I'm interested to know whether, how, and to what extent LLMs (could, if suitably designed) exhibit genuine intelligence, but to figure that out, I need to know how they work. To that end I've been watching "The spelled-out intro to language modeling: building makemore" in Andrej Karpathy's YouTube playlist "Neural Networks: Zero to Hero." Between the timestamps 44:23 and 47:20, Andrej encourages his viewers to sleuth out the answer to the following question (note: I'm paraphrasing and simplifying, abstracting away some of the particulars of Andrej's code). Let tensor be a PyTorch tensor—an instance of the class torch.Tensor, representing
Suppose tensor has dimensions 27x27. Why can't we assume the return value of tensor.sum(1) is identical to that of tensor.sum(1, keepdim=True), and thus that tensor / tensor.sum(1) and tensor / tensor.sum(1, keepdim=True) both evaluate to the same thing?
After all, according to PyTorch's broadcasting semantics, tensor and tensor.sum(1, keepdim=True) are broadcastable, and tensor and tensor.sum(1) are as well. So tensor can be divided by either tensor.sum(1, keepdim=True) or tensor.sum(1). And as long as these two division operations are legal, it's not immediately obvious how they can yield different results. The variable tensor holds the same value in both division operations. And each of the alternate divisors is a tensor containing the sum of each "row" of tensor in dimension 1. Given all these commonalities, what difference could the value of keepdim make?
I know I've just presupposed a fair amount of knowledge. You may follow the preceding paragraph better if you watch Andrej's video first. We'll also unpack what I just said in a future post. But before I even attempt to answer Andrej's question, I have some catching up to do, learning how to read both Python code and the documentation for Python libraries like PyTorch.
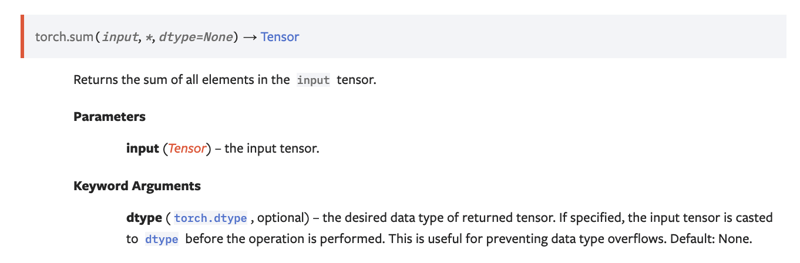
Let's take a look at the documentation for torch.sum:

I'm not accustomed to Python, only C++, JavaScript, and to an extent Java. So when I tried to make sense of the relation between torch.sum, whose signature is in the image, and tensor.sum, my thought process went roughly as follows.
With both tensor and an integer n at our disposal, we can invoke a function sum in either of two ways: torch.sum(tensor, n) or tensor.sum(n). Both invocations do exactly the same thing, so far as I can tell. So either sum is the same function in both cases, or two functions with the same name have extremely similar implementations. I'll go with the former hypothesis, because it's simpler. Thus, torch and tensor share a function named sum accessible via the dot operator, .. Most likely, then, torch.Tensor and its instances, including tensor, inherit sum from torch. Now, methods can only be inherited from types, not from individual objects. So torch must be a type. It's beyond me what kind of type it is. I have heard torch described as a module. That constitutes some reason to doubt it's a class or interface. But for all I know modules are, or can be, classes or interfaces. That's how unfamiliar I am with Python lingo like "module." At all events it would seem that sum is a static method of torch, since you can call it on torch itself, not just an instance of the type torch. And since this method has a body in torch, I suspect torch is not an interface.
Again, that last paragraph is just what I thought initially, when I was a bit less Python literate. Unfortunately, my reasoning there led me astray. torch.sum(input,dim,keepdim=False,*,dtype=None) is not a static method's signature. In fact, it's not a method signature at all, since sum is not a method of torch. Why it's not a method of torch takes a little explaining.
By definition, a function
is a method of
if and only if (i)
is an attribute belonging to some type
and (ii)
is or instantiates
As it happens, the function sum is an attribute of a type, namely torch.Tensor. So, by our definition, sum is a method of torch.Tensor and of any instance thereof. But it's not a method of torch. For sum to be a method of torch, torch would have to either be or instantiate a type of which sum is an attribute. Being a module—which, much like a Java package, is a namespace—torch is not a type, much less the kind of type that has attributes (i.e., a class/struct or interface). So the only way sum can be a method of torch is if torch instantiates (is an instance of) a type of which sum is an attribute. Now, torch does instantiate types, namely the superclasses of the types.ModuleType class: object and ModuleType itself. But sum is not an attribute of ModuleType or object.
Therefore, while sum is an attribute of torch and a method of torch.Tensor and its instances, it's not a method of torch, let alone specifically a static method of torch.
Modules such as torch, it turns out, are objects in Python, seeing as they are instances of the ModuleType class. Virtually everything in Python is an object, including classes and instances of types like int and bool that you might expect to be primitive, as are the corresponding types in other languages. That torch is an object explains how it can have attributes despite being a module rather than a class or interface. (Interfaces technically don't exist at all in Python. Had I known this, I could've immediately and decisively ruled out that torch is an interface, rather than tentatively ruling that out based on torch's having a callable function.)
How then do torch and torch.Tensor have the attribute sum in common? It can't be that Tensor inherits the function sum from torch. Nor can torch and Tensor inherit sum from some type other than Tensor. This is because only types, not modules, can stand in a relation of inheritance.
