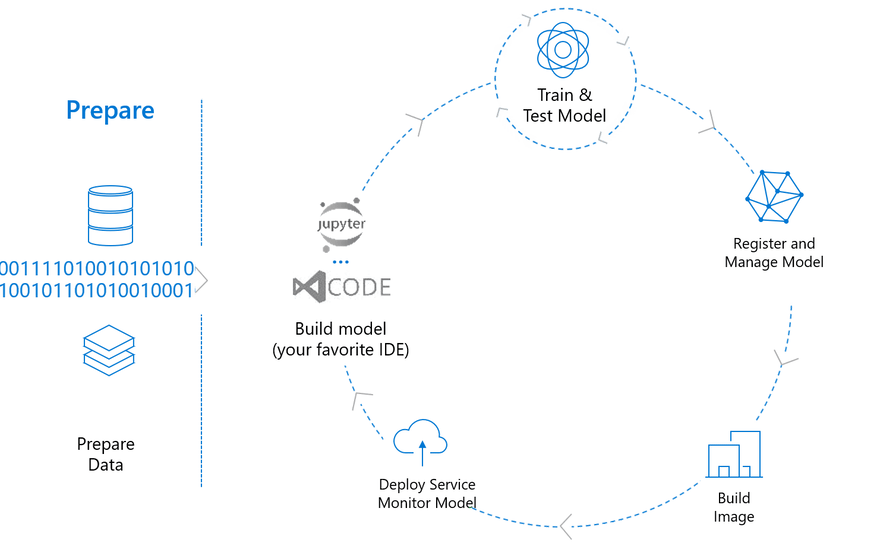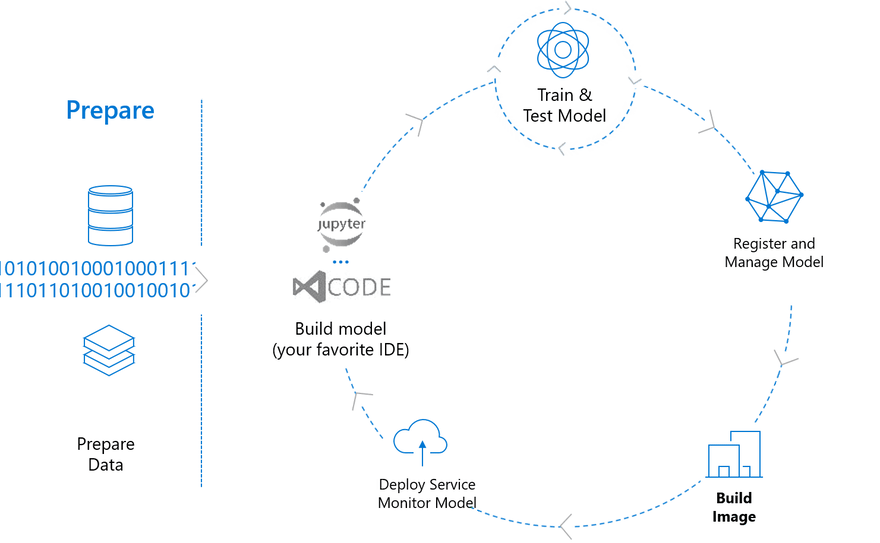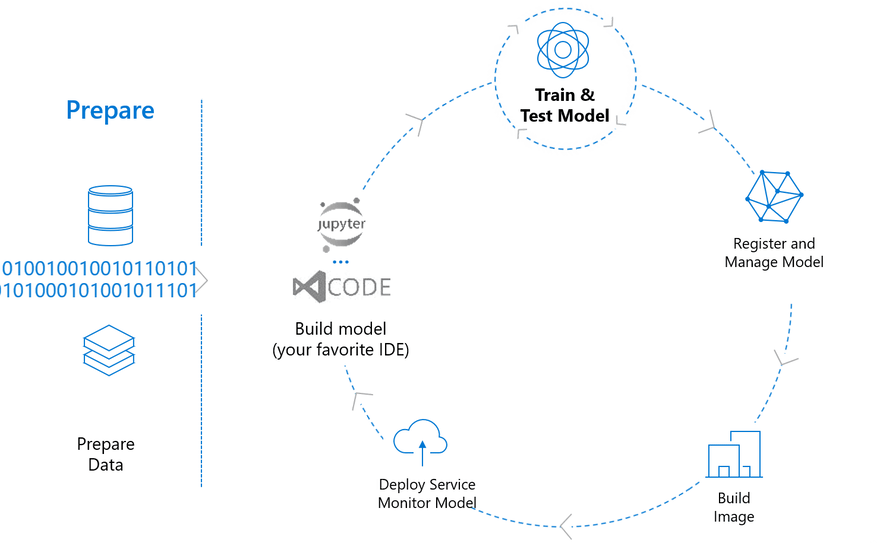
TLDR; Incorporating a new state of the art machine learning model into a production application is a rewarding yet often frustrating experience. The following post provides tips for production Machine Learning, with examples using the Azure Machine Learning Service.
