
No talk about downloading things on BitTorrent. Or the best clients to do so.
Just a deep-dive into the technical side of it.
Anyone can read this article. Requires ZERO knowledge on networking or BitTorrent to read this.
BitTorrent is one of the most common protocols for transferring large files. In February 2013, BitTorrent was responsible for 3.35% of all worldwide bandwidth, more than half of the 6% of total bandwidth dedicated to file sharing.
Let's dive right in.

Table of Contents
- 💭 Who Created BitTorrent?
- 🥊 BitTorrent vs Cient-Server Downloading
- 📑 High Level Overview
- 📁 What's in a Torrent Descriptor File, Anyway?
- 🧀 The Piece Selection Algorithm of BitTorrent
- 🌆 What Are Sub-Pieces and the Piece Selection Algorithm?
- 🌱 Resource Allocation Using Tit-For-Tat
- 🎐 The Choking Algorithm
- 😎 Optimistic Unchoking
- 🤕 Anti-Snubbing
- 🤔 What If We Upload Only?
- 🐝 What Is a Tracker?
- 🧲 Magnet Links - Trackerless Torrents
- 🐍 Distributed Hash Tables
- 📌 Routing Table
- 🤺 Attacks on BitTorrent
💭 Who Created BitTorrent?

Bram Cohen invented the BitTorrent protocol in 2001. Cohen wrote the first client implementation in Python.
Cohen collected free pornography to lure beta testers to use BitTorrent in the summer of 2002.
🥊 BitTorrent vs Cient-Server Downloading

In traditional downloading, the server uploads the file, and the client downloads the file.

For popular files, this isn't very effective.
500 people downloading the same file will put the server under strain. This strain will cap the upload speed, so clients can not download the file fast.
Second, client-server costs a lot of money. The amount we pay increases with how popular a file is.
Third, it’s centralised. Say the system dies, the file no longer exists - no one can download it.
BitTorrent aims to solve these problems.

In a peer-to-peer network, every peer is connected to every other peer in the network.
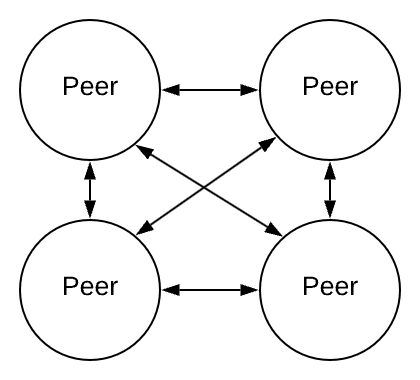
Semi-centralised peer-to-peer networks possess one or more peers with higher authority than most peers.

📑 High Level Overview

BitTorrent is a way to share files. It’s often used for large files. BitTorrent is an alternative to a single source sharing a file, such as a server. BitTorrent can productively work on lower bandwidth.
The first release of the BitTorrent client had no search engine and no peer exchange, users who wanted to upload a file had to create a small torrent descriptor file that they would upload to a torrent index site.
When a user wants to share a file, they seed their file. This user is called a seeder. They upload a torrent descriptor file to an exchange (we’ll talk about this later). Anyone who wants to download that file will download this torrent descriptor.

We call those who download peers. Their torrent client will connect to a tracker (discussed later) and the tracker will send them a list of IP addresses of other seeds and peers in the swarm. The swarm is all PC’s related to a certain torrent.
The torrent descriptor file contains a list of trackers and metadata on the file we’re downloading.

A peer will connect to a seed and download parts of the file.