I take it what happens is that Tensor derives sum from torch, but through a different mechanism than inheritance. The function sum is originally defined in the module torch, and subsequently sum is associated with the class Tensor. There are two places sum can be so associated with Tensor: inside and outside the definition of Tensor. Here's how it would look inside the class definition:
def sum(input, dim, keepdim=False, *, dtype=None):
# Insert body
class Tensor:
def sum(self, dim, keepdim=False, *, dtype=None):
return sum(self, dim, keepdim, dtype)
# Insert rest of class definition
And outside the class definition:
def sum(input, dim, keepdim=False, *, dtype=None):
# Insert body
class Tensor:
# Insert class definition
Tensor.sum = sum
(Note: we're to imagine one of the above code snippets is in some file in the torch module/package directory.) Either way, this is not true inheritance. It's reusing the torch module's implementation of sum to implement Tensor.sum, either via invocation of torch.sum in the definition of Tensor.sum, or via monkey patching (assigning torch.sum to Tensor.sum, after Tensor is defined). We shall see in due course which of these two approaches PyTorch's developers must've taken, assuming there's no third approach I've overlooked.
Let's glance once more at the function signature from the docs: torch.sum(input,dim,keepdim=False,*,dtype=None). There are four parameters, which are input, dim, keepdim, and dtype, in that order. (* is not a parameter but merely an indicator that the parameters after it must receive keyword arguments: arguments of the form parameter_name=value.) The attribute sum of tensor should have these four parameters as well, since Tensor.sum and torch.sum are essentially the same function. Granted, there's a good chance tensor.sum comes by its first parameter in a different way than torch.sum does. For torch.sum is defined at the module level, whereas tensor.sum is plausibly defined at the class level (as illustrated in the first code block above). Suppose that's how tensor.sum is defined. Suppose further that it's a non-static method. Then its first parameter is the class instance on which the function is called. That's just how non-static methods work in Python. So the first argument comes from the left of the dot operator, not the beginning of the list of arguments enclosed in parentheses. Even so, the first parameter is intended to receive a tensor, as is the first parameter of torch.sum. Furthermore, I think we can safely assume the remaining parameters are indistinguishable from the last three parameters of torch.sum.
Now, which parameters receive which arguments in the function calls tensor.sum(1) and tensor.sum(1, keepdim=True)? Recall that we are countenancing two mutually exclusive scenarios: (a) that, as a result of monkey patching, tensor.sum and torch.sum have the very same parameters, and (b) that, due to tensor.sum's being defined in a class, tensor.sum and torch.sum differ with respect to the source of the first argument. We can rule out (a) on the following grounds. The first argument enclosed in parentheses is 1 in both tensor.sum(1) and tensor.sum(1, keepdim=True). So given (a) and the fact that 1 is passed as a positional argument, 1 is the first argument, period. Rather than being passed for dim, it's passed for input. But like input and unlike keepdim and dtype, dim lacks a default value. So dim does not get assigned a value at all. Surely, if that were the case, tensor.sum(1) and tensor.sum(1, keepdim=True) would cause at least one TypeError. The first error Python would most likely raise is something like:
TypeError: sum(): argument 'input' (position 1) must be Tensor, not int
But failing that, Python would undoubtedly raise this error:
TypeError: sum() missing 1 required positional argument: "dim"
Since neither of these two errors is in fact raised, we've shown that (a) is not the case. Unless I have overlooked some third scenario, (c), that leaves only one possibility as to the relation between the parameters of tensor.sum and those of torch.sum: (b). That is, the first argument of tensor.sum, which function is defined in a class, must be whatever's to the left of the dot operator (unlike the first argument of torch.sum, which is the first item in the list enclosed in parentheses in the function call). That's tensor in the invocations tensor.sum(1) and tensor.sum(1, keepdim=True).
I may be getting ahead of myself. There's one complication I haven't yet discussed, which might block our inference that (b) is the case. That complication is, torch.sum is overloaded, so it has an alternative parameter list:
Only one of this overload's parameters, namely input, lacks a default value. So one need only pass one argument explicitly to avoid a missing argument error.
Let's stipulate that suggestion (a) is true, and thus Tensor has been monkey patched to have an attribute identical to torch.sum. It follows that tensor.sum has the very same overloads torch.sum has. So even if only one argument were passed between the parens, there would be no error, as long as that argument were of the right type. But therein lies the rub. The first argument the overload torch.sum(input, *, dtype=None) expects is a tensor. So tensor.sum(1) still raises one of the errors mentioned before:
TypeError: sum(): argument 'input' (position 1) must be Tensor, not int
But, contrary to my previous hasty prediction, the missing argument error is not raised. Moreover, Python interprets tensor.sum(1, keepdim=True) as an invocation of the overload with the larger parameter list, since only that overload has a parameter named keepdim. So, when tensor.sum(1, keepdim=True) is executed, we should expect Python to raise both of the errors I predicted earlier.
Again, this is all on the supposition that (a) is true. Since these error messages are not actually raised, we may infer that (a) is false. Thus, our original conclusion stands: (b) is true. It follows that tensor is passed for input in tensor.sum(1) and tensor.sum(1, keepdim=True).
At this point we can straightforwardly ascertain the values dim, keepdim, and dtype receive. If we take the positional/non-keyword arguments in the invocation tensor.sum(1), and pass them to torch.sum as keyword arguments, we get torch.sum(input=tensor, dim=1, keepdim=False, dtype=None). These two invocations are equivalent. Also equivalent (to each other) are the invocations
tensor.sum(1, keepdim=True)
and
torch.sum(input=tensor, dim=1, keepdim=True, dtype=None).
Thus, given how Tensor.sum is defined in terms of torch.sum,
tensor.sum(1)
and
tensor.sum(dim=1, keepdim=False, dtype=None)
are equivalent, and so are
tensor.sum(1, keepdim=True)
and
tensor.sum(dim=1, keepdim=True, dtype=None).
In my next post in this series, I promise to do what I had set out to do in the first place: answer Andrej Karpathy's question.

Top comments (0)