
Last December, I discovered a small open-source project that became quite popular called pxpipe that started trending on GitHub with a claim that sounds like a billing error: the same Claude Code session that cost $42.21 as plain text cost $4.51 when the bulky parts of the request were converted into PNG images before leaving the machine.
Same model, same task, same answers. The only difference was that the model read most of its context with its eyes instead of its tokenizer. It sounded silly, but it worked: type text, capture it as an image, deliver it to the LLMs so it can be tokenized as text again.
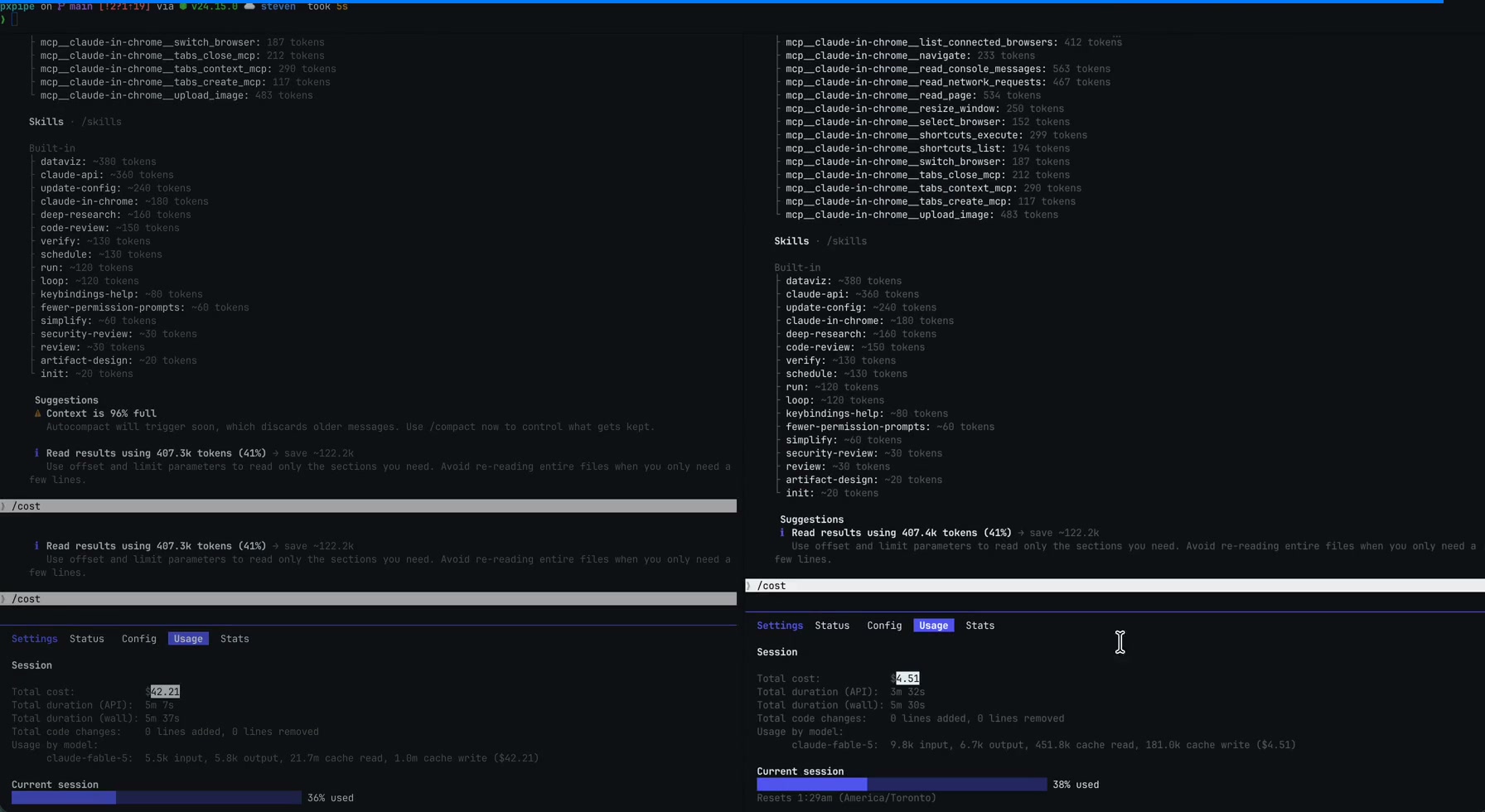
The A/B that made the rounds: same session, $42.21 as text versus $4.51 with imaged context. Source: pxpipe repo (MIT).
