
TL;DR This post outlines how distribute PyTorch Lightning training on Distributed Clusters with Azure ML
If you are new to Azure you can get started a free subscription using the link below.
Create your Azure free account today | Microsoft Azure
Azure ML and PyTorch Lighting

In my last few posts on the subject, I outlined the benefits of both PyTorch Lightning and Azure ML to simplify training deep learning models and logging. Take a look you haven’t yet check it out!
- Training Your First Distributed PyTorch Lightning Model with Azure ML
- Configuring Native Azure ML Logging with PyTorch Lighting
Now that you are familiar with both the benefits of Azure ML and PyTorch lighting let’s talk about how to take PyTorch Lighting to the next level with multi node distributed model training.
Multi Node Distributed Training
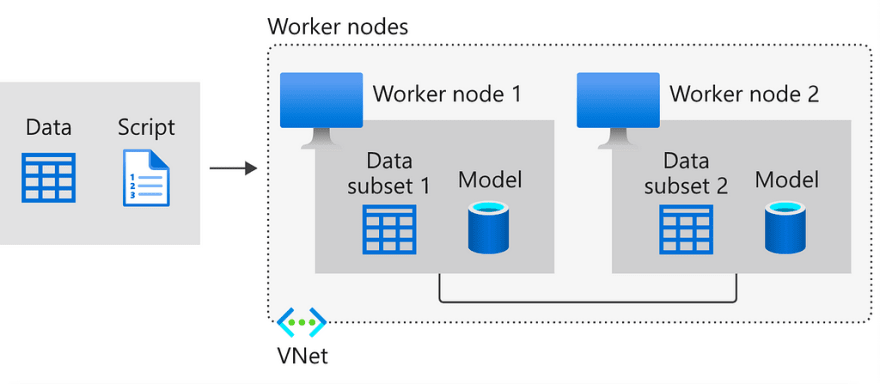
Multi Node Distributed Training is typically the most advanced use case of the Azure Machine Learning service. If you want a sense of why it is traditionally so difficult, take a look at the Azure Docs.
What is distributed training? - Azure Machine Learning
PyTorch Lighting makes distributed training significantly easier by managing all the distributed data batching, hooks, gradient updates and process ranks for us. Take a look at the video by William Falcon here to see how this works.
We only need to make one minor modification to our train script for Azure ML to enable PyTorch lighting to do all the heavy lifting in the following section I will walk through the steps to needed to run a distributed training job on a low priority compute cluster enabling faster training at an order of magnitude cost savings.
Plan and manage costs - Azure Machine Learning
Getting Started
Step 1 — Set up Azure ML Workspace

Create Azure ML Workspace from the Portal or use the Azure CLI
Connect to the workspace with the Azure ML SDK as follows
from azureml.core import Workspace
ws = Workspace.get(name="myworkspace", subscription_id='<azure-subscription-id>', resource_group='myresourcegroup')
Step 2 — Set up Multi GPU Cluster
Create compute clusters - Azure Machine Learning
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your GPU cluster
gpu_cluster_name = "gpu cluster"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='Standard_NC12s_v3',
max_nodes=2)
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Step 3 — Configure Environment
To run PyTorch Lighting code on our cluster we need to configure our dependencies we can do that with simple yml file.
channels:
- conda-forge
dependencies:
- python=3.6
- pip:
- azureml-defaults
- mlflow
- azureml-mlflow
- torch
- torchvision
- pytorch-lightning
- cmake
- horovod # optional if you want to use a horovod backend
We can then use the AzureML SDK to create an environment from our dependencies file and configure it to run on any Docker base image we want.
**from** **azureml.core** **import** Environment
env = Environment.from_conda_specification(environment_name, environment_file)
_# specify a GPU base image_
env.docker.enabled = **True**
env.docker.base_image = (
"mcr.microsoft.com/azureml/openmpi3.1.2-cuda10.2-cudnn8-ubuntu18.04"
)
Step 4 — Training Script
Create a ScriptRunConfig to specify the training script & arguments, environment, and cluster to run on.
We can use any example train script from the PyTorch Lighting examples or our own experiments.
Once we have our training script we need to make one minor modification by adding the following function that sets all the required environmental variables for distributed communication between the Azure nodes.
https://medium.com/media/290fec1591cf1a84f074aa91af8a010b/href
Then after parsing the input arguments call the above function.
args = parser.parse_args()
# -----------
# configure distributed environment
# -----------
set_environment_variables_for_nccl_backend(single_node=int(args.num_nodes) > 1)
Hopefully in the future this step will be abstracted out for us.
Step 5 — Run Experiment
For Multi Node GPU training , specify the number of GPUs to train on per a node (typically this will correspond to the number of GPUs in your cluster’s SKU), the number of nodes(typically this will correspond to the number of nodes in your cluster) and the accelerator mode and the distributed mode, in this case DistributedDataParallel ("ddp"), which PyTorch Lightning expects as arguments --gpus --num_nodesand --accelerator, respectively. See their Multi-GPU training documentation for more information.
Then set the distributed_job_config to a new MpiConfiguration with equal to one(since PyTorch lighting manages all the distributed training)and a node_count equal to the --num_nodes you provided as input to the train script.
https://medium.com/media/9f896be17f677c2dd2a3681360c2db83/href
We can view the run logs and details in realtime with the following SDK commands.
**from** **azureml.widgets** **import** RunDetails
RunDetails(run).show()
run.wait_for_completion(show_output= **True** )
And there you have it with out needing to deal with managing the complexity of distributed batching, Cuda, MPI, logging callbacks, or process ranks, PyTorch lighting scale your training job to as many nodes as nodes as you’d like.
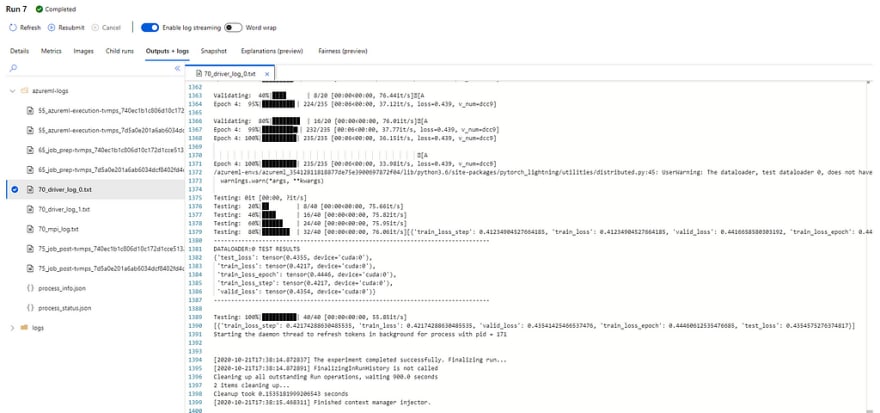
You shouldn’t but if you have any issues let me know in the comments.
Acknowledgements
I want to give a major shout out to Minna Xiao and Alex Deng from the Azure ML team for their support and commitment working towards a better developer experience with Open Source Frameworks such as PyTorch Lighting on Azure.
About the Author
Aaron (Ari) Bornstein is an AI researcher with a passion for history, engaging with new technologies and computational medicine. As an Open Source Engineer at Microsoft’s Cloud Developer Advocacy team, he collaborates with the Israeli Hi-Tech Community, to solve real world problems with game changing technologies that are then documented, open sourced, and shared with the rest of the world.

Top comments (0)