Once the peer completes a download, they could function as a seed. Although, it is possible to function as a seed while also downloading (and is very common).
Once the seed has shared the file to a peer, that peer will act as a seed. Instead of the client-server model where only 1 server exists to upload the file, in BitTorrent, multiple people can upload the same file.
BitTorrent splits the file up into chunks called pieces, each of a certain size. Sometimes it’s 256KB, sometimes it’s 1MB. As each peer receives a piece, they become a seed of that piece for other peers.
With BitTorrent, we do not have a single source to download from. We could download a few pieces from your home country, then download a few that your home country doesn’t own from a far-away country.
The protocol hashes the pieces to make sure no seed has tampered with the original file. Then stores the hash in the torrent descriptor on the tracker.
This is how BitTorrent works at a very high level. We will now go into detail. We aim to answer these questions:
- What if a peer only downloads and never uploads?
- Who do we download from, or upload to?
- What is a magnet link?
- What is a torrent descriptor?
- What hashing algorithm is used?
- How does BitTorrent selects what pieces to download?
And much more.
📁 What's in a Torrent Descriptor File, Anyway?

It's a dictionary (or hashmap) file.
The file is described as:
- Announce
The URL of the tracker. Remember earlier when we contacted the tracker server to find other peers using the same file? We found that tracker by using the announce key in the torrent descriptor file.
- Info
This maps to a dictionary whose keys depend on whether one or more files are being shared. The keys are:
Files (child of info, is a list)
Files only exists when multiple files are being shared. Files is a list of dictionaries. Each dictionary corresponding to a file.
Each of these dictionaries has 2 keys.
Length - the size of the file in bytes.
Path - A list of strings corresponding to subdirectory names, the last of which is the actual file name.
- Length
The size of the file in bytes (only when one file is being shared)
- Name
Suggested filename. Or the suggested directory name.
- Pieces length
The number of bytes per piece.
The piece's length must be a power of two and at least 16KiB.
This is $$28 \; KiB = 256 \; KiB = 262,144 \; B$$
- Pieces
A hash list.
A list of hashes calculated on various chunks of data. We split the data into pieces. Calculate the hashes for those pieces, store them in a list.
BitTorrent uses SHA-1, which returns a 160-bit hash. Pieces will be a string whose length is a multiple of 20 bytes.
If the torrent contains multiple files, the pieces are formed by concatenating the files in the order they appear in the files directory.
All pieces in the torrent are the full piece length except for the last piece which may be shorter.
Now, I can guess what you’re thinking.
"SHA-1? What is this? The early 2000s?"
And I agree. BitTorrent is moving from SHA-1 to SHA256.
Still confused? Not to worry! I designed this JSON file that describes what a torrent file looks like. Note: I’ve concatenated some things. This makes it easier to read and understand the general layout. I made the numbers up, following the rules of BitTorrent’s torrent descriptor.
{
"Announce": "url of tracker",
"Info": {
"Files": [
{
"Length": 16,
"path": "/folder/to/path"
},
{
"length": 193,
"path": "/another/folder"
}
]
},
"length": 192,
"name":" Ubuntu.iso",
"Pieces length": 262144,
"Pieces": [AAF4C61DDCC5E8A2DABEDE0F3B482CD9AEA9434D, CFEA2496442C091FDDD1BA215D62A69EC34E94D0]
}
🧀 The Piece Selection Algorithm of BitTorrent

One of the largest questions in BitTorrent is “what pieces should I select to download?”
With a traditional client-server model, we download the whole file. But now, we get to pick what pieces to download.
The idea is to download the pieces that no one else has - the rare pieces. By downloading the rare pieces, we make them less rare by uploading them.
🌆 What Are Sub-Pieces and the Piece Selection Algorithm?
BitTorrent uses TCP, a transmission protocol for packets. TCP has a mechanism called slow start.
Slow start is a mechanism which balances the speed of a TCP network connection. It escalates the amount of data transmitted until it finds the network’s maximum carrying capacity. cwdn stands for the Congestion Window.

TCP does this because if we send 16 connections at once, the server may not be used to the traffic and congestion will happen on the network.
If we’re not regularly sending data, TCP may cap our network connection at a slower speed than normal.
BitTorrent makes sure to always send data by breaking pieces down into further sub-pieces.
Each sub-piece is about 16KB in size. The size for a piece is not fixed, but it is somewhere around 1MB.
The protocol always has some number of requests (five) for a sub-piece pipe-lined. When a new sub-piece is download, the client sends a new request. This helps speed things up.

