
TLDR; This post will walk through how to train and evaluate Azure ML AutoML Regression model on your data using Azure Synapse Analytics Spark and SQL pools.
Before we get started let’s make sure we are all on the same page with the core Azure concepts needed to take your data to the next level.
If you are new to Azure you can get started a free subscription using the link below.
Create your Azure free account today | Microsoft Azure
What is Azure Synapse Analytics?
Azure Synapse Analytics is an integrated service that accelerates extracting insightful across data warehouses and big data systems.

Azure Synapse ties together traditional relational SQL enterprise data warehousing, unstructured data stores and serverless Apache Spark , to enable limitless pipelines for ETL and ELT operations. Furthermore Synapse Studio provides a unified interface for data monitoring, coding, and security.

What is Azure Machine Learning Auto ML?

Azure Machine Learning (Azure ML) is a cloud-based service for creating and managing machine learning solutions. It’s designed to help data scientists and machine learning engineers to leverage their existing data processing and model development skills & frameworks.

In Azure Machine Learning, Auto ML allows data scientists, analysts, and developers to build ML models with high scale, efficiency, and productivity all while sustaining model quality.
With Auto ML we can transform Synapse Analytics Data into actionable baseline models to enrich datasets at scale without writing a single line of machine learning code.
Regression is used to build models to forecast numeric values such as taxi fares based on learned input features.
In the next section, I will walk you through an end to end example of how to enrich you Synapse data by training and evaluating a model with the NYC Taxi Dataset. Once you get preform these steps you’ll be able to train and run your own Auto ML on models on any tabular dataset of your choosing.
Getting Started

Step 1: Set Up Azure Machine Learning and Synapse Workspaces
First if you do not have them already we need to create our Azure ML and Synapse workspaces.

Step 2: Link Azure Machine Learning Workspace to Synapse Service
Once we have deployed our two workspaces we need to link them. Full steps for linking Azure ML and Synapse Workspaces can be found here
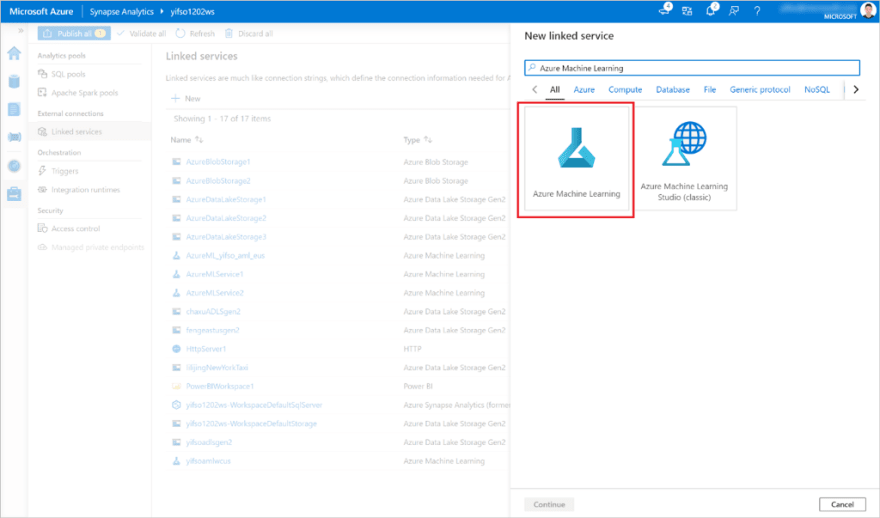
Step 3: Create Dedicated Serverless Apache Spark Spark and SQL Pools
To actually ingest and process our data we need to use pools. Azure Synapse Analytics offers various analytics engines to help you ingest, transform, model, analyze, and serve your data.
For this tutorial since we are using a toy dataset we can use the cheapest pools available for you own data you may want to configure your pools accordingly.
The serverless Apache Spark pools offers open-source big data compute capabilities. This is where the majority of our data processing and Auto ML code will run.