If you are new to Azure you can get a free subscription here.
Create your Azure free account today | Microsoft Azure
While the tips in the following post, transcend Azure, the Azure Machine Learning Service provides structured tooling for training, deploying, automating, and managing machine learning workflows at production scale.
1) Do not Reinvent the Wheel
Before writing the first line of AI code ask whether the problem you are solving really needs a state of the art model? Many scenarios already have existing solutions that are managed and maintained by the top cloud providers.
Cognitive Services | Microsoft Azure
These services are supported, industry compliant, constantly updated, and already integrate into the language and platforms your customers are using. Many of them can be run offline in docker environments and many of these services such as custom vision, custom speech and language understanding can even be customized.
Before reinventing the wheel check to see if these services fit your scenario, you may find that by the time your company puts a state of the art model into production the performance of a managed service will have caught up.
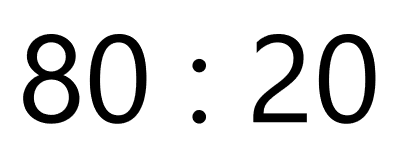
I have found there to be a Pareto 80:20 rule where around 80 percent of the AI tools required by a company at a given time are already in a managed service. However while 80% of scenarios may be covered by cognitive services, the remaining 20% of scenarios tend to be the ones with the most disruptive potential. By not reinventing the wheel you can focus your production efforts on these critical scenarios.
2) Centralize Your Data Pipeline
In research datasets are often provided. but in production managing, securing and wrangling data is much more challenging. Before putting the next state of the art model into production, it’s important to understand your data and use case. The diagram below outlines considerations when ingesting, processing data for production machine learning.

Services such as Azure Storage, Azure Event Hubs, and Azure Data Explorer enable scalable ingestion and processing of your data.
The Azure Machine Learning Service directly integrates with these services through the MLOps SDK. I won’t dive to deeply into these concepts in this post, but check out more about how to centralize and a manage access to data in documentation below.
Create datasets to access data with azureml-datasets - Azure Machine Learning service
3) Keep Track of your Team’s Work
In a research setting, it easy to get used to working on a model alone. In production keeping track of work done across distributed teams can be challenging.
Luckily, the Azure Machine Learning workspace enables teams to manage experiments and keep track of their work.
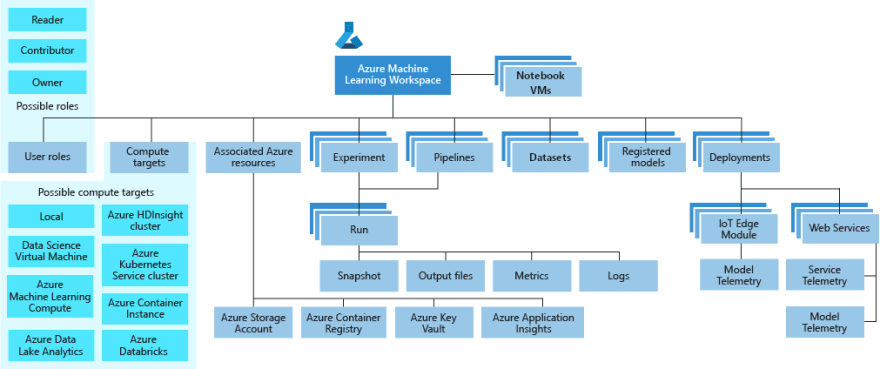
From this workspace, teams can define monitor both classical and custom task metrics across all the given runs on a given to keep track of top performance over time.

When one team member gets stuck another can quickly get access to the logs and help get their team member back on track.