That number is worth taking apart, because the mechanism behind it is bigger than one tool. It explains a real cost lever for anyone running agents or long-context pipelines. And it connects to a second question that most people haven't linked to it yet: when an AI system fetches your website in real time, what does it actually see? The answer, increasingly, involves the same vision channel.
The mechanic: images are billed by pixels, not by characters
Every multimodal model prices an image by its dimensions. A 1000x1000 pixel image costs the same number of tokens whether it contains a white void or 5,000 words of dense documentation. The token meter counts pixels. It doesn't care what's painted on them.
Text, on the other hand, is billed character by character. On real Claude Code traffic, dense content like code, JSON and logs runs at roughly one character per text token. The same content rendered into a tightly packed image runs at about 3.1 characters per image token.
That gap is the whole trick. The original example from the pxpipe documentation: a block of roughly 48,000 characters (system prompt plus tool documentation) costs about 25,000 tokens as text. Rendered as a dense PNG, it costs about 2,700 image tokens. Same information, 89% fewer tokens for that block. Simple.

What the model actually receives: 48,000 characters whitespace-minified, reflowed into full rows, with ↵ marks where the original line breaks were. Source: pxpipe repo (MIT).
To make that page readable for a vision encoder, the text goes through three preparation steps. Redundant whitespace gets stripped. The lines get reflowed to fill complete rows of the image, wrapping at columns about 1,928 pixels wide. And small ↵ marks get inserted where the original newlines were, so the structure survives the compaction. A dense page packs around 92,000 characters.
Why pixels beat words at carrying words
The counterintuitive part isn't the billing. It's that the model can actually read this very well.
Sean Goedecke wrote a good analysis of why the math works. A text token is a discrete choice: one option out of a vocabulary of roughly 50,000 entries, which then gets mapped to an embedding vector. You probably know all this. But you probably did not notice that an image token has no such constraint. It can occupy any point in the embedding space, which makes it far more expressive per unit. DeepSeek's research puts a number on it: about 10 text tokens can be recovered from a single image token with near perfect accuracy. This is what shocked me big time: the accuracy!
The idea isn't new, and that's part of what makes the current moment interesting. I saw it in a post, tried it, and have used it since. People, as we do, have been pasting screenshots into multimodal models for years, and the standing objection has always been the same: vision encoders weren't reliable enough at reading small, dense type, so nobody sane would route production context through them. What changed between 2024 and now is the encoders.
When DeepSeek published its optical compression results, and pxpipe shipped its evals, the conversation moved from "would this even work" to "here's the exact ratio where it stops working". That's the difference between a party trick and an engineering option.
Here's how the main providers actually count image tokens today:
| Provider | How an image is priced | A 1000x1000 px image |
|---|---|---|
| Anthropic (Claude) | 28x28 pixel patches, one visual token each: ⌈w/28⌉ x ⌈h/28⌉ | 1,296 tokens |
| OpenAI (high detail) | 85 base tokens + 170 per 512x512 tile after rescaling | 765 tokens |
| Google (Gemini) | 258 tokens flat if ≤384 px, otherwise 258 per 768x768 tile | 1,032 tokens |
On current Claude models (Fable 5, Opus 4.7 and 4.8), an image is capped at 4,784 visual tokens with a long edge of up to 2,576 pixels. The pxpipe render width of 1,928 pixels sits comfortably under that ceiling. None of this is an accident.
The fine print per provider
The details matter more than the headline formula, because each provider hides different tradeoffs in them. This is what makes life interesting, isn't it?
Anthropic's older models capped images at 1,568 pixels on the long edge and 1,568 visual tokens. Anything larger got downscaled before processing, which silently capped your cost and your resolution at once. You'll still find the legacy approximation "tokens equals width times height divided by 750" in older writeups. The patch math replaced it: 28 by 28 pixels per visual token, ceiling-rounded on each axis. For a 1000x1000 image both formulas land within 3% of each other, which is why the old rule survived so long.
OpenAI works in two steps: the image gets scaled to fit inside a 2048 pixel square, then its shortest side gets brought to 768 pixels, and only then does the 512 pixel tiling apply. A "low detail" flag skips all of it for a flat 85 tokens, which is useless for reading text but fine for "is this a cat".
Google's approach is the bluntest: anything up to 384 pixels on both sides is 258 tokens, period. Beyond that, 768 pixel tiles at 258 each.