Sub-pieces can be downloaded from other peers.
Two core policies govern the Piece Selection Algorithm.
1️⃣ Strict Policy
Once the BitTorrent client requests a sub-piece of a piece, any remaining sub-pieces of that piece are requested before any sub-pieces from other pieces.
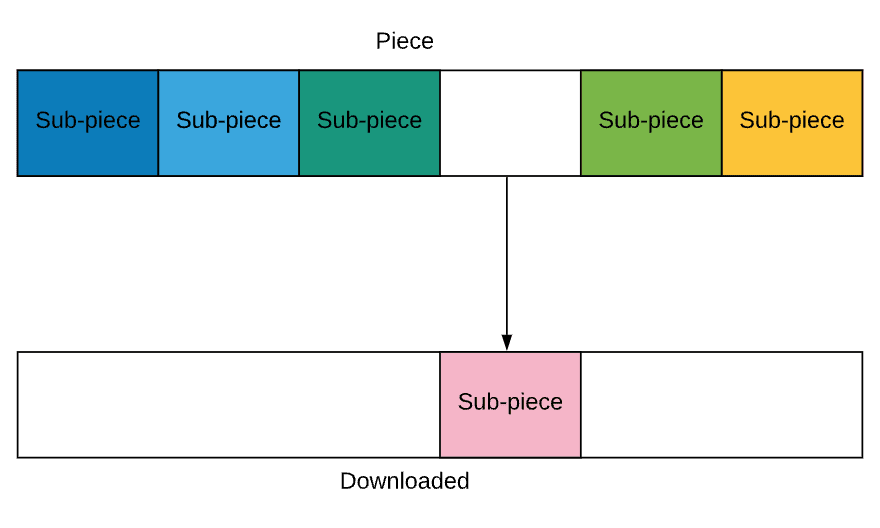
In this image, it makes sense to download all the sub-pieces of this piece first rather than start downloading another piece.
2️⃣ Rarest First
The main policy in BitTorrent is to pick the rarest first. We want to download the piece which the fewest other peers own.
This is so we can make it ‘un-rare’. If only one peer has a piece and they go offline, no one will get the complete file.
A plethora of benefits exist for this policy.
Growing the seed
Rarest first makes sure that we download only new pieces from the seed.
The seed will begin as a bottleneck. The one peer with the file.
A downloader can see what pieces their peers possess, and the rarest first policy will cause us to fetch the pieces from the seed which have not been uploaded by other peers.
Let's visualise this.

The list of nodes (peers) is inter-connected. I cannot draw this as the diagram is unfavourable.
Each arrow towards a sub-piece what that peer has downloaded. We downloaded a sub-piece that no one else has other than the seed. This means this sub-piece is rare.
Our upload rate is higher than that of the seed, so all peers will want to download from us. Also, they would want to download the rarest pieces first, and as we are one of 2 holders of the rarest piece.
When everyone downloads from us, we can download faster from them. This is the tit-for-tat algorithm (discussed later).
Increased download speed
The more peers that hold the piece, the faster the download can happen. This is because we can download sub-pieces from other peers.
Enable uploading
A rare piece is most wanted by other peers and getting a rare piece means peers will be interested in uploading from us. As we will see later, the more we upload, the more we can download.
Most common last
It is sensible to leave the most common pieces to the end of the download. As many peers hold common pieces, the probability of being able to download them is much larger than that of rare pieces.
Prevent rarest piece missing
When the seed dies, all the different pieces of the file should be distributed somewhere among the remaining peers.
3️⃣ Random First Piece
Once we download, we have nothing to upload. We need the first piece, fast. The rarest first policy is slow. Rare pieces are downloaded slower because we can download its sub-pieces from only a few peers.
4️⃣ Endgame Mode
Sometime’s a peer with a slow transfer rate will try to give us a sub-piece. Causing a delay of the download. To prevent this, there is “endgame mode”.
Remember the pipe-lining principle? There are always several requests for sub-pieces pending.