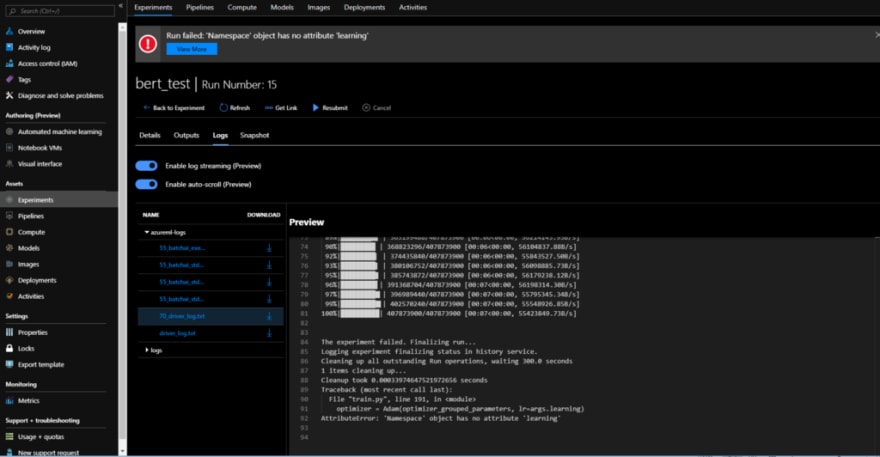
For each run, all code and hyper parameters are snapshotted so that work can be instantly recovered and reverted.

Having the tools to scale a team and keep track of your work is critical to getting a state of the art model into production as fast as possible.
4) Deploy a Solid Baseline
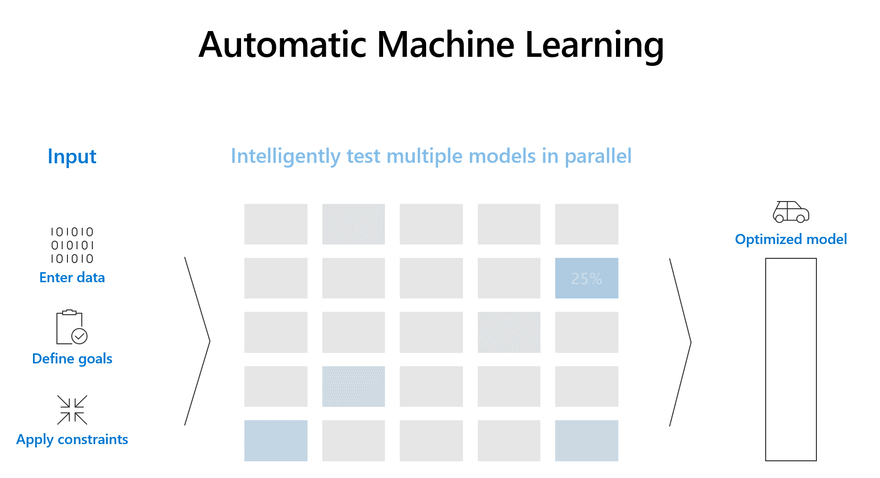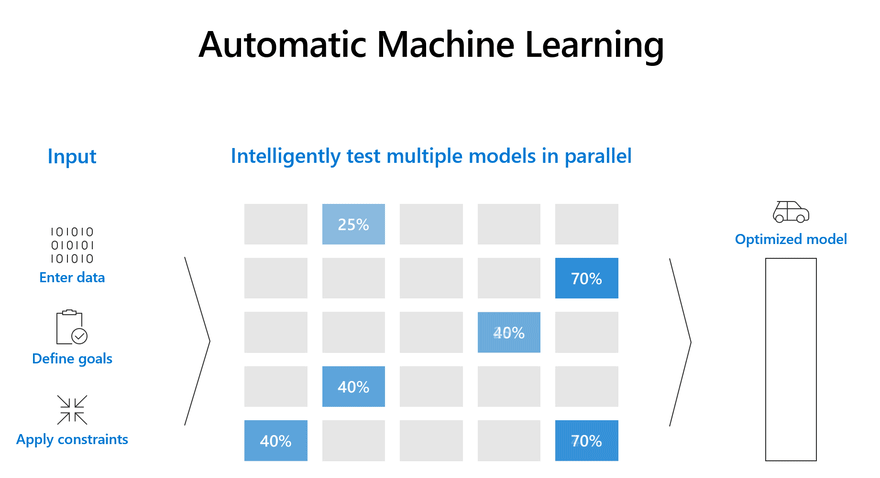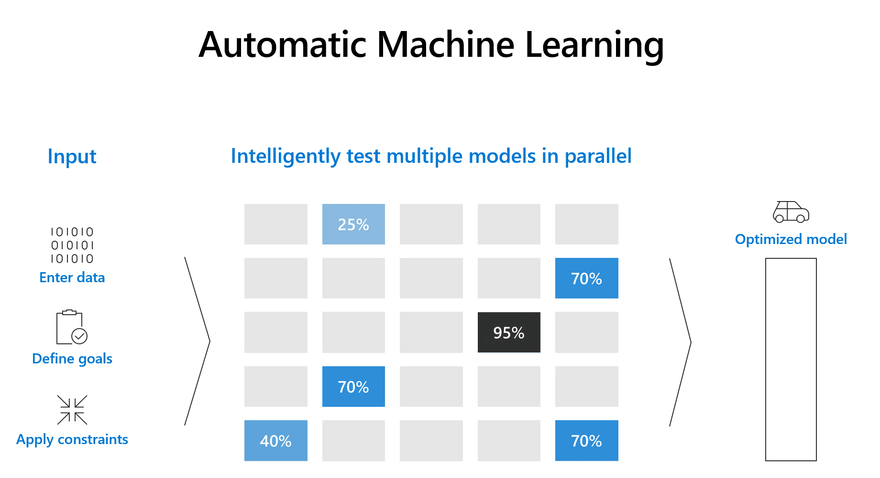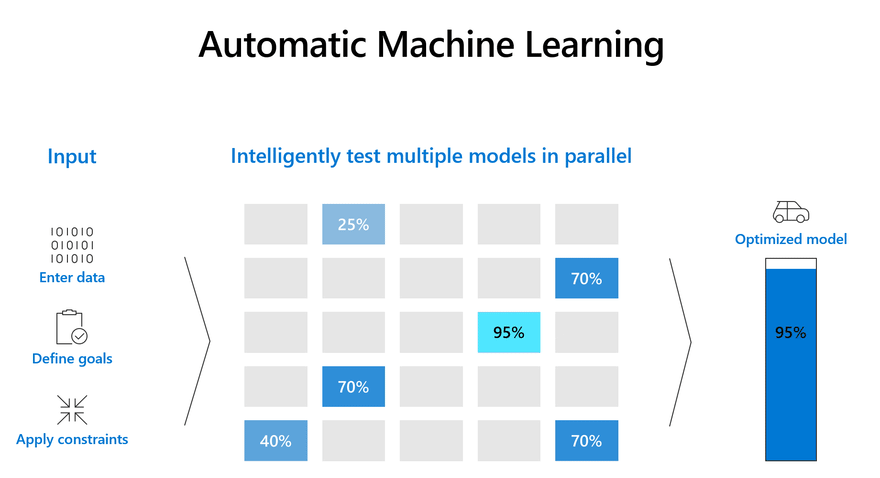
Before deploying a complex state of the art model to production, it makes sense to deploy a solid baseline model.
Having a solid baseline model provides significant advantages. a strong baseline helps to:
- Better understand the deployment process for getting a model into production.
- Evaluate impact of a given solution, if you see that there is a quantifiable return on investment on your baseline then you can use that to justify pouring more resources into a more complex model.
- Provide a point of comparison — for example if the baseline gives an F1 score of 87% on your data but your State of the Art implementation returns 85% the baseline can help you better understand that there is likely a bug in your implementation even though the metrics seem good.
