
The Scalable Webhook
This is an example CDK stack from CDK Patterns to deploy The Scalable Webhook stack described by Jeremy Daly here - https://www.jeremydaly.com/serverless-microservice-patterns-for-aws/#scalablewebhook
An advanced version of this pattern was talked about by Heitor Lessa at re:Invent 2019 as Call me, “Maybe” (Webhook)
Desconstructing The Scalable Webhook
If you want a walkthrough of the theory, the code and finally a demo of the deployed implementation check out:
High Level Description
You would use this pattern when you have a non serverless resource like an RDS DB in direct contact with a serverless resource like a lambda. You need to make
sure that your serverless resource doesn't scale up to an amount that it DOS attacks your non serverless resource.
This is done by putting a queue between them and having a lambda with a throttled concurrency policy pull items off the queue and communicate with your
serverless resource at a rate it can handle.

NOTE: For this pattern in the cdk deployable construct I have swapped RDS for DynamoDB.
Why? Because it is significantly cheaper/faster for developers to deploy and maintain, I also don't think we lose the essence of the pattern with this swap given we still do the pub/sub deduplication via SQS/Lambda and throttle the subscription lambda. RDS also introduces extra complexity in that it needs to be deployed in a VPC. I am slightly worried developers would get distracted by the extra RDS logic when the main point is the pattern. A real life implementation of this pattern could use RDS MySQL or it could be a call to an on-prem mainframe, the main purpose of the pattern is the throttling to not overload the scale-limited resource.
Pattern Background
When people move to the cloud (especially serverless) they tend to think that this means their applications are now infinitely scalable:
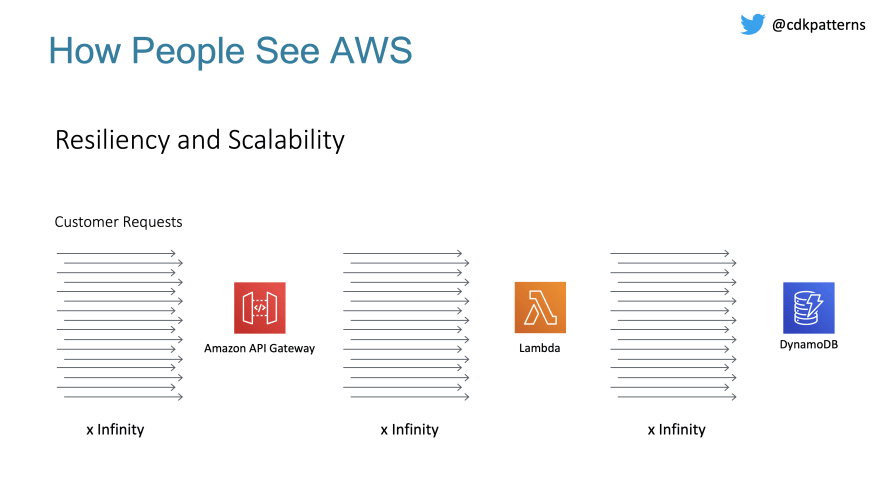
For the right reasons this just isn't true. If any one person's resources were infinitely scalable then any one person could consume the whole of AWS no matter how scalable the platform.

If we weren't using DynamoDB, we would need to know the max connections limit configured for our instance size:


We need to slow down the amount of direct requests to our DB somehow, that is where the scalable webhook comes in:

We can use SQS to hold all requests in a queue as soon as they come in. Again, SQS will have limits:
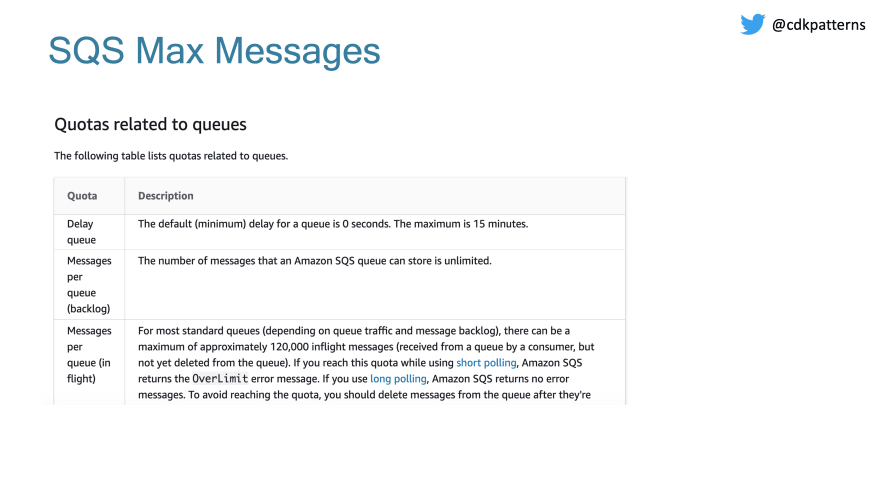
120,000 in flight messages with an unlimited backlog I think will be effective enough as a buffer.
Now we have our messages in a queue but we need to subscribe to the queue and insert the records into the DB. To do this we create a throttled lambda where we set the max number of concurrent executions to whatever scale we are happy with. This should be less than the max connections on our DB and should take into account any other Lambdas running in this account.
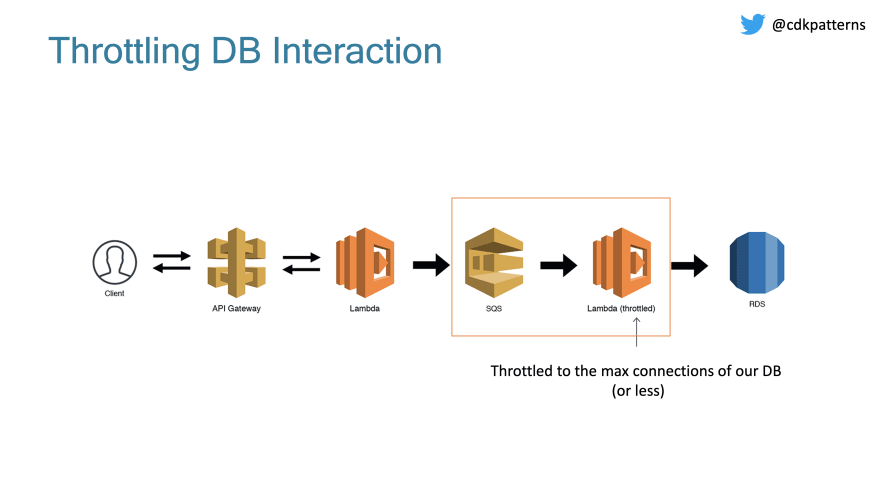
One final improvement that we could make if implementing this in a production system is to delete the Lambda between the API Gateway and SQS. You can do a direct integration which will reduce costs and latency:

If you want an AWS managed service to try and help with this scalability problem you can check out AWS RDS Proxy which is in preview


Top comments (0)