A dedicated serverless SQL pool offers T-SQL based compute and storage capabilities. We will use this pool to store the data we want to enhance with our AutoML model.
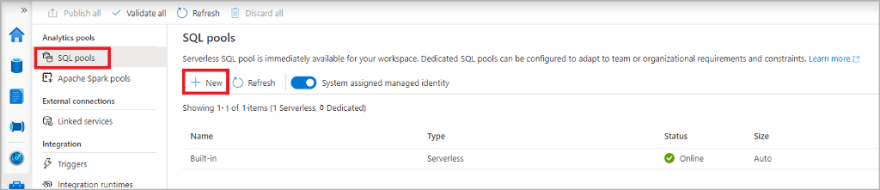
One key advantage of Azure Synapse Analytics is if you configure a time out you only pay for the compute when it’s in use.
Step 4: Upload and run the Spark Taxi Data Notebook to create Spark Database and SQL Test Database
Once we have our serverless Spark and SQL pools up and running we can now ingest our data setup our Spark and SQL tables for training and testing respectively.
Download this Spark Create-Spark-Table-NYCTaxi- Data.ipynb notebook and import it into your workspace.


Once the notebook is uploaded, change the sql_pool_name value to match the name of your sql pool and then select the desired spark pool and run click all.
Step 5: Launch Auto ML Wizard and Train Regression Model with AutoML using NYC Taxi Spark Table.
Once the data is ingested we can use our spark nyc_taxi and Spark Pool to train an AutoML regression model for forecasting taxi fares.

Follow the three steps in wizard below to train your model.

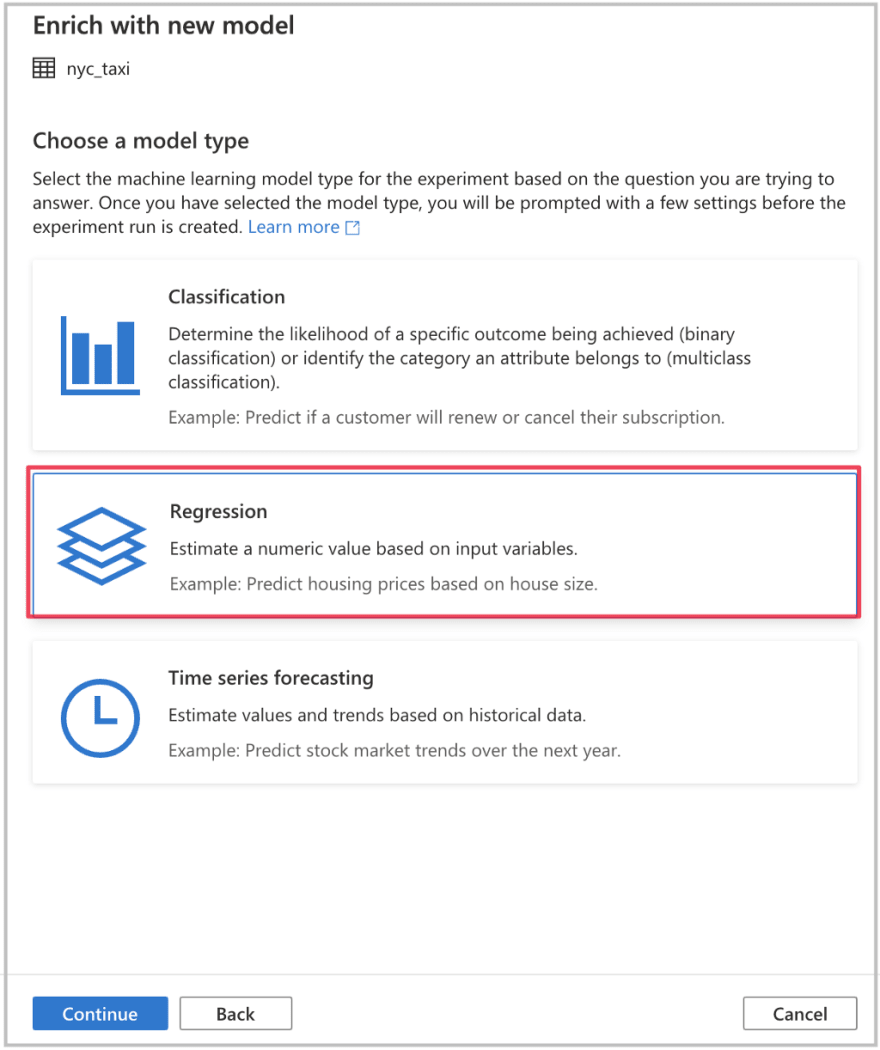
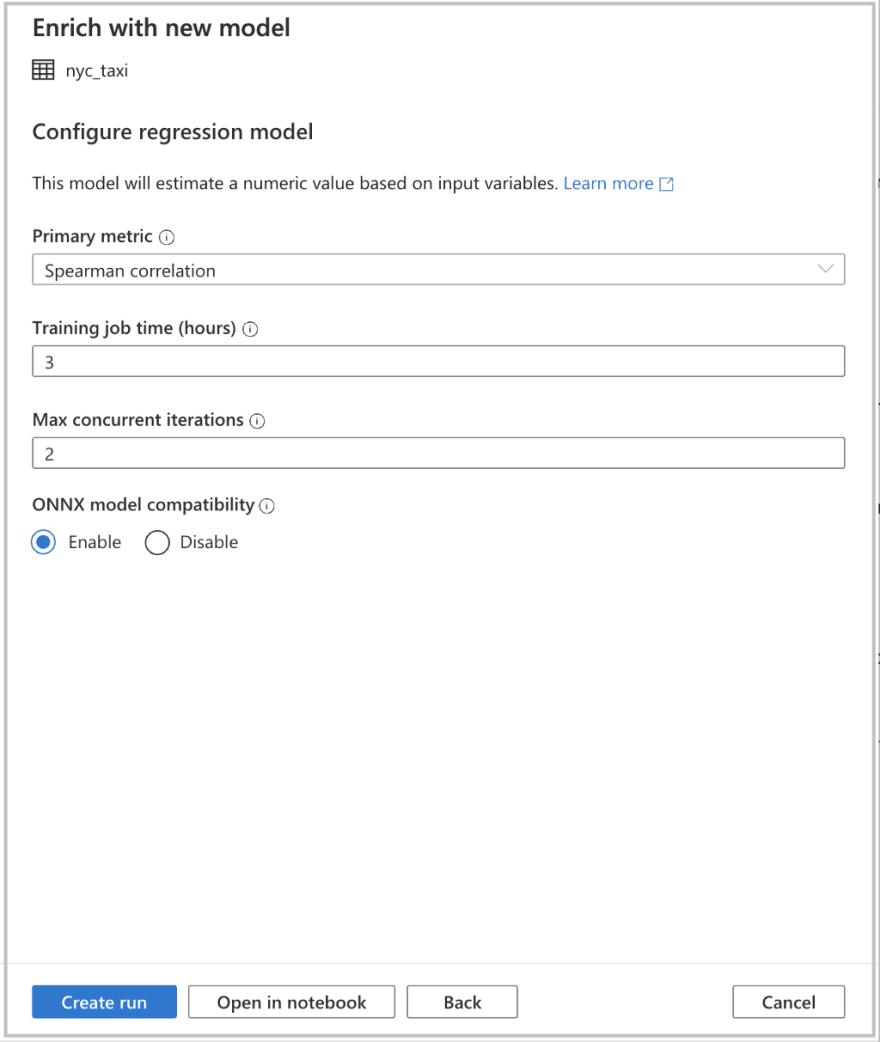
This will kick off your Auto ML Regression training job. It should take about 2hrs to run when it is complete we can then evaluate it on our SQL test table.

