
The Twelve-Factor App
Before you even start to read this article I recommend you to check out the concept of The Twelve-Factor App [https://12factor.net/]. The Twelve-Factor App is a methodology for building an ideal software-as-a-service app by following 12 simple rules. The important thing here to remember is that it doesn't matter what kind of architecture you use as long as you follow those rules.
A little bit about monolithic architecture
A design philosophy behind the monolithic architecture is that the application is responsible not just for a particular task, but can perform every step needed to complete a particular function.
In software engineering, a monolithic application describes a software application which is designed without modularity. Modularity is desirable, in general, as it supports reuse of parts of the application logic and also facilitates maintenance by allowing repair or replacement of parts of the application without requiring wholesale replacement.
Cons:
- Small fixes go through the same deployment process as any other feature releases which can be time and money consuming for big systems
- Release process can be money and time consuming for bigger systems
- Every release needs to be tested as a whole system to decrease the possibility of a new bug
- Scalability
- Usually designed without modularity
Pros:
- Usually, they don't have a very complex deployment process
- A project usually lives in one system/server which can bring some good things on smaller projects
- Makes the whole system less complex
- In the beginning, it can be a very cheap and quick solution
From Monolithic to Microservices…
At its core, microservices are about decomposing the system into more discrete units of work. In my view, microservice development is about making the architecture at a component level work the way good development practices do with modularization of the code itself.
We can compare decomposing a big monolith architecture into smaller microservices with refactoring a software code. Whenever our class or a software component becomes too big, by following good practices we refactor them into smaller units each solving one particular problem. By creating a micro component granulation, we divide our big problem into a few smaller ones giving us better sustainability and therefore they are easier to test.
So how do we even start on refactoring a huge monolithic architecture?
When decomposing a huge system we have to be very careful not to break something and usually decomposing is done one small step at the time.
Usually, the main problems when decomposing a huge monolithic architecture are:
- Stale code
- Lack of unit tests
- Violation of the Single Responsibility Principle
- Inability to scale individual components to meet increased demand
- Technical debt accumulated over time
