AzureFunBytes has been dedicated to providing you with details on how to skill up and prepare for the AZ-900 Azure Fundamentals Certification. The skills measured guide provides you with all the important things you should know before taking the exam. One of big sections of the test that's worth about 15-20% of your score is around cloud concepts. Today we'll talk about Single Points of Failure and Fault Tolerance in the context of Microsoft Azure.
In 2002 I took on my first real production systems job. These early times provided some huge challenges in creating reliability in complex systems. The overhead associated with building a datacenter deployed application required a ton of work for both the administrators and the customer who leased the servers. But at the time, there was no real virtualization software available to provide a quicker to production infrastructure solution.
Single points of failure became a regular thing I came across from my customers at the time. SPOFs were so common simply due to the fact that many of these customers had limited resources to improve their fault tolerance. Many of our limitations were simply geographic and hardware related. Before the cloud, expanding your reliability required ensuring physical hardware was purchased, installed, and eventually configured as part of a set across multiple data centers. This was costly and time consuming for companies.
Years later, cloud vendors like Azure heard the pain of people like myself who wanted multiple versions of the same server configuration across a number of fault domains. Being able to have a highly distributed infrastructure is one of the principles of cloud computing and the greatest advantage to engineers and developers. The simplest way to implement this to ensure your applications are highly available is to ensure the proper fault tolerance and avoid single points of failure.
Cloud Core Concepts
Let's define both of these terms first (both from Wikipedia) :
A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working.[1] SPOFs are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.
Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of (or one or more faults within) some of its components. If its operating quality decreases at all, the decrease is proportional to the severity of the failure, as compared to a naively designed system, in which even a small failure can cause total breakdown. Fault tolerance is particularly sought after in high-availability or life-critical systems. The ability of maintaining functionality when portions of a system break down is referred to as graceful degradation.
Example Web App Architecture
Let's use a common example of a simple SPOF that can occur and reduce the reliability of a website. In this situation, we'll use a simple CMS, like WordPress.
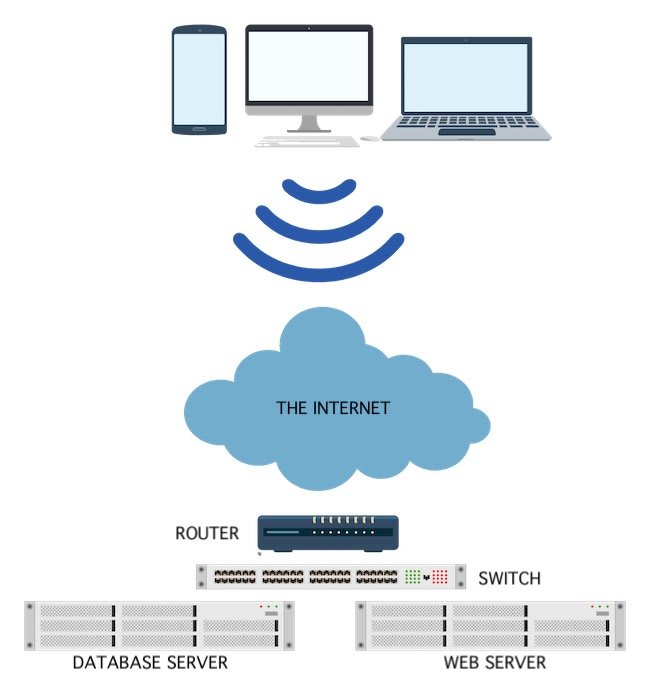
This is a simple diagram that shows a simple web application with a front end web server and a backend database. The problem with this diagram is that almost any part below "The Internet" acts a single point of failure. The assumptions about this solution the diagram say the following:
- We are in a single datacenter - A SPOF, if this data center goes down, we have no fault tolerance. Our application is down.
- We have only one of all of the major pieces of our infrastructure - everything here is a SPOF in the context of a running system. If any single part of the infrastructure fails, it has no redundant pair to ensure that traffic continues to flow in and out of our solution.
- We're bound by what we already one - if we need more hardware, we will need to order it and extend the potential degradation of our solution.