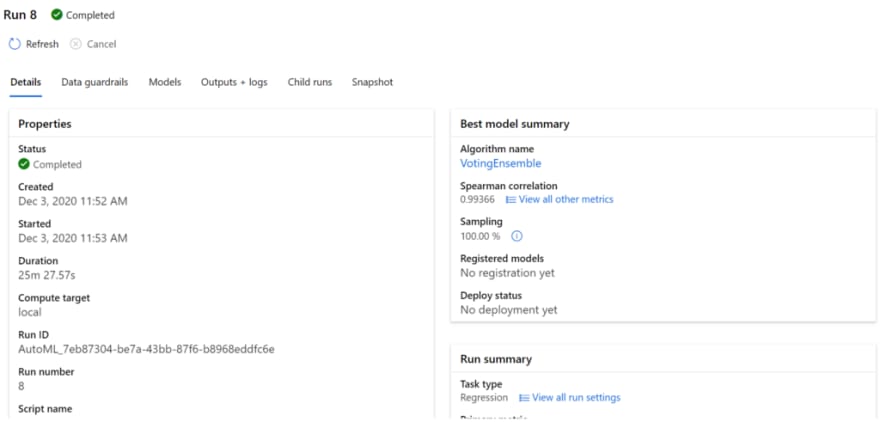
Step 6: Enhance SQL Table with Trained Auto ML Model
Once we have the best model we can now evaluate it on our test SQL table using our SQL Pool.
First we need to select the table we want to enhance with the model we just trained.