Refactoring the whole monolithic system from scratch would probably be a waste of time and money and would have a good amount of risk associated with it. Also while refactoring the whole system we would not even be able to start using it until it is completely finished.
The Strangler Pattern
So the first thing is to group the monolithic app by important functionalities, pick one and create a separate service in complete isolation. Once the new service is ready, the old functionality is strangled, and the new one is put into use.
The new service gets its own CI/CD pipeline, and now a team responsible for this service can be completely autonomous and independent.
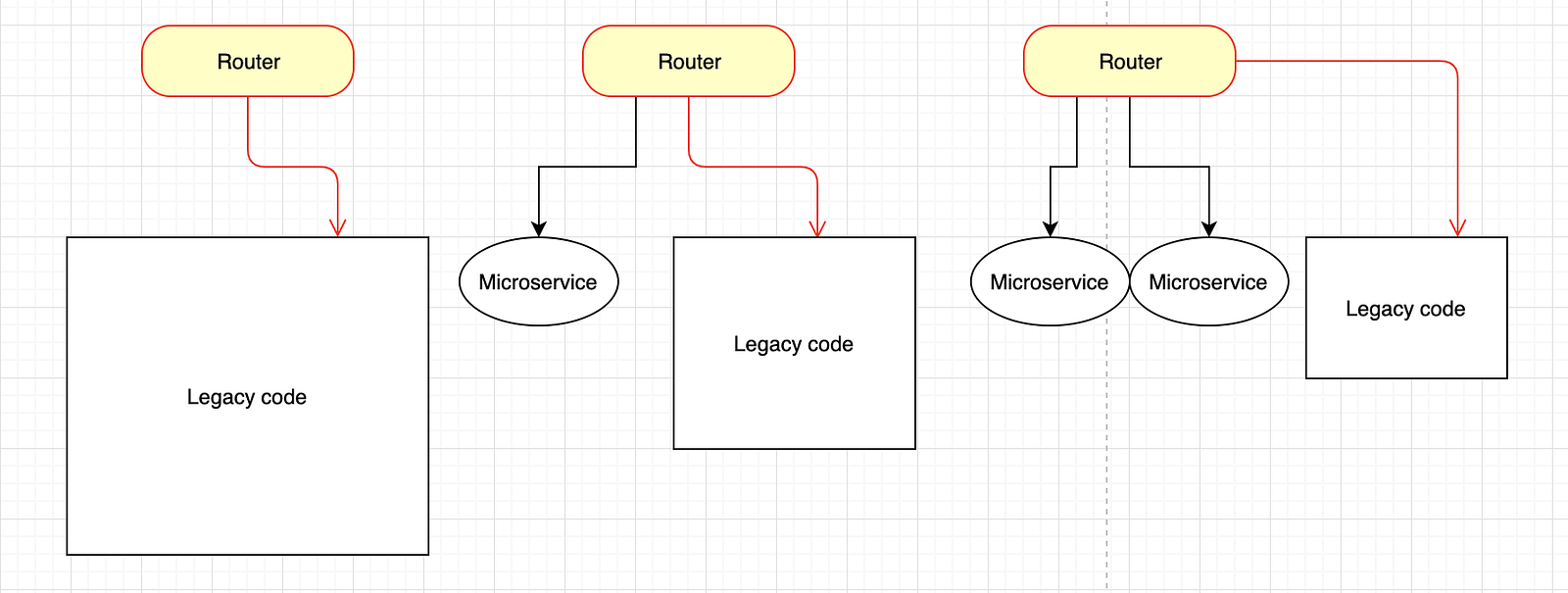
So what happens when we have a lot of Microservices in our architecture?
There are few things companies have to be aware of when building a Microservice architecture:
- Using Container Orchestration Engines
- Scalability
- Latency and Resilience
- Continuous delivery
- Logging and Tracing
- There are always some tradeoffs
What is a Container Orchestration Engine?
The main difference between Monolithic and Microservice architecture is in the number of services we have to monitor. It would be impossible to manually check each microservices health, availability, memory usage and scale, restart or revert them.
No worries, however, we have Container Orchestration Engines for that. Some popular ones are Kubernetes, Docker Swarm and Apache Mesos. They all provide a nice UI with built-in load balancing system.
Scalability?
When you are running a single monolithic application from a single server, you can handle an increase in demand by allocating more resources to the application. Alternatively, if the increase in demand is the result of more individual users making use of an application, you can begin running new instances of it and spread the load more evenly.
With microservices, on the other hand, upscaling can involve handling a number of different components and services. This means that either all the components need to upscale at the same time, or you need a means of identifying which individual components to upscale, and a method of ensuring that they can still integrate with the rest of the system.
Latency?
Every service invocation in a microservices architecture is over remote network call. As such, there is connection setup, tear down, and wire latency on every single call.
This latency is relatively insignificant for a single call, but as the code path becomes more and more complex, that single call can become many. In addition to the latency increases of the calls themselves, as the traffic increases and services come under more load, the risk of latency in response time increases. In a system based on remote invocation of all service calls, any latency added to the normal flow can be detrimental to the system as a whole.
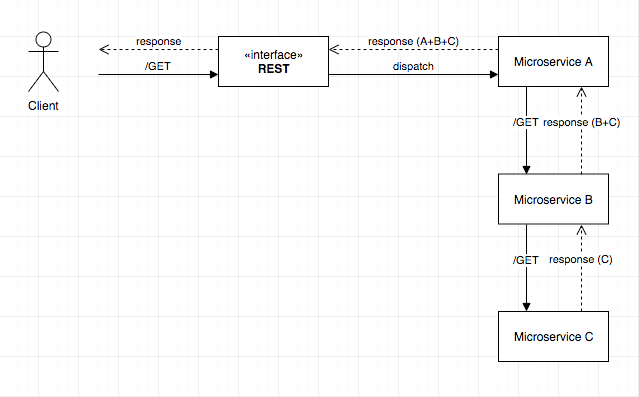
Usually, a good practice is avoiding having microservice calls on every request by caching them if it is possible.