The Azure AutoML service helps generate strong baselines for many tasks without the need to even write a single line of ML code. AutoML automates the process of selecting the best algorithm to use for your specific data, so you can generate a machine learning baseline quickly. To get started check out the AutoML documentation below to learn more about how the service works.
Create automated ML experiments - Azure Machine Learning service
Also check out this great post on Auto ML from the talented Francesca Lazzeri to learn more about the interpreting the results of the service.
Automated and Interpretable Machine Learning
5) Use Low Priority Compute and AutoScaling
Training large state of the art models can be computationally expensive however taking advantage of low priority compute can lead to significant savings by an order of magnitude.
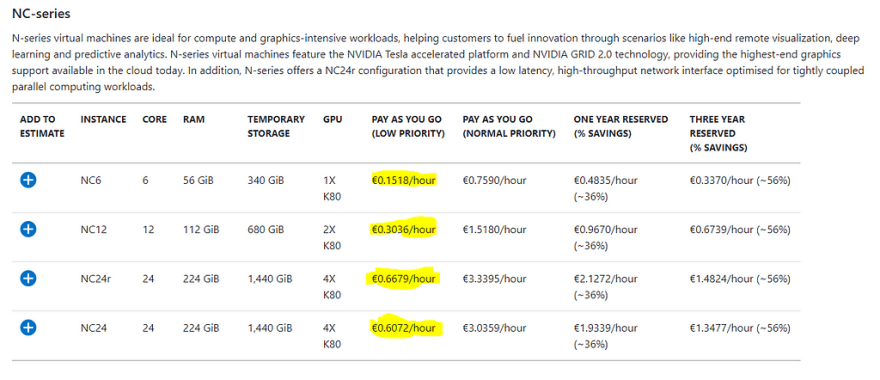
Additionally the Azure Machine Learning Service Supports Auto Scaling which means that if your model at any point eats up all your allocated resources instead of crashing and causing you to loose all your work and spent compute resources, it will automatically scale to your needs and then scale back down when the resources are released.