When all the sub-pieces a peer lacks are requested, they broadcast this request to all peers. This helps us get the last chunk of the file.
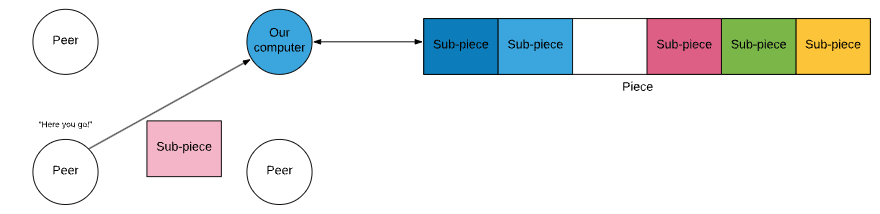
If a peer has the missing sub-piece, they will send that back to our computer.
Once a sub-piece arrives, we send a cancel-message telling the other peers to ignore our request.

🌱 Resource Allocation Using Tit-For-Tat

No centralised resource allocation in BitTorrent exists. Instead, every peer maximises their download rate.
A peer will download from whoever they can. To decide who to upload to, they will use a variant of the "tit-for-tat"algorithm.
The tit-for-tat strategy comes from game theory. The essence is:
"Do onto others as they do onto you"
- On the first move, cooperate
- On each succeeding move do what your opponent did the previous move
- Be prepared to forgive after carrying out just one act of retaliation
🎐 The Choking Algorithm

Choking is a temporary refusal to upload to another peer, but we can still download from them.
To cooperate peers upload, and to not cooperate they “choke” the connection to their peers. The principle is to upload to peers who have uploaded to us.
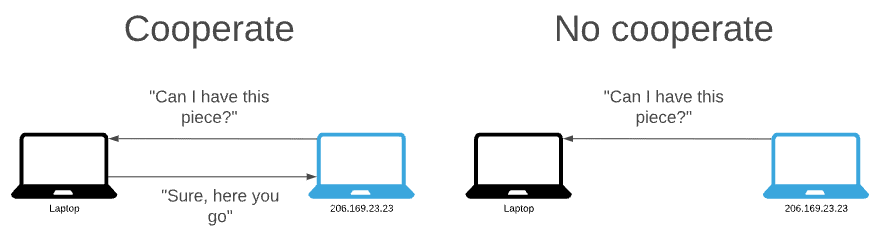
We want several bidirectional connections at the same time and to achieve Pareto Efficiency.
We consider an allocation Pareto Efficient if there is no other allocation in which some individual is better off and no individual is worse off.
Thus the big question, is how to determine which peers to choke and which to unchoke?
A peer always unchokes a fixed number of its peers (the default is 4).
Current download rates decide which peers to unchoke. We use a 20-second average to decide this. Because of the use of TCP (slow-start) rapidly choking and unchoking is bad. Thus, this is calculated every 10 seconds.
If our upload rate is high more peers will allow us to download from them. This means that we can get a higher download rate if we are a good uploader. This is the most important feature of the BitTorrent protocol.
The protocol prohibits many “free riders” which are peers who only download and don’t upload.
For a peer-to-peer network to be efficient, all peers need to contribute to the network.
😎 Optimistic Unchoking

BitTorrent also allows an additional unchoked peer, where the download rate criteria aren’t used.
We call this optimistic unchoking. Checking unused connections aren’t better than the ones in use.
We shift the optimistic unchoke every 30 seconds. Enough time for the upload reaches full speed. Same for the upload. If this new connection turns out to be better than one of the existing unchoked connections, it will replace it.
The optimistic unchoke is randomly selected.
This also allows peers who do not upload and only download to download the file, even if they refuse to cooperate. Albeit, they will download at a much slower speed.
🤕 Anti-Snubbing