Then we select our new Auto ML model, map the our input table columns to what the model is expecting and choose or create a table for storing our model locally.
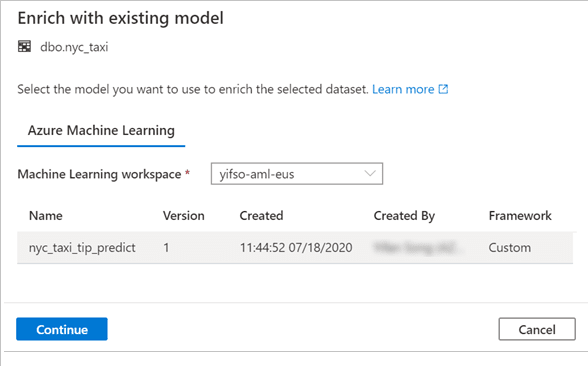
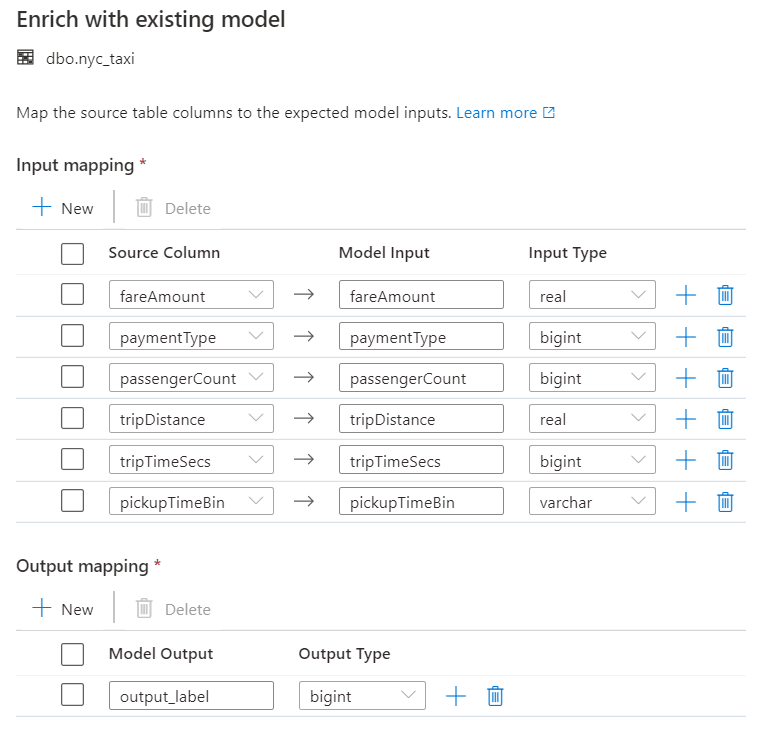

The wizard will generate a T-SQL script that evaluate our model against the test data and outputs the fare predictions.

There you have it all you need to know to train and test you own AutoML models and make them actionable.
Next Steps

Additional Synapse Documentation and Walkthroughs worth checking out can be found below:
- Machine Learning in Azure Synapse Analytics - Azure Synapse Analytics
- Tutorial: Machine learning model training using AutoML - Azure Synapse Analytics
- Tutorial: Machine learning model scoring wizard for dedicated SQL pools - Azure Synapse Analytics
- Tutorial: Sentiment analysis with Cognitive Services - Azure Synapse Analytics
- Unleash the power of predictive analytics in Azure Synapse with machine learning and AI
Now that you’ve finished the steps above it is time to try them out on you own synapse data. Feel free to post in the comments if you have any questions and to share the cool models you make!
Look forward to seeing what AutoML and Azure Synapse can do for you!!
Acknowledgments
Thanks to Nellie Gustafsson, Yifan Song and Chang Xu from the Azure Synapse product team for their great documentation and support during the writing this post.
About the Author
Aaron (Ari) Bornstein is an AI researcher with a passion for history, engaging with new technologies and computational medicine. As an Open Source Engineer at Microsoft’s Cloud Developer Advocacy team, he collaborates with the Israeli Hi-Tech Community, to solve real world problems with game changing technologies that are then documented, open sourced, and shared with the rest of the world.

Top comments (0)