Three consequences follow. First, the optimal render size is provider-specific, so a pipeline tuned for Claude wastes money on Gemini. Second, resizing before upload is your decision to make, and making it consciously beats letting the API downscale for you. Third, per-image caps mean very long documents want several medium-density pages rather than one gigantic one. pxpipe packs about 92,000 characters per page and simply emits an array of PNGs when the content overflows.
![]()
The idea in one picture: identical context, 90 tokens as text, 50 as an image. Source: "Text or Pixels? It Takes Half" (arXiv 2510.18279), CC BY 4.0.
What the research says
Two papers from October 2025 put this on solid ground.
"Text or Pixels? It Takes Half" tested the idea systematically on GPT-4.1-mini and Qwen2.5-VL-72B. The setup was careful: text typeset with LaTeX at 300 DPI, adaptive font sizing targeting a 0.8 fill ratio, resolutions from 600x800 to 750x1000 pixels. Rendering long text as images achieved roughly 2:1 compression (38% to 58% fewer decoder tokens) while keeping accuracy within 3 points of the text-only baseline. On needle-in-a-haystack retrieval the imaged arm scored 97% to 99%; on CNN/DailyMail summarization it beat dedicated compression baselines like LLMLingua-2 at matched ratios. And there was a bonus nobody expected: on Qwen2.5-VL-72B, the shorter decoder sequence made end-to-end inference 25% to 45% faster. Cheaper and quicker, from the same trick.
DeepSeek-OCR, published the same month, went further and mapped the limits. Their "contexts optical compression" work shows that while the ratio of text tokens to vision tokens stays under 10x, decoding precision holds at 97%. Push to 20x compression and precision drops to around 60%. The curve between those two points is the price list of this whole technique.
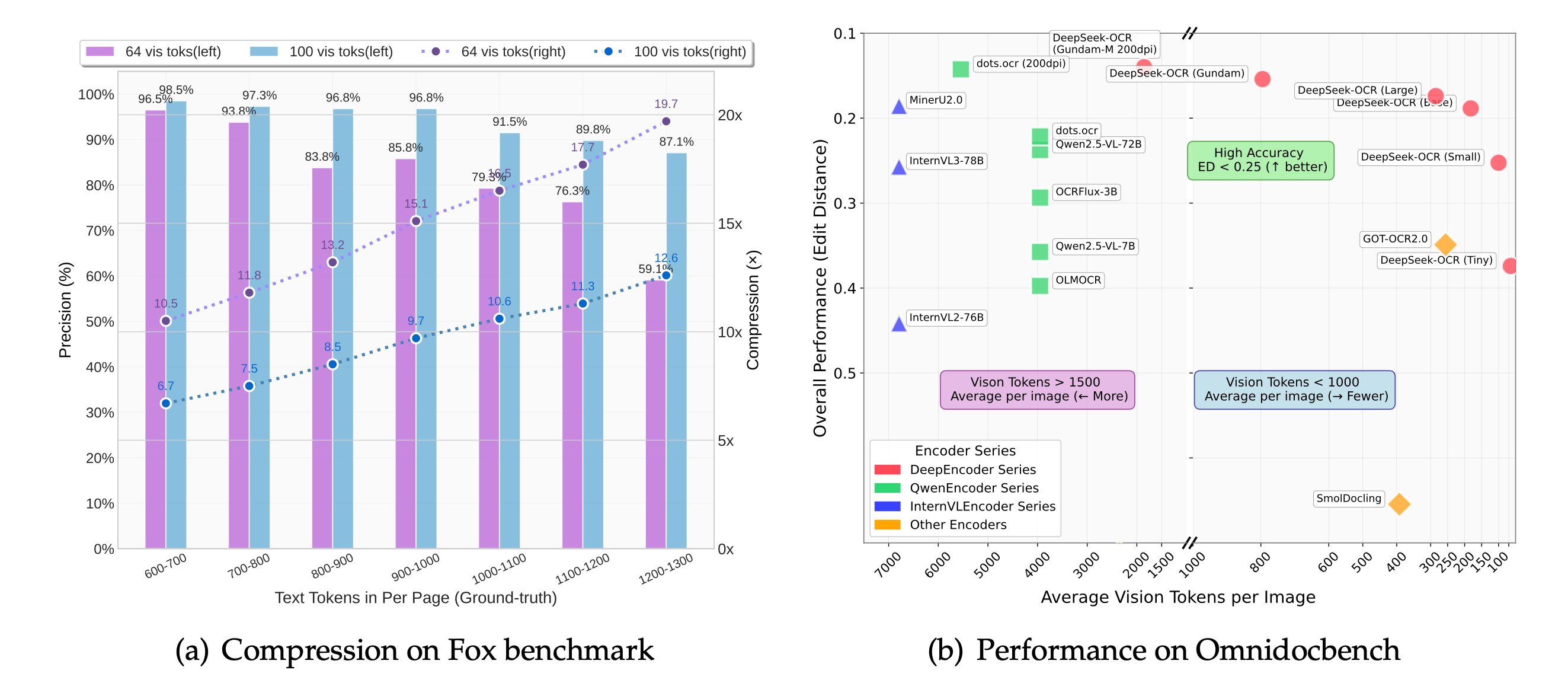
The boundary of the technique: precision holds near 97% below 10x compression, then degrades. On OmniDocBench, 100 vision tokens per page beat systems spending 256, and under 800 beat systems spending 6,000+. Source: DeepSeek-OCR (arXiv 2510.18234), CC BY 4.0.