With these cost savings you can choose to either train your models longer or reduce waste with as little as two lines of code over a traditional deployment.
6) Leverage Distributed Training
There are two traditional approaches to distributed training, distributed batching and distributed hyperparameter optimization. Without distributed training it will be difficult to scale your state of model to production performance.
Traditionally distributed training is hard to manage due to the following issues:
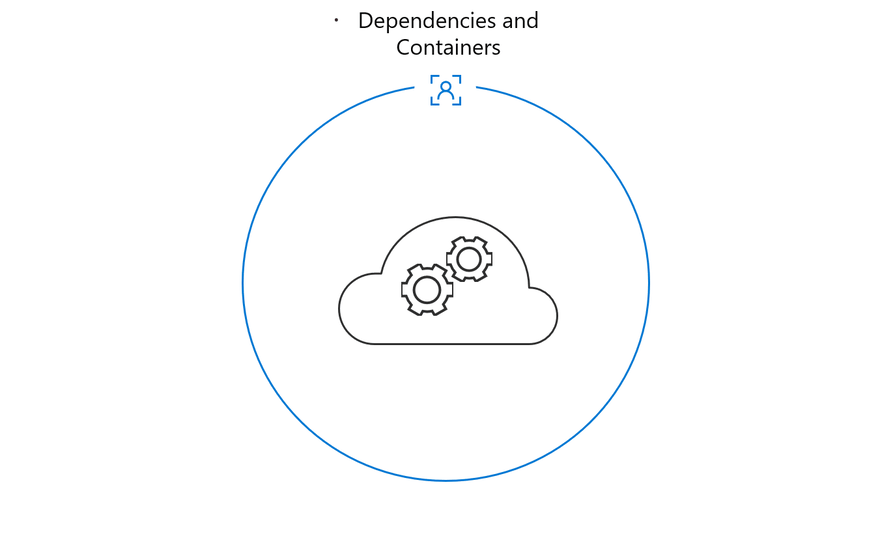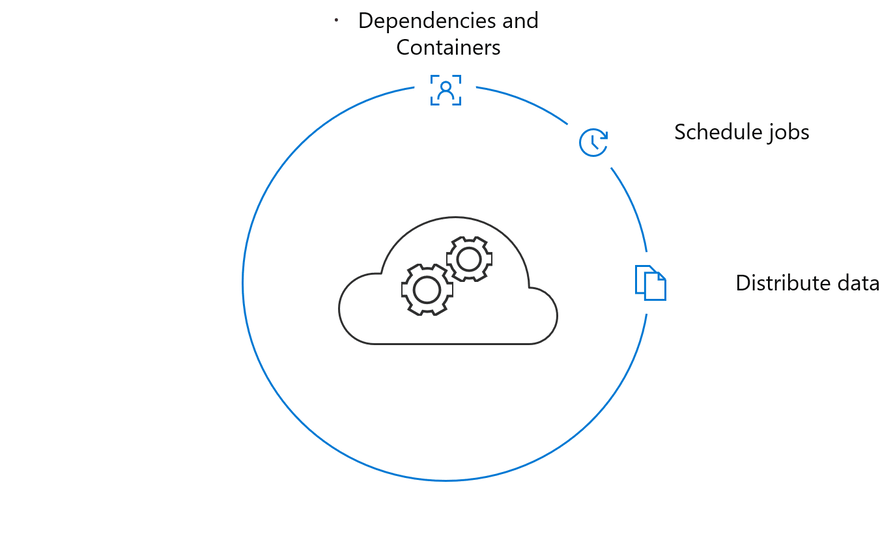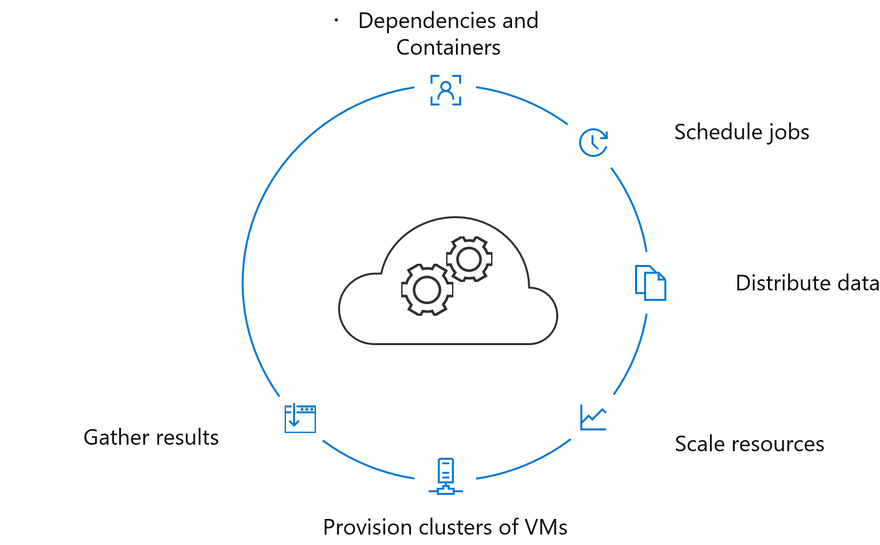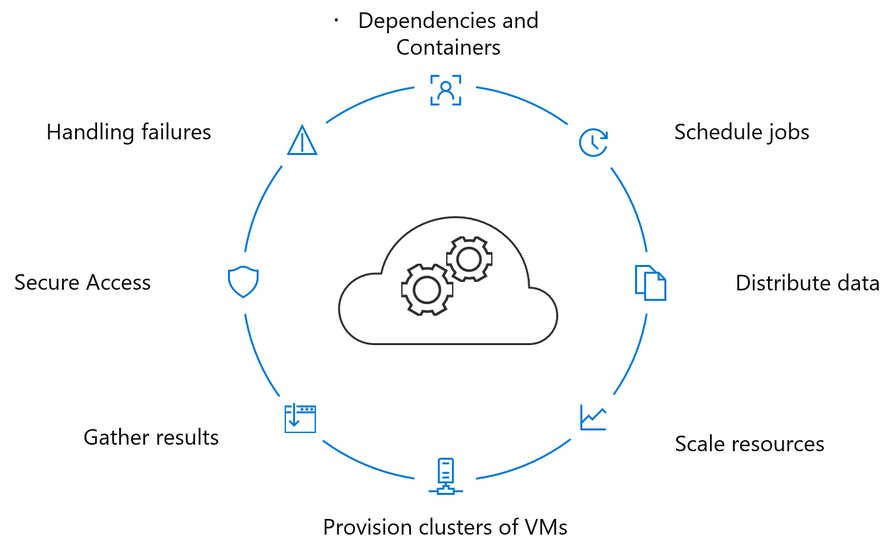
Azure Machine Learning service manages distributed batching with direct integration with MPI and Hovorod.

Additionally the Azure ML service provides HyperDrive, a hyperparameter optimization service that uses state of the art methods for hyperparamater tuning.
Hyperparameters are adjustable parameters, chosen prior to training that govern model training. Model performance heavily depends on hyperparameters and in the state of the art models they are often fined tuned to research data-sets.
It can be hard to find optimal hyperparameters on a new data distribution, since the parameter search space is large, there are very few optimal values and evaluating the whole parameter space is resource and time consuming.