What happens if all peers uploading to another peer decide to choke it? We then have to find new peers, but the optimistic unchoking mechanism only checks one unused connection every 30 seconds. To help the download rate recover more, BitTorrent has snubbing.
If a client hasn’t received anything from a particular peer for 60 seconds, it will presume that it has been ‘snubbed’.
Following the mentality of tit-for-tat, we retaliate and refuse to upload to that peer (except if they become an optimistic unchoke).
The peer will then increase the number of optimistic unchokes to find new connections quicker.
🤔 What If We Upload Only?

We see that using the choking algorithm implemented in BitTorrent we favour peers who are kind to us. If I can download fast from them, we allow them to upload fast from me.
What about no downloads? Then it’s impossible to know which peers to unchoke using this choking algorithm. When a download is completed, we use a new choking algorithm.
This new choking algorithm unchokes peers with the highest upload rate. This ensures that pieces get uploaded faster, and they get replicated faster.
Peers with good upload rates are also not being served by others.
🐝 What Is a Tracker?

Trackers are special types of server that help in communication between peers.
Communication in BitTorrent is important. How do we learn what other peers exist?
The tracker knows who owns the file, and how much.
Once a peer-to-peer download has started, communication can continue without a tracker.
Since the creation of the distributed hash table method for trackerless torrents, BitTorrent trackers are largely redundant.
🗼 Public Trackers
These are trackers that anyone can use.
The Pirate Bay operated one of the most popular public trackers until disabling it in 2009, opting only for magnet links (discussed soon).
🔐 Private Trackers
Private trackers are private. They restrict use by requiring users to register with the site. The method for controlling registration is often an invitation system. To use this tracker we need an invitation.
🔢 Multi-Tracker Torrents
Multi-tracker torrents contain multiple trackers in a single torrent file. This provides redundancy if one tracker fails, the other trackers can continue to maintain the swarm for the torrent.
With this configuration, it is possible to have multiple unconnected swarms for a single torrent - which is bad. Some users can connect to one specific tracker while being unable to connect to another. This can create a disjoint set which can impede the efficiency of a torrent to transfer the files it describes.
🧲 Magnet Links - Trackerless Torrents

Earlier, I talked about how the Pirate Bay got rid of trackers and started using trackerless torrents.
When we download a torrent, we get a hash of that torrent. To download the torrent without a tracker, we need to find other peers also downloading the torrent. To do this, we need to use a distributed hash table.
Let's explore Distributed Hash Tables.
🐍 Distributed Hash Tables

Distributed Hash Tables (DHT) give us a dictionary-like interface, but the nodes are distributed across a network. The trick with DHTs is that the node that gets to store a particular key is found by hashing that key.
In effect, each peer becomes a mini-tracker.
Each node (client/server implementing the DHT protocol) has a unique identifier known as the “node ID”. We choose node IDs at random from the same 160-bit space as BitTorrent infohashes.
Infohashesare a SHA-1 hash of:
- ITEM: length(size) and path (path with filename)
- Name: The name to search for
- Piece length: The length(size) of a single piece
- Pieces: SHA-1 Hash of EVERY piece of this torrent
- Private: flag for restricted access
We use a distance metric to compare two node IDs or a node ID and an infohash for “closeness”.
Nodes must have a routing table containing the contact information for a few other nodes.
Nodes know about each other in the DHT. They know many nodes with IDs that are close to their own but few with far-away IDs.
The distance metric is XOR and is interpreted as an integer.
$$distance(A, B) = |A \oplus B |$$
Smaller values are closer.
When a node wants to find peers for a torrent, they use the distance metric to compare the infohash of the torrent with the IDs of the nodes in its routing table or the ID of one node with the ID of another node.
Then they contact the nodes in the routing table closet to the infohash and asks them for contact information of peers downloading the torrent.
If a contacted node knows about peers for the torrent, they return the peer contact information with the response. Otherwise, the contacted node must respond with the contact information of the nodes in its routing table closet to the infohash of the torrent.