Improving the above model would require duplicating the infrastructure as so:
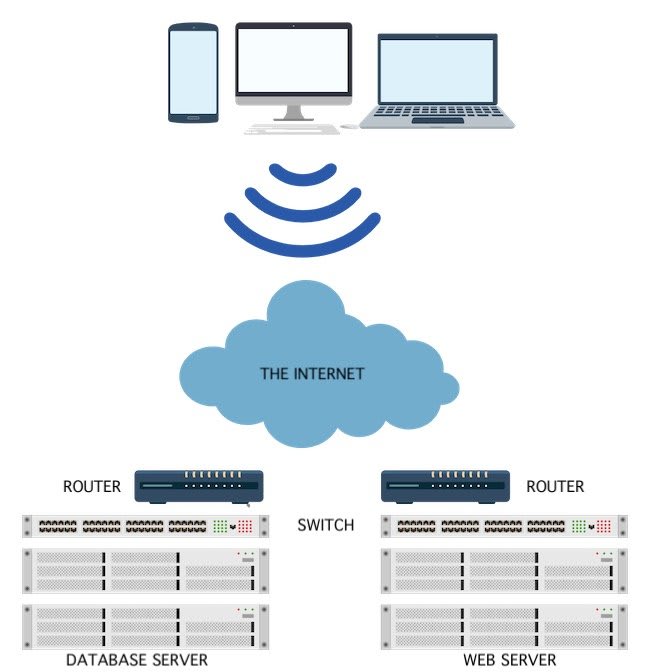
This time we're providing additional redundancy by adding more web and database servers along with ensuring our network has redundant paths via network. But here's the problem, if the datacenter this application lives within goes down with no additional fault tolerance in another datacenter, our redundancy is fairly pointless.
In the cloud, we're able to negate a lot of these problems by utilizing highly available networks and infrastructure managed by your vendor. You then can use software and tools to create the infrastructure you need. This model saves you a ton of time and effort to ensure reliability. You can distribute your applications across multiple datacenter sites to ensure that regardless of what goes down, your site stays up.
Azure Fault Tolerance
Fault tolerance to ensure your applications are reliable can be part of your deployment plan. By making use of all the networks, data centers, and services that Azure provides, you'll achieve this goal.
We can achieve fault tolerance by understanding a few core concepts of how Microsoft Azure is built. Let's look at some of the concepts from the Regions and Availability Zones in Azure documentation for Azure.
To better understand regions and Availability Zones in Azure, it helps to understand key terms or concepts.
| Term or concept | Description |
|---|---|
| region | A set of datacenters deployed within a latency-defined perimeter and connected through a dedicated regional low-latency network. |
| geography | An area of the world containing at least one Azure region. Geographies define a discrete market that preserves data residency and compliance boundaries. Geographies allow customers with specific data-residency and compliance needs to keep their data and applications close. Geographies are fault-tolerant to withstand complete region failure through their connection to our dedicated high-capacity networking infrastructure. |
| Availability Zone | Unique physical locations within a region. Each zone is made up of one or more data centers equipped with independent power, cooling, and networking. |
| recommended region | A region that provides the broadest range of service capabilities and is designed to support Availability Zones now, or in the future. These are designated in the Azure portal as Recommended. |
| alternate (other) region | A region that extends Azure's footprint within a data residency boundary where a recommended region also exists. Alternate regions help to optimize latency and provide a second region for disaster recovery needs. They are not designed to support Availability Zones (although Azure conducts regular assessments of these regions to determine if they should become recommended regions). These are designated in the Azure portal as Other. |
| foundational service | A core Azure service that is available in all regions when the region is generally available. |
| mainstream service | An Azure service that is available in all recommended regions within 12 months of the region/service general availability or demand-driven availability in alternate regions. |
| specialized service | An Azure service that is demand-driven availability across regions backed by customized/specialized hardware. |
| regional service | An Azure service that is deployed regionally and enables the customer to specify the region into which the service will be deployed. For a complete list, see Products available by region. |
| non-regional service | An Azure service for which there is no dependency on a specific Azure region. Non-regional services are deployed to two or more regions and if there is a regional failure, the instance of the service in another region continues servicing customers. For a complete list, see Products available by region. |
Availability Zones
An Availability Zone is a high-availability offering that protects your applications and data from datacenter failures. Availability Zones are unique physical locations within an Azure region. Each zone is made up of one or more data centers equipped with independent power, cooling, and networking. To ensure resiliency, there's a minimum of three separate zones in all enabled regions. The physical separation of Availability Zones within a region protects applications and data from datacenter failures. Zone-redundant services replicate your applications and data across Availability Zones to protect from single-points-of-failure. With Availability Zones, Azure offers industry best 99.99% VM uptime SLA. The full Azure SLA explains the guaranteed availability of Azure as a whole.