Often in research these parameters are checked manually, one at a time which is inefficient:
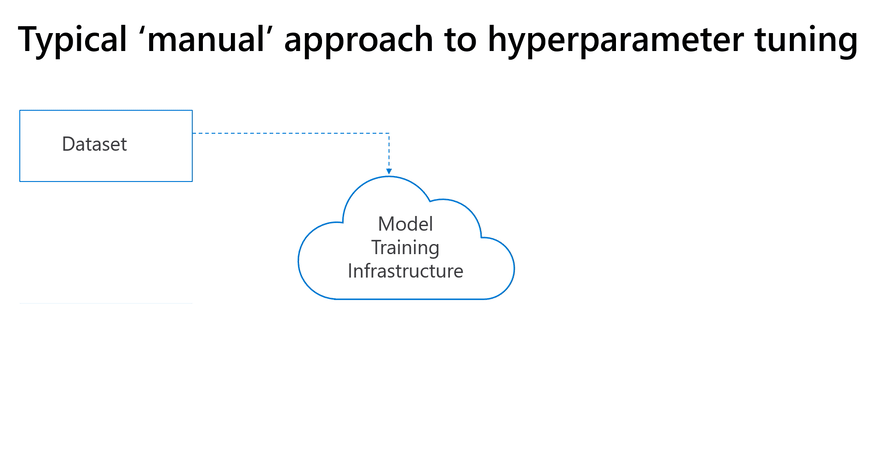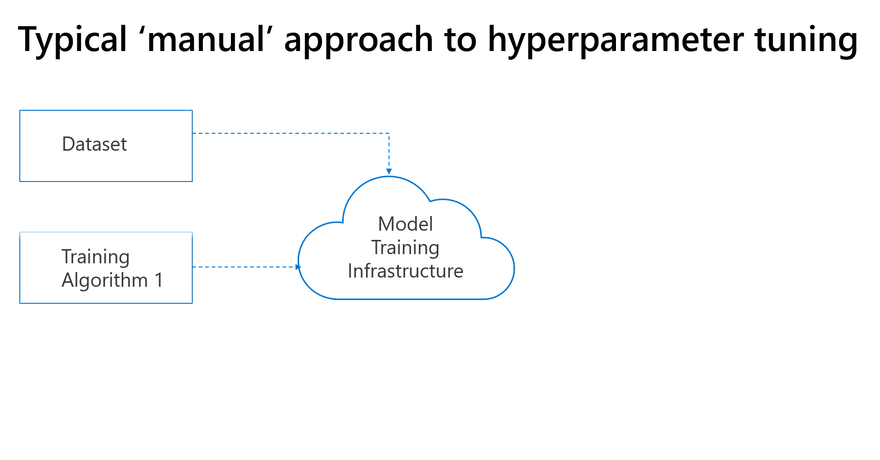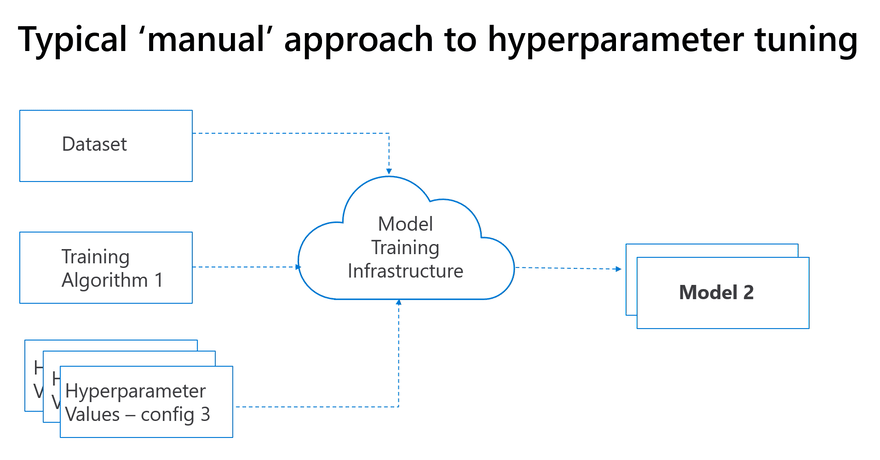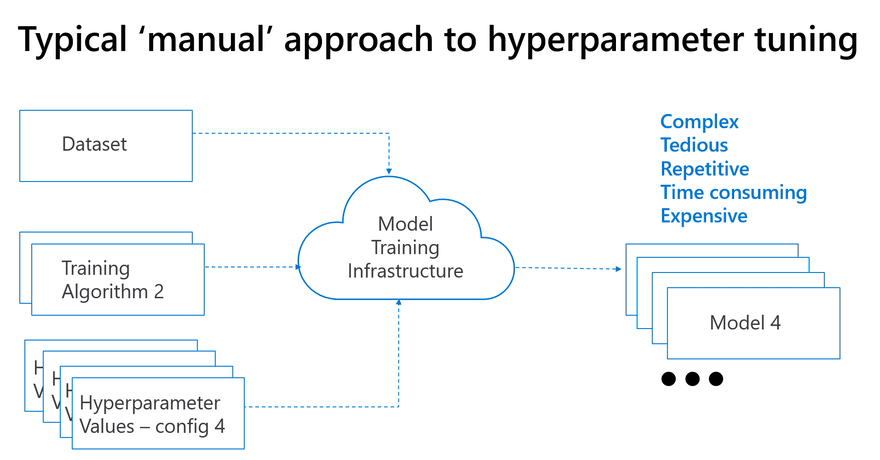
The Hyperdrive Service enables the configuration of hyperparameter search space:
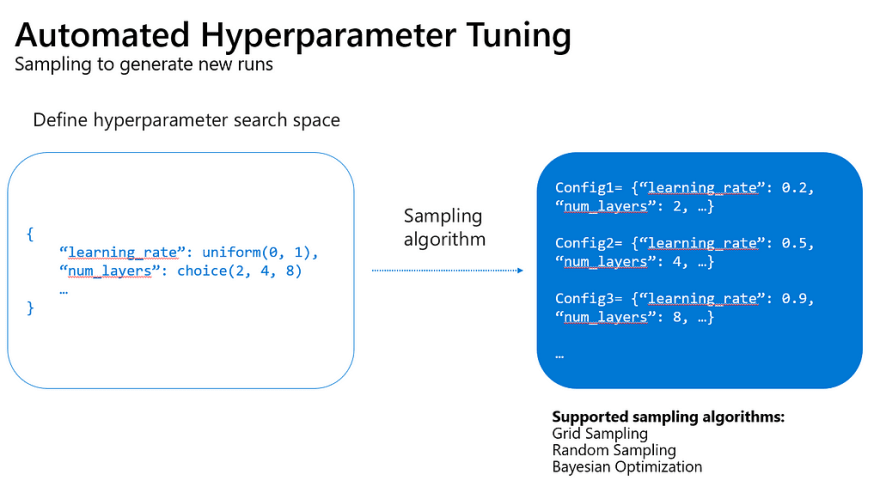
Given a metric it will then run many distributed parameter searches, using state of the art sampling methods and perform early stopping on parameters that do not converge on optimal performance. This results in much more robust state of the art machine learning models.
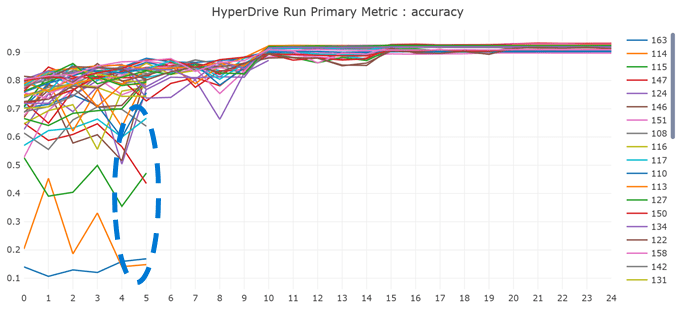
Learn more about the service below:
Tune hyperparameters for your model - Azure Machine Learning service
7) When Possible Deploy to the Edge
Models can be deployed as scalable cloud webservice, hosted on premise or deployed directly to edge devices.

While certain models have restrictive computation and memory requirements whenever possible it’s extremely cost effective to deploy directly to edge devices using either edge modules like in the example below, or web frameworks such as onnx.js or tensorflow.js.
Deploy Azure Machine Learning to a device - Azure IoT Edge
The savings can be reinvested into iterating your model.
8) Perform AB Testing of Different Models
The Azure ML Service makes it easy to manage version and if necessary roll back models. While it may to seem that a model performs better in the training environment in production you may see a different result.
An A/B test enables you to test different model versions across different audiences. Based on conversion rates, KPIs or other metrics, you can decide which one performs best or if it’s time to iterate the next version of the model.