Resilience?
Key principles of Resiliency are (taken from Netflix blog):
- A failure in a service dependency should not break the user experience for members
- The API should automatically take corrective action when one of its service dependencies fails
- The API should be able to show us what's happening right now, in addition to what was happening 15–30 minutes ago, yesterday, last week, etc.
Netflix created Hystrix(https://github.com/Netflix/Hystrix), a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
Netflix uses Hystrix with its search engine. If a search engine is down, for instance, the platform should still be able to allow users to view movies.
Continuous delivery?
Like in every system, the whole process from building, running tests to deploying to stage and production environments should ideally be automated.
Some of the CI/CD tools are Bamboo, GoCD, Jenkins, Travis CI, CircleCI, CodeShip, TeamCity…
When deploying a new version we tend to have "0 system downtime". Using container orchestration engines can make this look really easy.
Debugging? Logging and tracing!
What happens when something goes wrong? We have a lot of microservices in our architecture, how to debug this?
One of the hardest operational problems to solve in Microservice architecture is finding the exact microservice where the bug appeared and the reason why. It can become very difficult when you have more and more moving parts, especially when you consider that you can easily scale your containers and have multiple instances of the same microservice.
Having a unified logging process and a clear plan early in your development process can simplify this problem.
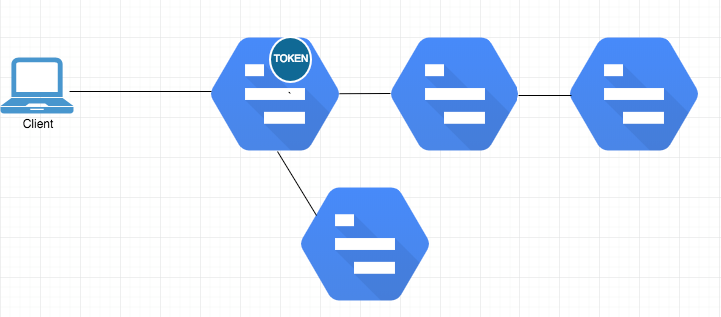
Logging can be really powerful in a distributed environment. It can help us determine the actual flow, not only through your service but through the system as a whole. Determining the actual flow is called Tracing. Tracing is based on the concept of creating a unique token, called a trace, and using that trace in all internal logging events for that call stack.
By embedding this value in all of the logging and timing output for all of the services involved. Each service uses the trace, and then passes it downstream to all of the service calls it makes. Each of those, in turn, do the same. There are several different strategies for moving the trace ID from service to service, but the important part is that the trace ID exists in all of the log messages, for all services throughout the system for a given call stack.
A very popular tool stack used for log monitoring and tracing is ELK. It is an acronym for Elasticsearch, Logstash, and Kibana. Elasticsearch is a search and analytics engine, Logstash is a server-side data processing pipeline that digests data from multiple sources and Kibana is a UI tool which lets users visualize data with charts and graphs.
There are always some tradeoffs!
There is no single silver bullet that solves every use case you have, and even within a pattern, there are compromises that need to be made.
- With complexity, there is an increase in overall latency
- The architecture can become very complex
- Early in the process, development can be slow and expensive
- Packaging and deployment can become hard to maintain (automation)
- Complex systems can increase the latency and decrease the overall reliability of the system as a whole (monitoring)
- Understanding the system as a whole
Useful links:
- 12 Factor App
- Hystrix (Latency and fault tolerance library)
- Open Tracing (Vendor-neutral APIs and instrumentation for distributed tracing)
- Strangler Pattern in action
- Kubernetes, Docker Swarm and Apache Mesos (Container Orchestration Engines)]
- Bamboo, GoCD, Jenkins, Travis CI, CircleCI, CodeShip, TeamCity (CI/CD tools)
- ELK (Elasticsearch, Logstash, and Kibana)

Top comments (0)