The original post was published here
Handling Slow/Fast Servers in Micro Services with NodeJS
In a micro services architecture we have different small servers, which handles some tasks and hands over the data to the next server in the chain for further processing.
This creates 2 interesting problem:
What if the Server which has to handle data is slow in processing the data , than the server node which is producing the data?
What if the producer produces huge payloads.
We can handle the above situations efficiently using built in NodeJS Streams and Backpressure.
Node Streams gives us the ability to send data in chunks to the server instead of sending the whole payload. It keeps the memory in control and helps us write fast servers.
Also stream have built in support to handle Backpressure.
When a Backpressure is applied the consumer(server) basically notifies the producer(server), that it is currently overloaded and stream takes care not to send more data to the server.
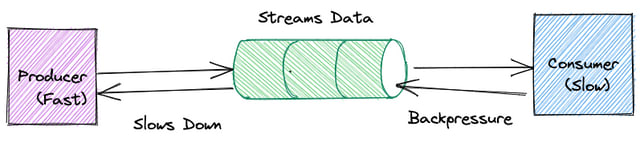
Let's check how this works with a code example.
We will first write a producer which will produce large JSON payloads.
Producer/Client
const data = [
{
_id: "6192c126465ae155e3d6f2f9",
isactive: true,
balance: "2,125.46",
picture: "http://placehold.it/32x32",
age: 30,
eyecolor: "brown",
name: "aguilar ruiz",
gender: "male",
company: "vetron",
email: "aguilarruiz@vetron.com",
phone: "+1 (830) 508-2418",
address: "451 scott avenue, vincent, american samoa, 4990",
about:
"consequat voluptate laborum magna elit est dolor qui non. non sunt ad labore nulla anim ipsum tempor do fugiat eu ipsum fugiat cillum. laboris officia est lorem quis sit ad consequat ullamco enim occaecat nisi. in ipsum reprehenderit labore laboris reprehenderit dolore eiusmod ut dolore eiusmod. irure in reprehenderit adipisicing exercitation occaecat eu ullamco voluptate laborum ex in minim voluptate incididunt. reprehenderit aute tempor enim enim cupidatat anim aliquip cupidatat nisi et amet. do quis cillum nostrud proident sit eiusmod aliqua nisi incididunt magna.\r\n",
registered: "2019-12-10t09:52:42 +05:00",
latitude: 30.443211,
longitude: 168.052318,
tags: ["aliquip", "nulla"],
friends: [
{ id: 0, name: "shauna juarez" },
{ id: 1, name: "alvarado bright" },
{ id: 2, name: "mendez miller" },
],
greeting: "hello, aguilar ruiz! you have 8 unread messages.",
favoritefruit: "strawberry",
},
];
async function* genData() {
for (let i = 0; i < 50000; i++) {
let chunk = Array(50).fill(data[0]);
// chunk._id = i;
let body = JSON.stringify(chunk);
let dataBytes = Buffer.byteLength(body);
let buffer = Buffer.alloc(4 + dataBytes);
buffer.writeUInt32BE(dataBytes);
buffer.write(body, 4);
yield buffer;
}
}
Above , we have some sample JSON data , and an async generator which is generating a large payload out of the sample around 50,000 times
let chunk = Array(50).fill(data[0]);
The rest of the code converts the Payload into Buffer and writes the length of the Payload as the 1st 4 bytes of the buffer. We will use this information to get the correct payload in the server.
The built-in http module of Node is an implementation of Stream under the hood, so we will use it to stream the generated data to server.
const source = Readable.from(genData());
let options = {
method: "POST",
hostname: "localhost",
port: 3000,
path: "/",
headers: {
"Content-Type": "application/json",
},
};
const request = http.request(options, (res) => {
console.log("Request Done");
});
request.on("drain", () => {
drainEventCalled++;
if (drainEventCalled % 500 === 0) {
process.nextTick(() => console.log("Drained Buffer"));
}
});
setInterval(() => {
console.log("rss client::", process.memoryUsage().rss / 1024 / 1024);
}, 10000);
pipeline(source, request, (err) => {
if (err) {
console.log(err);
return;
}
console.log("Done. Drain Event Called: ", drainEventCalled);
});
Let's take a look into what we are doing here
- We create a Readable stream from our generator function
- We then create the
requestobject which extends Node Streams. - Finally , we use the built-in
pipelinefunctionality of stream library to stream data to the server from the source(generator function). Thepipelineunder that hoods takes care of streaming data from one readable source to a writeable destination and abstracts away handling of backpresure and backpressure related errors. - We want to also measure the memory usage of the Source Server and Node provides the builtin
process.memoryUsage().rssfor that. Here is the official documentation of Resident Set Size - The
drainevent is called whenever the sources buffer is cleared and the data is sent to the consumer server. Remember we are sending data in chunks to the server and when a backpressure is applied the source server will simply stop filling up its buffers with more data and WAIT.