Azure ML Piplelines can help manage these tests and metrics.
What are ML Pipelines - Azure Machine Learning service
9) Monitor Data Drift
Data drift happens when data served to a model in production is different from the data used to train the model. It is one of the top reasons where model accuracy degrades over time, thus monitoring data drift helps detect model performance issues.
With Azure Machine Learning service, you can monitor the inputs to a model deployed on AKS and compare this data to the training dataset for the model. At regular intervals, the inference data is snapshot and profiled, then computed against the baseline dataset to produce a data drift analysis
Detect data drift (Preview) on AKS deployments - Azure Machine Learning service
Hope you enjoyed these tips and that they help you with your Azure Journey in future posts I will be diving deeper into different subjects explored here and other topics in AI and Machine Learning.
If you have any questions, comments, or topics you would like me to discuss feel free to follow me on Twitter if there is a milestone you feel I missed please let me know.
Next Steps
If AI/ML interests you check out these amazing open source best practice repos as well.
About the Author
Aaron (Ari) Bornstein is an avid AI enthusiast with a passion for history, engaging with new technologies and computational medicine. As an Open Source Engineer at Microsoft’s Cloud Developer Advocacy team, he collaborates with Israeli Hi-Tech Community, to solve real world problems with game changing technologies that are then documented, open sourced, and shared with the rest of the world.

Top comments (0)