The original node queries nodes that are closer to the target infohash until it cannot find any closer nodes. After the node exhausts the search, the client then inserts the peer contact information for itself onto the responding nodes with IDs closest to the infohash of the torrent. In the future, other nodes can easily find us.
The return value for a query for peers includes an opaque value known as the “token.” For a node to announce that its controlling peer is downloading a torrent, it must present the token received from the same queried node in a recent query for peers.
When a node attempts to “announce” a torrent, the queried node checks the token against the querying node’s IP address. This is to prevent malicious hosts from signing up other hosts for torrents.
The querying node returns the token to the same node that they receive the token from. We must accept tokens for a reasonable amount of time after they have been distributed. The BitTorrent implementation uses the SHA-1 hash of the IP address concatenated onto a secret that changes every five minutes and tokens up to ten minutes old are accepted.
📌 Routing Table

Every node maintains a routing table of known good nodes. We use the routing table starting points for queries in the DHT. We return nodes from the routing table in response to queries from other nodes.
Not all nodes we learn about are equal. Some are “good” and some are not. Many nodes using the DHT can send queries and receive responses, but cannot respond to queries from other nodes. Each node’s routing table must contain only known good nodes.
A good node is a node has responded to one of our queries within the last 15 minutes. A node is also good if it has ever responded to our queries and has sent us a query within the last 15 minutes. After 15 minutes of inactivity, a node becomes questionable. Nodes become bad when they fail to respond to multiple queries in a row. Nodes that we see are good are given priority over nodes with an unknown status.
The routing table covers the entire node ID space from 0 to 2160. We subdivide the routing table into “buckets” that each cover a portion of the space.
An empty table has one bucket with an ID space range of min=0, max=2160.
An empty table has only one bucket so any node must fit within it. Each bucket can only hold K nodes, currently eight, before becoming “full.”
When a bucket is full of known good nodes, we may add no more nodes unless our node ID falls within the range of the bucket. The bucket is replaced by two buckets each with half of the old bucket. Nodes from the old bucket are distributed among the new buckets.
For a new table with only one bucket, we always split the full bucket into two new buckets covering the ranges 0..2159 and 2159..2160.
When the bucket is full of good nodes, we simply discard the new node. When nodes in the bucket become bad (if they do) we replace them with a new node.
When nodes are considered questionable and haven’t been since, in the last 15 minutes, the least recently seen node is pinged. The node either responds or doesn’t respond. A response means we move to the next node. We do this until we find a node that fails to respond. If we don’t find any, then the bucket is considered good.
When we do find one, we try one more time before discarding the node and replacing them with a new good node.
Each bucket should maintain a “last changed” property to show how “fresh” the contents are.
When a node in a bucket is pinged and responds, or a node is added to a bucket, or a node is replaced with another node, the bucket’s last changed property is updated.
Buckets are refreshed if the last changed property has not been updated in the last 15 minutes.
🤺 Attacks on BitTorrent