The efficiency numbers are hard to ignore. DeepSeek-OCR reads a document page with 100 vision tokens and beats GOT-OCR2.0, which spends 256 per page. With fewer than 800 it outperforms MinerU2.0, which averages more than 6,000. In production, DeepSeek uses this to generate LLM training data at over 200,000 pages per day on a single A100-40G.
The paper's discussion section contains the most science-fiction idea in this whole space: optical memory. Store a conversation's older history as images at progressively lower resolution, so distant context literally fades the way human memories do. More on that at the end.
Inside a production pipeline
pxpipe is the most instructive implementation to read because it publishes its evals and its failure cases. It runs as a local proxy between your client and the Claude API. Requests pass through byte-identical except for three categories of content, each behind a profitability gate: tool results above roughly 6,000 characters of dense content, older conversation turns behind the live tail, and the static system prompt plus tool documentation slab.
Two design rules matter more than the rest. Recent turns always stay as text. And the static prefix is preserved untouched, because breaking prompt caching would eat the savings.
The measured results, from the project's own benchmark tables:
| Test | Text baseline | With imaged context |
|---|---|---|
| Novel arithmetic, Claude Fable 5 (n=100) | 100/100 | 100/100, with 38% fewer tokens |
| Gist recall A/B (n=98) | 98/98 | 98/98 |
| State tracking (n=18) | 18/18 | 18/18 |
| SWE-bench Lite (n=10) | 10/10 | 10/10, requests 65% smaller |
| 12-character hex recall, Opus (n=15) | 15/15 | 0/15 |
Look at that last row again. We'll get back to it.
On SWE-bench Pro, the harder agentic benchmark, the imaged arm resolved 14 of 19 tasks against 15 of 19 for plain text, with requests 60% smaller and 18 of 19 runs agreeing on the final verdict. That's the honest shape of the tradeoff on difficult work: a small accuracy tax on the hardest problems, bought at more than half the price.
End to end, over a snapshot of 13,709 real requests, the bill dropped 59%, from $100 to about $41. Traces where compression applied heavily ran 70% to 74% cheaper.
Two operational costs come with it. Encoding PNGs adds latency on large requests, noticeable when your pipeline is latency-sensitive rather than cost-sensitive. And the technique is battle-tested on ASCII and Latin-1 content; CJK text works but the project handles it conservatively, with less aggressive packing. If your context is mostly Chinese or Japanese, your compression ratio will be worse than the headline numbers.
When imaging your context adds, and when it makes it worse
Every writeup of this technique that only quotes the savings is doing you a disservice. Be aware, the method is lossy, and it fails in a specific, nasty way.
Exact recall of short strings breaks first. In pxpipe's test, Opus recalled 12-character hex strings from imaged content 0 times out of 15. The newer Fable 5 managed 13 of 15. And the failures aren't errors you can catch: the model confabulates a plausible value with full confidence instead of saying it can't read it. The project documents a real case of a name being confidently misremembered from imaged history.
It's also model-dependent. The technique works because current frontier vision encoders (Claude Fable 5, GPT 5.6) read dense text almost perfectly. Opus 4.7 and 4.8 misread around 7% of the time, which is why pxpipe keeps them opt-in. A model without a strong text-reading encoder turns your compressed context into noise.
So imaging adds when the content is bulk context for reasoning (code, docs, logs, old conversation turns). It subtracts when any byte matters exactly. Hashes, API keys, IDs, phone numbers and anything you'll need to quote back verbatim should stay as text, always.