An Availability Zone in an Azure region is a combination of a fault domain and an update domain. For example, if you create three or more VMs across three zones in an Azure region, your VMs are effectively distributed across three fault domains and three update domains. The Azure platform recognizes this distribution across update domains to make sure that VMs in different zones are not scheduled to be updated at the same time.
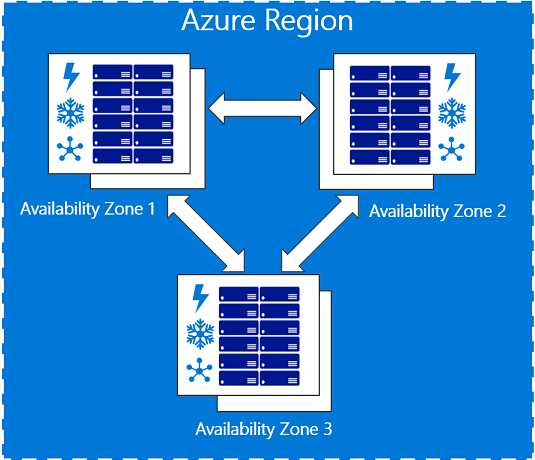
To achieve comprehensive business continuity on Azure, build your application architecture using the combination of Availability Zones with Azure region pairs. You can synchronously replicate your applications and data using Availability Zones within an Azure region for high-availability and asynchronously replicate across Azure regions for disaster recovery protection.
All Azure management services are architected to be resilient from region-level failures. In the spectrum of failures, one or more Availability Zone failures within a region have a smaller failure radius compared to an entire region failure. Azure can recover from a zone-level failure of management services within the region or from another Azure region. Azure performs critical maintenance one zone at a time within a region, to prevent any failures impacting customer resources deployed across Availability Zones within a region.
Spreading your application infrastructure across multiple availability zones will help you achieve that fault tolerance you're looking for. In the case of our CMS, this example from the Highly scalable and secure WordPress website documentation shows you an example of how using multiple AZs and regions can provide you with a highly available site.
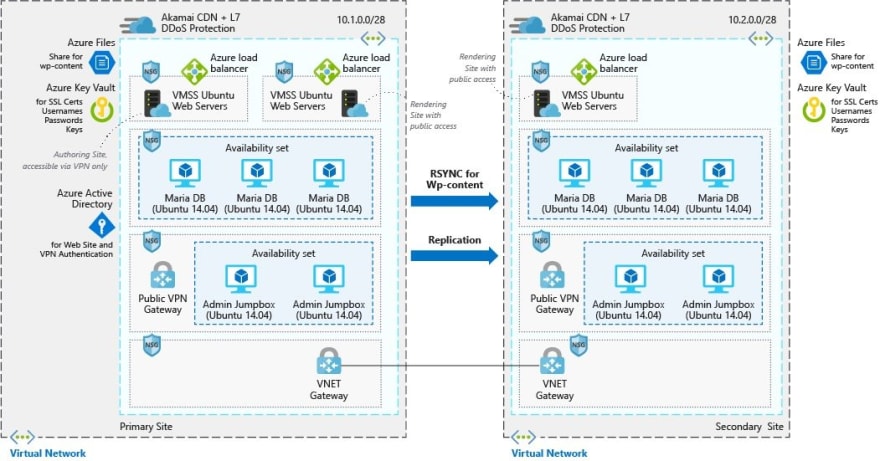
Here we see a number of redundant services working in parallel along with fault tolerance built-in. The web servers have load balancers which front end a multi-AZ distributed origin for our web app, the databases are set in availability sets in different AZs ensuring if one fails it will fall over to the next. If our primary region fails, we've also got replication and a completely redundant version of our infrastructure in a different region. That means even if an entire portion of the infrastructure on one part of the earth fails, we'll still have another set ready to continue.
Learning More
Want to learn even more on these subjects? We've got so much content for you! Check out these links for more details on creating highly available websites.
Microsoft Learn: Azure Fundamentals
Microsoft Learn: Cloud Concepts - Principles of cloud computing
12 Free Months and $200 for Azure
Exam AZ-900: Microsoft Azure Fundamentals
AzureFunBytes! - Byte-sized content with a live Twitch show! Learn about
Azure fundamentals with me!
Live stream is available on Twitch at 2pm EDT weekly. You can also find the recordings there as well.
https://twitch.tv/azurefunbytes
https://twitter.com/azurefunbytes

Top comments (0)