Few attacks on the BitTorrent network exist. Everything is public. Our IP address, what we’re downloading - everything.
Why attack an open network?
Why attack a completely open network?
Only 7 entries are listed on Exploit-DB - a database of known exploits against a service. And most of them relate to specific clients.
The principal attack on the BitTorrent network is to stop piracy. We’ve gone this far without talking about piracy, but it is often synonymous with BitTorrent.
The main attack on BitTorrent is Torrent Poisoning.
Torrent Poisoning
This attack aims to get the IP addresses of peers pirating content or to poison the content in some way.
Madonna’s American Life album release is an example of content poisoning. Before the release, tracks were released of similar length and file size. The tracks featured a clip of Madonna saying:
"What the fuck do you think you're doing?"
Followed by a few minutes of silence.
Here are some methods of poisoning a torrent.
Index Poisoning
The index allows users to locate the IP addresses of peers with the desired content. This method of attack makes searching for peers difficult.
The attacker inserts a large amount of invalid information into the index to prevent users from finding the correct information.
The idea is to slow down the download, by having the peer try to download pieces from an invalid peer.
Decoy Insertion
They insert corrupted versions of a file into the network.
Imagine 500 copies of a file and only 2 of them being the real file, this deters pirates from finding the real file.
Most websites with lists of torrents a voting system. This deters this attack, as the top of searches is filled with non-corrupted files
However, most websites with lists of torrents a voting
This deters this attack, as the top of searches is filled with non-corrupted files.
In GameDevTycoon, the file was released before the initial upload to piracy sites. Unbeknownst to pirates, the file was corrupted. Winning the game is impossible in the pirated version. Everything else was perfect.
🧙🏼♂️ Defence Against the Dark Bittorrent Attack
Most popular torrents are released by individuals or groups who built up a rapport over many years. On private trackers, individuals can be pointed to. Poisoned torrents are quickly labelled and the poster can be banned.
Or, on public trackers, downloading torrents made by trusted groups is preferable. After all, would you prefer to download Ubuntu from the Ubuntu team, or the user xxx-HACKER-ELITE-GHOST-PROTOCOL-xxx?
On public trackers, if a torrent is poisoned the torrent is reported and removed.
The simplest way to defend against a BitTorrent attack is to use an IP address not associated with you. Whether this is through a VPN or some other service.
👋🏻 Conclusion
Here are the things we've learnt:
- What a Torrent Descriptor file is
- How BitTorrent chooses peers
- How BitTorrent chooses pieces
- Tit-For-Tat algorithms
- Trackers
- Attacks on the BitTorrent network
Here are some things you may choose to do:
- Build your own BitTorrent client
- Explore BitTorrent's proposals (BEPs) to learn more about how it works, and what's next for the algorithm
- Read the official BitTorrent specification

Top comments (10)
I'm wondering if people still pirate things now that we have all this paying services. I know that i tried to get photoshop from filelist (which was supposed to be the best) and waited few months. Or if i tried new movies they were all fake. I find the technology good for large file transfers, wetransfer could implement this in their client, instead wasting space on the server it would be nice to send only a link to my local file.
You just need to know where to takes those things, as simple as that. And quite often it's much more easier to pirate it comparing to the legal ways. E.g. I'm living outside the US, hence I don't have 100% of movies on Netflix, more than half of them is simply not available in my country due to copyrights and other legal bs. At the same time I have to pay the same amount of money as Americans do, but get much smaller library. Sounds unfair to me. That's why I use Popcorn Time which is the same Netflix, but free and with no limits.
Depends on where you are from and which search engine you are using. Many countries and ISPs block piracy sites and it is rather difficult to find them with a Google search as Google also blocks them and websites that link to them.
Thank you very much for the detailed writeup @brandonskerritt . I have a question/doubt if you have the time to answer.
Suppose there are a large number of nodes in the network (all of which are can be your peers - and let us assume the best-case scenario - none of them are malicious). Let us say I have a mediocre (or very bad even) upload speed.
I see only two cases in which I can download from other peers and where I am not snubbed- (where I can be co-operated with)
In every other case, I'm going to be snubbed, aren't I?
How can I expect my download to ever get completed this way? Please tell me if I got something wrong here as well :)
Ok, it’s a detailed article; simple BitTorrent. A good point to discuss can be imho: how we can implement this nice technology today, apart from the “downloading large files” ?
Facebook have used in the past BitTorrent (not sure if they still using it) for deploying they backend.
Great article! I've always wondered about BT protocol.
Where can I learn more about writing comm protocols?
I loved this article, thanks!
There is a problem with "Most websites with lists of torrents" also the paragraph below it needs to be removed, looks like an editing mistake.