One more caveat, and it's the strategic one: the arbitrage moveswithout warning. When Anthropic shipped Opus 4.7, the maximum native image resolution jumped from 1,568 to 2,576 pixels on the long edge, and typical screenshots went from around 1,558 tokens to 4,739. The same image, three times the cost, in one release. The lesson isn't "use the trick".
The lesson is: understand your provider's per-pixel economics and measure them, because they change without asking you.
Try it in ten minutes
If you run Claude Code, the experiment costs two commands:
npx pxpipe-proxy
ANTHROPIC_BASE_URL=http://127.0.0.1:47821 claude
A dashboard at 127.0.0.1:47821 shows every conversion and the tokens saved. The proxy only touches allowlisted models; everything else passes through byte-identical, and you can kill it entirely with PXPIPE_MODELS=off.
For your own pipelines, the same machinery is available as a library:
import { renderTextToPngs, transformAnthropicMessages } from "pxpipe";
const imgs = await renderTextToPngs(bigToolResultText);
const { body, applied } = await transformAnthropicMessages({
body: requestBytes,
model: "claude-fable-5",
});
Before trusting any number, measure your own baseline. Anthropic's count_tokens endpoint is free, and comparing imaged versus plain requests on your real traffic takes an afternoon. My checklist for anyone adopting this:
- Gate by density. Prose compresses poorly; code, JSON and logs compress well.
- Keep the live tail of the conversation as text, always.
- Keep anything byte-exact (hashes, keys, IDs, amounts) out of the imaged path.
- Re-measure after every model release. The Opus 4.7 repricing tripled image costs overnight.
- Log what was compressed. When a confabulation shows up, you'll want to know what the model was reading.
The part almost nobody connects: this is also how AIs read your website
Everything above treats text-as-image as a cost trick you apply to your own requests. Now flip the direction. When ChatGPT, Claude, Perplexity or an AI browser agent fetches a page from your site in real time, what do they see?
It turns out your site doesn't have one AI reader. It has three, and they disagree.
Your website has three AI readers now: the crawler, Google, and the agent. None of them see the same page.

The same page, three readings: raw HTML for crawlers, a rendered page for Google, pixels for agents.
Reader one: the crawlers. Each AI company runs three families of bots against your site. A training crawler (GPTBot, ClaudeBot) collects content for future models. A search-index bot (OAI-SearchBot, Claude-SearchBot) feeds the assistant's search layer. And a user-triggered fetcher (ChatGPT-User, Perplexity-User) hits your page live, in the seconds between a user's question and the answer. That last one is the "real time" in real-time AI answers.
As of mid 2026, none of them execute JavaScript. Not one, in any of the three families. Vercel's analysis of production traffic found GPTBot downloads JavaScript files about 11.5% of the time (ClaudeBot 23.8%) and never runs them. They fetch the raw HTML, extract what's there, and move on. No second pass, no rendering queue. If your content only exists in the DOM after client-side rendering, it doesn't exist for these systems.
Reader two: Google, the exception. Gemini and AI Overviews inherit Googlebot's infrastructure, and Googlebot renders JavaScript. Google's Martin Splitt has confirmed it. The practical consequence is strange and very real: the same page can be fully visible to Google's AI surfaces and invisible to ChatGPT, Claude and Perplexity at the same time. If your brand shows up in AI Overviews but never in ChatGPT answers, check how much of your content depends on JavaScript before blaming the model.
Reader three: the agents. Agentic browsers like OpenAI's Atlas (powered by their Computer-Using Agent) and Perplexity's Comet read the fully rendered page, through a mix of accessibility-tree snapshots, DOM parsing and screenshots sent to a vision model. This is where the first half of this article loops back: agents are reading web pages through the same vision channel, with the same economics and the same degradation curve. DeepSeek's numbers apply here too. A clean, well-structured page reads at 97%. A dense, cluttered one slides toward the 60% end, and the agent fills the gaps with confident guesses.
There's a fourth pattern worth knowing about on the retrieval side. ColPali (ICLR 2025) showed that for document search, skipping OCR entirely and embedding page images directly beats the classic extract-and-chunk pipeline: 0.81 versus 0.66 NDCG@5, while indexing pages in 0.39 seconds instead of 7.22. The layout, tables and figures that text extraction destroys turn out to carry retrievable meaning. Visual structure is information.
What this means if you publish content
If you own a website that you'd like AI systems to read correctly, the three-reader split translates into checkable work:
-
Serve the substance in raw HTML. Server-side render or prerender anything you want crawlers and live fetchers to see: prices, specs, FAQs, comparisons. The test takes one command:
curlyour page and search the response for your key facts. If they're not in that output, two of your three readers can't see them. - Don't let AI Overviews lull you. Google renders your JavaScript, so decent AIO visibility proves nothing about ChatGPT, Claude or Perplexity. Audit them separately.