That is all for the producer/client side of things.
We will take a look at the Server Next !
Consumer/Slow Server
In the server we want to parse the binary data received in chunks in the correct order and then process them, we will simulate the processing using a promise which will block the server for sometime.
const server = http.createServer((req, res) => {
let dataToProcess = [];
let jsonReader = new JSONReader();
const flushAndProcess = () => {
return new Promise((resolve) => {
if (dataToProcess.length % 10000 === 0) {
setTimeout(() => {
console.log("Flushing Data and Processing");
dataToProcess = [];
resolve();
}, 3000);
} else {
resolve();
}
});
};
jsonReader.JSONEmitter.on("json", (jsonData) => dataToProcess.push(jsonData));
req.on("close", () => console.log("Closed"));
req.on("end", () => {
console.log("Request End.. Data processed", jsonReader.parsedJSONCounter);
res.end();
});
// req.on("data", (chunk) => console.log("data", chunk.toString()));
req.on("readable", async () => {
await flushAndProcess();
jsonReader.makeJSONFromStream(req);
});
});
server.listen(3000, () => {
setInterval(() => {
console.log("rss", process.memoryUsage().rss / 1024 / 1024);
}, 1000);
console.log("Listening on 3000");
});
Above , we create a the Server and then listen for the readable event on the req stream.
For streams we have
- Flowing Mode and
- Paused mode
When we listen to the readable event we are basically reading the stream in paused mode, this gives us better control in reading the incoming data of the stream.
If we wanted the stream to be in flowing mode we would have listened to the data event.
Whenever a chunk of data is available in our buffers the readable event will be raised and we would then read the data from the Buffers and do something with it.
In this case we have a helper class
let jsonReader = new JSONReader();
which will process bytes of data and then store it in a temporary array.
Whenever our temporary array has 10000 records we start processing the data and basically that pauses the stream.
await flushAndProcess();
Lets look at how we can process the binary data and process it into valid JSON.
class JSONReader {
bytesToRead = 0;
chunks = [];
parsedJSONCounter = 0;
JSONEmitter;
constructor() {
this.JSONEmitter = new EventEmitter();
}
setBytestoRead(len) {
this.bytesToRead = len;
}
reset() {
this.bytesToRead = 0;
this.chunks = [];
}
parseJSON() {
try {
let buffer = Buffer.concat(this.chunks);
let parsedJSON = JSON.parse(buffer);
this.parsedJSONCounter++;
return parsedJSON;
} catch (error) {
console.error("Error parsing JSON String", error);
}
}
readBytes(inStream) {
let body = inStream.read(this.bytesToRead);
if (body) {
this.chunks.push(body);
const jsonData = this.parseJSON();
this.reset();
this.JSONEmitter.emit("json", jsonData);
return;
}
body = inStream.read();
if (!body) return;
this.chunks.push(body);
this.bytesToRead = this.bytesToRead - Buffer.byteLength(body);
}
makeJSONFromStream(inStream) {
if (this.bytesToRead > 0) {
this.readBytes(inStream);
}
let lenBytes;
while (null !== (lenBytes = inStream.read(4))) {
this.bytesToRead = lenBytes.readUInt32BE();
this.readBytes(inStream);
}
}
}
- Read the first 4 bytes of the stream and get the length of the JSON payload(the length was set in the client).
Read the length of data from the stream
let body = inStream.read(this.bytesToRead);We need to keep in mind, that for larger payloads , the whole payload might not yet have been received. In that case we simply read all the data of the buffer, calculate the length of bytes read and decrement that amount from the total length of the payload.
this.bytesToRead = this.bytesToRead - Buffer.byteLength(body);When the next chunk arrives we read the rest of the remaining length of the buffer and continue this process , till we have read the complete valid payload.
Once the payload has been completely read we convert the data to a valid json and store it in our internal array.
As in the client/producer side we keep track of the memory consumption in the server.
Finally we listen to the end event of the stream in which case we can just respond to the caller that request has been processed and a response is sent.
Final Thoughts
The above experiment gives us an idea of how we can handle different sizes of requests with Streams in NodeJS.
It also showcases one way of handling servers which might auto throttle using built in NodeJS streams and backpressure.
Also as expected if we run the server and then the client we can see the memory footprint of both system is pretty much kept low during the whole process.
The complete code is available here
Streaming Server and Client - Watch Video


Top comments (0)