- Treat your accessibility tree as an API. Agents from OpenAI and Perplexity prioritize ARIA roles and labels before falling back to vision. Semantic HTML and honest labels are no longer just an accessibility checkbox; they're how machines operate your interface.
- Design for the 97% end of the curve. Dense, cluttered, low-contrast pages push a vision-reading agent toward the degradation zone where it starts guessing. Clear hierarchy and legible text sizes now serve two audiences.
- Keep critical facts unambiguous. An agent misreading a price from a screenshot fails exactly like the hex test: silently and confidently.
What we're building on top of this
pxpipe proved the mechanism on one developer's traffic. The question that interests us at 498A is what it does at audit scale, and it's turning into two work lines.
The first is about simulation economics. A GEORadar brand study runs between 3,000 and 30,000 personalized prompts against five LLMs plus Google's AI Overviews. Every one of those calls carries a slab of static context: persona definitions, market instructions, product catalogs, scoring rubrics. It repeats thousands of times per study, it's token-dense, and none of it needs byte-exact recall. That's exactly the profile the compression math favors. So we're testing optical compression of that static slab on our own simulation engine. The public ratios say dense content compresses about 3x; what we're measuring is what that buys back on a full study: more prompts per budget, more engines per prompt, or the same audit at a fraction of the cost. Until our numbers are in, it stays labeled what it is, an experiment.
The second line points the other way. Our audits interrogate models about brands through the text channel, and the technical side already checks what crawlers can fetch. Nobody is auditing the third reader yet. We're prototyping exactly that: feeding brand pages to vision models the way agentic browsers see them, screenshot plus accessibility tree, and scoring what survives the trip. Which facts does a vision reader actually extract? At what layout density does the page slide toward the confabulation zone DeepSeek measured? For S.A.M., our semantic alignment tool, this extends validation to a second channel: a claim now has to survive as text for the crawler and as pixels for the agent. Semantic alignment used to be a property of your copy. It's becoming a property of your layout too.
I wrote about the text side of that machinery in how LLMs search, retrieve and answer with real-time web data. The vision side is newer, and most sites haven't been checked against it even once. That gap is the opportunity.
Text that fades like memory
Back to DeepSeek's closing idea, because it reframes everything. If text rendered as an image is cheap and readable, then old context doesn't have to be summarized or deleted. It can be stored as pictures that lose resolution over time. Yesterday's conversation at high DPI. Last month's at half. Last year's as a blurry thumbnail that still preserves the gist.
That's not a billing hack anymore. That's an architecture for artificial memory that behaves like the biological kind, built out of the same mechanism that turns $42.21 into $4.51. And for anyone running simulations at audit scale, it's also the difference between sampling a market and saturating it.
The pipeline between language models and text keeps getting stranger. We spent years teaching machines to read. Now the cheapest way to hand text to a machine built on language is, more and more often, to show it a picture.
Technical sources consulted
- teamchong: pxpipe, local proxy rendering request context as PNGs, benchmark tables and production cost traces (MIT).
- Wei et al., DeepSeek-AI: DeepSeek-OCR: Contexts Optical Compression, compression-precision curves, DeepEncoder architecture and the optical memory proposal (CC BY 4.0).
- Li et al.: Text or Pixels? It Takes Half, token efficiency of visual text inputs in multimodal LLMs (CC BY 4.0).
- Faysse et al.: ColPali: Efficient Document Retrieval with Vision Language Models, ICLR 2025, visual document retrieval and the ViDoRe benchmark.
- Anthropic: Vision documentation, 28x28 pixel patches, per-tier resolution caps and token cost tables.
- Google AI for Developers: Understand and count tokens, Gemini image tokenization by 768x768 tiles.
- OpenAI: Vision guide, base plus per-tile image token pricing.
- Vercel: The rise of the AI crawler, production measurements of GPTBot, ClaudeBot and PerplexityBot JavaScript behavior.
- Stan Ventures: Gemini AI renders JavaScript like Googlebot, Martin Splitt's confirmation of Gemini's rendering infrastructure.
- Sean Goedecke: Should LLMs just treat text content as an image?, discrete versus continuous token expressiveness.
- Sinaptik AI: PixelPrompt, alternative open source implementation of text-to-image context compression.

Top comments (0)